



CapNet:利用无线传感器网络实现数据中心功耗封顶
1 引言
现代企业数据中心不断扩大规模,通过增加服务器数量来满足日益增长的云计算和存储需求。这些大规模数据中心的持续、低成本和高效运行在很大程度上依赖于其管理网络和系统。典型的数据中心管理(DCM)系统负责处理物理层功能,例如服务器的开关机、主板传感器遥测、冷却管理和电源管理。更高层次的管理功能,如系统重映像、网络配置、(虚拟)机器分配以及服务器健康监控[17, 34]依赖 DCM 才能正常工作。即使服务器没有正常工作的操作系统或数据网络未正确配置,也要求 DCM 能够正常运行[1]。
在当今的数据中心中,DCM通常被设计为与生产数据网络[18](即,带外)并行运行,结合以太网和串行连接以提高冗余性。每个机架或机架组都配备一个集群控制器,这些控制器通过以太网连接到中央管理服务器。在集群内部,每台服务器的主板上都有一个微控制器(基板管理控制器(BMC)),通过点对点串行连接与集群控制器相连。出于冗余考虑,每台服务器通常连接到两个不同故障域上的独立控制器,从而确保在发生任何单点故障时至少有一种方式可以访问该服务器。然而,这种架构无法良好扩展。随着数据中心中服务器数量的增加,管理网络的总体成本呈超线性增长。同时,跨机架的大规模布线增加了人为错误的风险,并延长了服务器部署延迟。
本文提出了一种在机架粒度上进行数据中心管理网络的不同方法,通过使用低成本无线链路替代串行电缆连接。低功耗无线传感器网络技术(如 IEEE 802.15.4)在此应用中具有内在优势。最近,美国联邦能源管理计划也推荐采用无线传感器技术作为数据中心管理、实时监控以及优化能源使用的经济高效方案[16]。
- 成本 :低功耗无线电(即 IEEE 802.15.4)的单个成本低于有线替代方案,并且其成本随服务器数量线性增长。
- 嵌入式 :这些无线电设备物理尺寸小,因此可以集成到服务器主板上,以节省宝贵的机架空间。
- 可重构性 :无线传感器网络可通过广播介质实现自配置和自修复,从而避免人为布线错误。
- 低功耗 :借助小型板载电池,基于无线的 DCM 即使在机架电源故障时也能依靠电池继续运行,提供监控能力。
然而,无线DCM能否满足数据中心运行的高可靠性要求并不明显,原因有多个。机架内的大量的金属板、电子设备和电缆可能会完全屏蔽射频信号传播。此外,尽管DCM上的典型流量较低,但紧急情况可能需要实时处理,这可能需要设计新协议。
功率封顶是施加实时要求的紧急事件的一个示例。如今,数据中心运营商通常通过在一个电路上安装超过其额定数量的服务器,来实现电力基础设施的超额订阅。其原理在于,服务器很少会同时达到峰值功耗。通过超额订阅,相同的数据中心基础设施可以容纳比以往更多的服务器。在罕见事件中,当所有服务器的总功耗超过其电路的功率容量,一些服务器必须通过动态频率和电压调节(DVFS)或CPU降频来减慢速度(即功耗被限制),以防止断路器跳闸。每种超额订阅幅度都关联一个跳闸时间,该跳闸时间是一个截止时间,必须在此之前执行功耗限制以避免断路器跳闸。
本文做出了以下关键贡献。
我们研究了使用低功耗无线技术进行DCM的可行性和优势。在两个数据中心中,我们通过实证评估了服务器机架中IEEE 802.15.4的链路质量,结果表明整体数据包接收率较高。
- 我们进一步深入研究了功率封顶场景,并设计了CapNet,一种用于无线功耗封顶的网络,该网络采用事件驱动的实时控制协议,通过无线DCM实现功率上限控制(该成果最初作为会议论文发表[57])。该协议利用分布式事件检测来减少定期轮询网络中所有节点的开销。因此,在没有紧急情况时,网络吞吐量可供其他管理任务使用。当检测到潜在的功率激增时,控制器会采用滑动窗口和冲突避免方法,从所有服务器收集功率测量数据,然后向其中一部分服务器发送功耗限制命令。
- 我们在一个数据中心部署并评估了CapNet。利用服务器功耗轨迹,在该数据中心的 480台服务器的集群上的实验结果表明,CapNet能够满足功率封顶的实时要求。它展示了在实现类似有线DCM的功率封顶方面的可行性与有效性,且成本仅为有线方案的一小部分。
在本文的其余部分,第2节描述无线DCM的动机。第3节概述CapNet设计。第4节介绍CapNet协议。第5节描述CapNet的容错性。第6节展示实验结果。第7节描述未来工作。第8节回顾相关工作。第9节为结论。
2 无线DCM(CapNet)的必要性
有线DCM解决方案(图1)在数据中心中的局限性是多方面的。它是一种固定有线网络,因此随着服务器数量的增加而扩展性差。基于串行线路的点对点拓扑结构在连接更多设备时会产生额外成本。此外,随着近年来服务器密度的增加,此网络还必须正确布线,且此网络的管理复杂性与管理数据网络的复杂性相当,因为其

需要与多个交换机和路由器联网。此外,这里需要注意一个重要问题:管理网络是最后一道防线;如果管理网络失效且主网络也中断,则我们将无法管理服务器。虽然我们可以通过构建多路径和使用冗余交换机来提高有线解决方案的冗余性,但这也会增加复杂性和成本。在此,我们通过考虑管理网络的成本以及测量机架内无线链路质量,将有线DCM的成本与我们提出的基于无线的解决方案(CapNet)进行比较。
2.1 与有线DCM的成本比较
为了比较硬件成本,我们考虑了DiGi交换机的成本(3917美元/48端口[3])、控制器成本(约500美元/机架[4])、线缆成本(2美元/根线缆[5])以及额外的管理网络交换机成本(平均3000美元/48端口[6])。为简化成本模型,我们未包含布线的人工或管理成本,但需注意这些成本在有线DCM中也相当显著。我们假设每机架有48台服务器,并且最多需要管理10万台服务器,这在大型数据中心中是典型的。对于基于无线DCM的CapNet解决方案,我们采用IEEE 802.15.4(ZigBee)技术以利用其低成本优势。顶层的网络交换机成本保持不变,但DiGi的成本可大幅降低。我们假设每个无线控制器成本为10美元,该控制器本质上是一个以太网到ZigBee中继器。对于主板上的无线接收器,我们假设每台服务器的射频芯片和天线成本为5美元,因为主板控制器已就位[7]。
我们基于这些单独的成本开发了一个简单成本模型,并计算了在服务器数量从10到10万范围内实施管理所需的总设备数量(以捕捉成本随服务器数量的变化情况)。我们从两个维度考虑解决方案:(1)有线与无线;(2)N冗余与2N冗余(2N冗余系统由两个独立的交换机、DiGi设备以及通过管理系统的路径组成)。图2展示了这些解决方案之间的成本比较。我们看到,对于10万台服务器,有线N冗余DCM解决方案(有线‐N)的成本是无线N冗余DCM解决方案(CapNet‐N)的12.5×倍。如果我们把管理网络的冗余度提高到2N,则有线解决方案(在有线‐2N和有线‐N之间)的成本翻倍。相比之下,无线解决方案的成本仅增加36%(由于顶层使用了2N控制器和2N交换机)。最终的
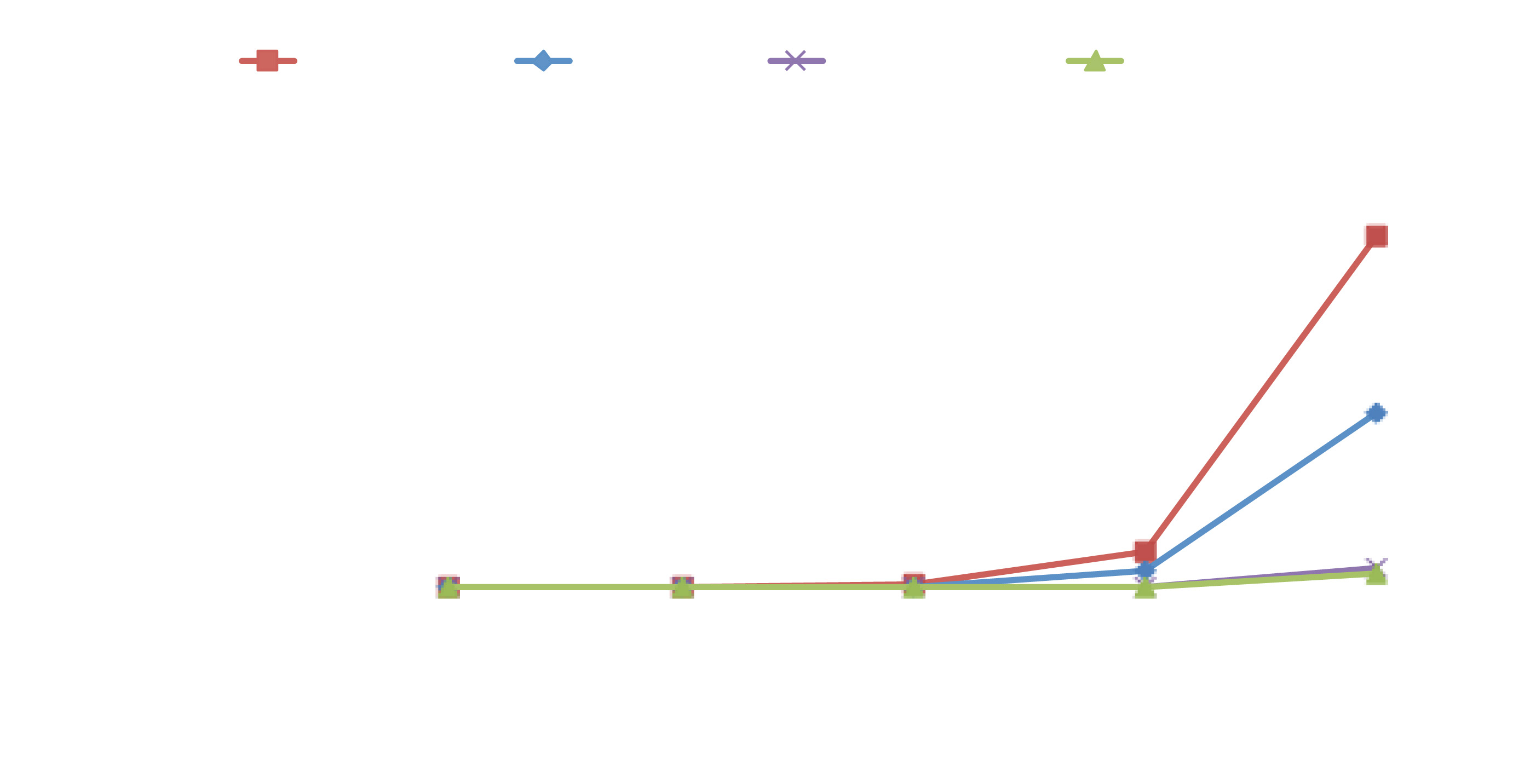
有线‐2N 是 CapNet‐2N 的 18.4×。鉴于有线DCM与CapNet之间显著的成本差异,我们接下来探讨无线是否可用于机架内通信。
2.2 无线的选择—IEEE 802.15.4
我们特别感兴趣的是低带宽无线技术(如IEEE 802.15.4),而不是IEEE 802.11,原因有多个。首先,数据中心管理的数据有效载荷大小较小,因此ZigBee(IEEE 802.15.4)的网络带宽足以满足控制平面流量的需求。其次,在Wi‐Fi(IEEE 802.11)中,接入点在基础设施模式下能够支持的节点数量有限,因为它必须为每个连接维护一个IP协议栈,这在密集部署场景下会影响可扩展性。第三,为了支持管理功能,即使机架断电,数据中心管理系统也应继续工作。小型备用电池可以以高得多的能效使ZigBee运行更长时间。最后,ZigBee的通信协议栈比Wi‐Fi更简单,因此主板(基板管理控制器)上的微控制器可以保持简单。尽管我们并未排除其他无线技术,但在本文中我们选择使用ZigBee进行原型开发。
2.3 机架内部射频环境
我们未发现任何先前的研究通过服务器和金属板对机架内的信号强度进行评估。机柜内部的金属板材已知会削弱无线电信号,从而为机架内部的无线电传播造成严苛的环境。
RACNet[43]研究了数据中心的无线特性,但仅限于所有无线电设备安装在机架顶部时的跨机架情况。因此,我们首先基于微软公司一个数据中心内的机架内无线电传播,开展了深入的802.15.4链路层测量研究。
设置 :用于测量研究的数据中心的机架由多个容纳服务器的机箱组成。每个机箱被组织为两列滑轨。在所有实验中,一个TelosB节点放置在机架顶部(ToR),位于机架外壳内部。其他节点则在不同实验中放置于机箱内的不同位置。图 3展示了八个节点在一个底部滑轨内的布置情况(图中显示为打开状态,但在实验中是关闭的)。在测量下行链路质量时,ToR上的节点为发送方,机箱内的节点为接收方。然后我们交换发送方和接收方以测量上行链路质量。在每种设置中,发送方以4赫兹的频率发送数据包。每个数据包的有效载荷大小为29字节。通过为期一周的测试捕捉链路的长期变化,我们收集了信号强度和

包接收率(PRR)。我们在数据中心两个不同位置的两个不同集群中进行了实验。
结果 :首先,我们实验了在数据中心一个集群中低功耗无线通信的可行性。该集群已通电,但服务器未运行。我们的下一次测量以及所有后续实验将在运行中的集群中进行。图 4(a) 显示了在底部滑轨内的接收方接收到的来自 ToR 节点的 1,000 次传输的接收信号强度指示 (RSSI) 值的累积分布函数(CDF),这些传输使用 IEEE 802.15.4 通道26 并采用不同的发射功率( Tx power)。当发射功率为 −7dBm 或更高时,在 100% 的情况下 RSSI 均大于 −70dBm。
ZigBee 接收方中的 RSSI 值范围为 [−100, 0]。先前关于 ZigBee 的研究 [61]表明,当 RSSI 高于 −87dBm(约)时,包接收率至少为 85%。因此,我们可以看到,底部滑轨中接收方的信号强度相当强。图4(b) 显示了在同一接收方处,ToR 节点在不同信道上以 −3dBm 发射功率进行 1,000 次传输的 RSSI 值的 CDF。两个图均表明信号强度较强,并且每次实验中的 PRR 至少为 94%(图 4(c))。
对于同一集群,我们现在进行上行通信的实验。具体而言,我们将传感器节点放置在机架内的不同位置,并向ToR上的节点进行传输。将发送方节点放置在机架的不同位置时,我们展示了在发射功率为 −3dBm(26信道)下,每个发送方在ToR节点(接收方)处 1,000次传输的RSSI值的累积分布函数,如图5所示。图中,“位置6”表示发送节点被放置在底部滑轨最远端的位置。其他位置表示发送节点位于不同的上部滑架。如图所示,在 除位置6外的所有情况下,100%的RSSI值均大于 −70dBm。对于位置6,在超过90%的情况下,RSSI值大于 −80dBm。因此,RSSI值表明上行通信中的信号也足够强。

接下来,我们在数据中心的另一个集群中进行了类似的实验。这是一个运行中的集群,位于与先前集群不同的位置(在同一数据中心的同一楼层)。在此位置,外部Wi‐Fi信号非常弱,因此不存在来自共存网络的外部干扰。图6(a)展示了在发射功率为 −3dBm时, ToR节点在不同信道(26、20、15、11信道)上向底部滑轨内接收方进行1,000次传输的 RSSI值的累积分布函数。在每一个信道上,100%情况下的RSSI值均大于 −65dBm。因此,此处底部滑轨内接收方的信号强度也非常强。图6(b)显示,每个信道上的PRR至少为95%。
我们在测量研究的所有其他设置中均观察到了类似的结果,此处省略这些结果。
测量研究表明,低功耗无线技术(如 IEEE 802.15.4)可用于数据中心机架内的通信,并能可靠地用于遥测。我们现在聚焦于功率封顶场景以及通过无线 DCM 实现实时功率封顶的 CapNet 设计。
3 CapNet设计概述
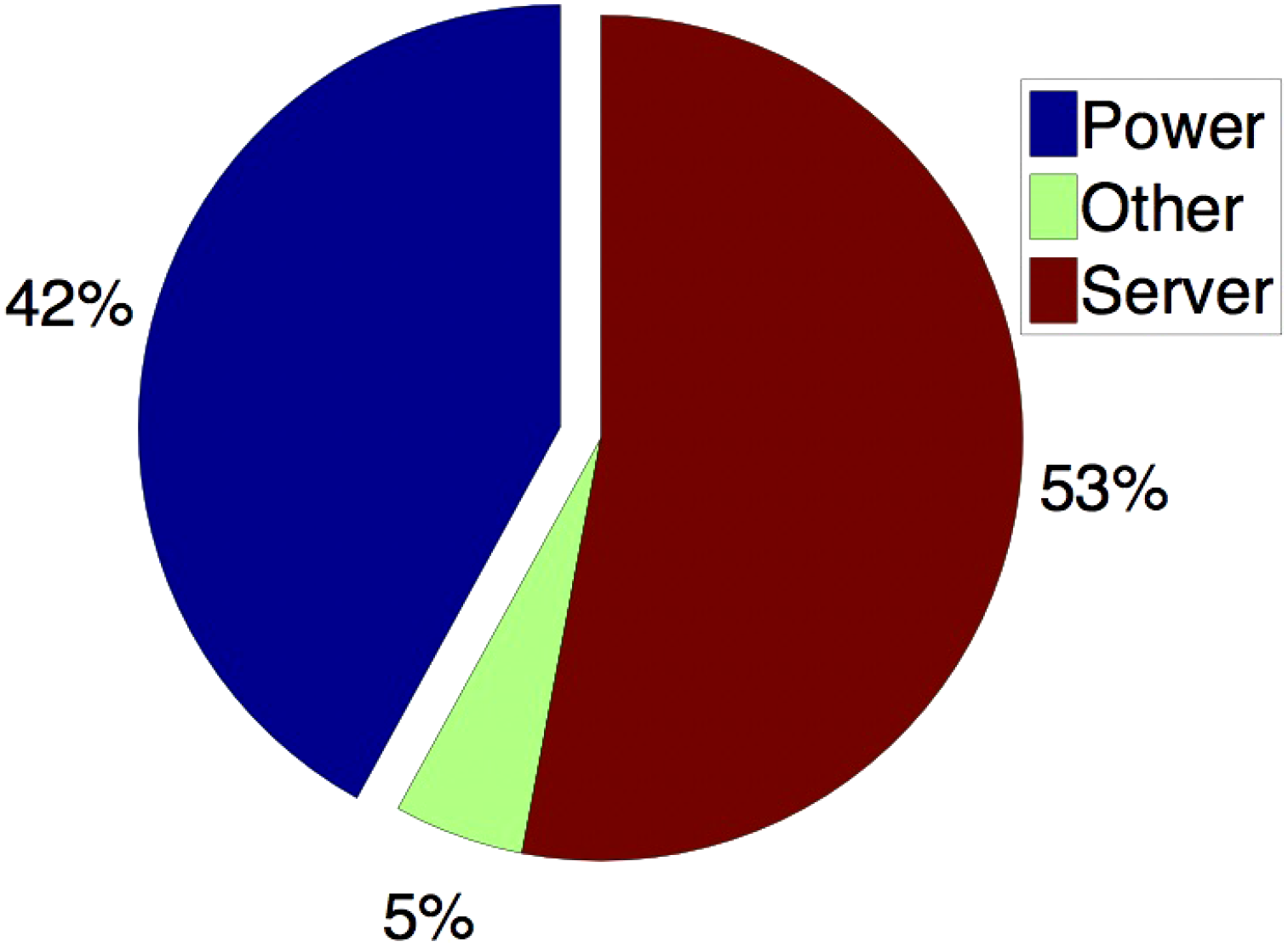
电力基础设施对于数据中心而言需要巨大的资本投资,可能占到一个耗资数亿美元的大型数据中心总成本的 ≈42%(图 7)[31]。因此,希望将已部署的基础设施利用至其最大额定容量。支路电路的容量在设计阶段即已确定,依据正常运行时的上游变压器容量,或在使用备用电源时的不间断电源/发电机容量。

图8. 罗克韦尔·艾伦‐布拉德利1489‐A型断路器在40°C 时的脱扣曲线[8]。X轴为过载程度,Y轴为跳闸时间。
为了提高数据中心利用率,企业数据中心的常见做法是进行超额订阅[27, 30, 44, 50]。该方法将电路中的服务器分配总量超过其额定容量(即上限),因为并非所有服务器会同时达到其最大功耗。因此,需要通过断路器(CB)来保护昂贵设备。超过上限的峰值功耗有一个规定的时间限制,称为跳闸时间,该时间取决于超额订阅的程度(如图8所示的罗克韦尔·艾伦‐布拉德利1489‐A型断路器)。如果超额订阅持续时间超过跳闸时间,则断路器 (CB)将跳闸,导致非预期的服务器关机和电力中断,从而影响数据中心的正常运行。功率封顶是一种将总功耗恢复到上限之内的机制。在实际电流负载下的过载状态,断路器( CB)的跳闸时间尺度从几百毫秒到数小时不等,具体取决于过载程度[8]。这些跳闸时间即为对应超额订阅程度的截止时间,必须在此时间内完成功率封顶,以防止断路器(CB)跳闸,避免电力损失或对昂贵设备造成损害。
3.1 功率封顶问题
众所周知,管理单个服务器的峰值功耗非常重要,目前大多数服务器都配备了功率封顶机制,可将其各自的峰值功耗限制在设定的阈值内。然而,这种独立且静态的封顶方式无法让服务器利用其他服务器未使用的电力。通过集中式或全局式地协调多个服务器的封顶值,可以避免此类容量浪费。在数据中心中更受青睐的所谓协同封顶中,当一个集群(由多台服务器组成)中的某些服务器处于负载较低状态时,其未使用的电力可供其他服务器使用,使其运行功率超过各自的静态上限。本文重点关注协同功率封顶。
为了实现对机架或集群的功率封顶,功耗封顶管理器(也称为控制器)会收集所有服务器的功耗,并确定集群级总功率。如果总功耗超过上限,则管理器将生成控制消息,要求部分服务器通过CPU频率调节(若使用DVFS,还包括电压调节)或利用率限制来降低其功耗。应用层面的服务质量可能要求不同服务器以不同的级别进行封顶,因此中央控制器需要获取每个服务器的独立读数。在某些优雅限流策略中,控制消息由基板管理控制器发送至主机操作系统或虚拟机,这会因操作系统栈[22, 44]而引入额外延迟。为了避免应用程序性能发生突变,控制器可能会逐步调整功耗,并在集群稳定至低于功率上限之前,需要多次迭代反馈控制环[44, 65]。这些控制策略已被先前的研究广泛探讨,不在本文的讨论范围之内。
3.2 通过无线DCM进行功率封顶
数据中心中的服务器被堆叠并组织成机架。图9展示了数据中心内的无线DCM架构。一个集群 是一个逻辑概念,表示由一个或多个机架组成的电源管理单元。尽管电源管理单元也可能是分层的,但在协议设计中,我们考虑对包含n台服务器的单个集群进行电源管理。
集群中的每台服务器都集成了一个连接到BMC微控制器的无线收发器。每台服务器都能够测量自身的功耗。现代服务器硬件具有内置的功耗计量能力(例如,使用基于主板或电源的功耗传感器),并且存在多种解决方案用于监控旧式服务器的功耗[36, 37]。在服务器上,通过服务器操作系统提供的相应应用程序接口获取功耗读数。
集群功耗封顶管理器可以直接使用电表测量总功耗,或者为了实现细粒度功耗控制,聚合来自单个服务器的功耗数据。我们重点关注第二种情况,因其具有更高的灵活性。在这种方法中,可以针对任意服务器子集启用功率封顶。此外,为了实现封顶,我们需要知道所有单个服务器的功耗读数,以便封顶控制算法根据各服务器的个体功耗确定需要进行封顶的服务器子集(例如,基于当前功耗对服务器进行优先级排序)。
电力超额订阅以及断路器相应的跳闸时间被映射到功耗封顶管理器的超额订阅和相应截止时间。根据总功耗和超额订阅幅度,功耗封顶管理器通过无线链路向单个服务器发送封顶指令。与有线DCM相比,主要区别在于广播无线介质以及调度通信以满足实时需求的挑战。
为了减少额外协调并实现空间频谱复用,我们假设集群内部通信使用单个 IEEE 802.15.4 信道。通过使用多个信道,多个集群
CapNet在集群中的n个 服务器和机架顶部的功耗封顶管理器之间形成一个无线网络。它构成一个星型拓扑,其中管理器直接与服务器上的无线传感器通信。在CapNet的原型中,无线设备通过服务器的串行接口插入,监测服务器功耗,并将数据无线报告给管理器,同时接收来自管理器的控制命令。需要注意的是,这是首次提出利用低功耗无线技术用于功率封顶等关键DCM操作的工作。因此,在未来的生产服务器中,预计无线接口将被集成到主板中。即使未来未实现这一点,CapNet仍可通过服务器的串行接口使用低功耗无线芯片在数据中心中部署。此外,对于能够监控单个服务器功耗的智能机架[14],CapNet 可以通过使用机架顶部无线设备来实现。
请注意,我们在第2节中展示的关于无线可行性的实验并未包含无线接口集成到主板中的情况。然而,我们通过将一个节点放置在底部滑轨的最末端进行了实验。该设置可被视为服务器与管理器之间无线通信的一个极端场景。我们的实验还观察到,在超过90%的情况下,RSSI大于 −80dBm,通信依然可靠。因此,即使无线接口集成在服务器内部的主板上,我们也可以预期实现可靠的无线通信。
3.3 一种简单的周期性协议
实现细粒度功率封顶策略的一种简单方法是通过定期从单个服务器收集功耗读数来持续监控服务器。管理器定期计算总功率,一旦总功率超过上限,便生成一条控制消息。在完成 η次迭代的聚合与控制后,重新恢复周期性聚合。
3.4 事件驱动的CapNet
过度订阅的数据中心可能会为峰值功耗的第95百分位(或更高)进行配置,并且每年需要进行5% (或更少)时间的功率封顶,这相对于成本节约而言,对性能的影响是可以接受的[22]。因此,功率封顶是一种罕见事件,而简单周期性协议属于过度设计,因为它始终为最坏情况做准备,导致无线介质饱和,其他延迟容忍遥测消息无法获得足够的网络资源。一种理想的无线协议
只有在发生显著功率激增时,才应产生大量网络流量。因此,CapNet采用了一种事件驱动策略,旨在仅在预测到潜在的功耗封顶事件时才触发功耗封顶控制操作。由于功率激增具有罕见性和紧急性,网络可以暂停其他活动以处理功耗封顶,从而在不消耗过多网络资源的情况下提供实时性能和可持续的可靠性水平。该协议的详细信息将在下一节中说明。
4 功耗封顶协议
我们设计了一种分布式事件检测策略,通过将全局(集群级)限制分解为每个服务器的本地上限。当某台服务器根据自身的功耗读数观察到本地功率激增时,可触发对所有服务器功耗数据的采集,以检测集群总功耗是否存在潜在的激增。若检测到集群级功耗激增,则系统将启动功耗封顶动作。由于可能有多个服务器同时超过其本地上限;如果我们采用标准的CSMA/CA协议,则所有这些服务器将尝试同时传输数据。这种方法会因过度竞争和冲突而导致严重的丢包问题(我们将在第6节中通过实验验证这一点),从而影响功耗封顶的延迟敏感性。事实上,基于CSMA/CA的协议可能无法提供可预测的延迟,因此不适用于实时通信[58]。因此,我们也不采用CSMA/CA方法。最后,由于总功耗可能变化剧烈,仅依靠历史功耗读数来预测即将出现的功耗峰值可能是不可行的。因此,我们也无法采用基于历史功耗读数主动调度数据采集的预测性协议。
虽然通过在支路电路级别进行监控(例如使用电表)可以实现全局检测,但它无法支持细粒度且灵活的功耗封顶策略,例如基于单个服务器优先级或根据各个服务器的功耗来降低其功率。此外,集中式测量会引入单点故障。也就是说,如果电表发生故障,电力超额订阅也将失败。相比之下,我们的分布式方法对故障更具弹性。如果某个测量出现故障,系统始终可以假设该服务器的最大功耗,并保持整个集群继续运行。
事件驱动协议的运行分为三个阶段,如图10所示:检测、聚合和控制。事件检测阶段根据本地功率激增生成警报。当检测到潜在事件时,CapNet 进入第二阶段,启动功率聚合协议。当某些服务器产生的警报超过本地上限,但总功耗仍低于上限时,可能发生误检。这一问题在聚合阶段得到纠正,控制器在此阶段确定总功耗。误报情况的影响是系统会进入聚合阶段,从而产生额外的无线流量。仅当警报为真时,才会执行控制阶段。
我们将每台服务器的功耗值通过将其瞬时功耗除以单台服务器的最大功耗,归一化到 0和1之间。服务器i的归一化功耗值用p i表示,其中 0 ≤p i ≤ 1,本文中将其作为服务器的功耗使用。根据这些归一化功耗值,由n台服务器组成的集群的上限用c表示,n台服务器的总功耗被视为总功耗,并用p agg表示。协议描述中使用的重要符号也在表1中进行了总结。
分配本地上限 。如果pa gg > c,则必要条件是某些服务器(至少一个)的本地功耗值超过 c n。因此,一种可能的方法是将 c n作为每台服务器的本地上限。然而,可能存在仅有一台服务器超出的情况
 (或者,如果网络被视为不可靠,则检查条件(2))。如果满足该条件,则表明估计的总功率可能超过上限,从而启动聚合阶段以确定实际总功耗。如果实际总功耗确实超过了上限,则启动控制阶段,选择若干服务器通过CPU降频来降低其功耗。)
(或者,如果网络被视为不可靠,则检查条件(2))。如果满足该条件,则表明估计的总功率可能超过上限,从而启动聚合阶段以确定实际总功耗。如果实际总功耗确实超过了上限,则启动控制阶段,选择若干服务器通过CPU降频来降低其功耗。)
| 符号 | 描述 |
|---|---|
| n | 集群中服务器的总数 |
| c | 集群的功率上限 |
| p i | 服务器i的功耗 |
| h | 检测间隔 |
| pagg | 集群聚合功耗 |
| ω | 滑动窗口协议的窗口大小 |
| τd | 最大下行通信时间 |
| τu | 最大向上通信时间 |
| Ldet | 检测阶段耗时 |
| Lagg | 总聚合延迟 |
| Los | 操作系统级延迟 |
| Lhw | 硬件级延迟 |
| Lcap | 单次迭代中的总功率限制延迟 |
而其他所有服务器均低于 c n而其他所有服务器均低于 c n,从而触发单个服务器警报的聚合阶段。因此,该策略将产生大量误报,进而引发不必要的聚合阶段和通信。为了减少不必要的聚合阶段,我们为每个服务器分配一个略小的本地上限,并在启动聚合阶段前综合考虑多个服务器的警报。因此,我们使用一个接近 1 的值 0< α ≤ 1并将 α c n作为每个服务器的本地上限。当服务器 i满足 p i > α c n 时报告警报。在此策略下,多个服务器同时产生警报的概率可能小于单个服务器产生警报的概率,从而减少了不必要的聚合阶段。
每台服务器被分配一个唯一的ID i,其中 i= 1, 2, . . . ,n。管理器每隔h个时间单位广播一次称为检测间隔的心跳信号数据包。长度为h的检测间隔被划分为时隙
分成 n个时隙,每个时隙长度为 h n。随着集群中服务器数量的变化,时隙长度可以进行更新/调整。然而,h的取值需确保一个时隙足够长,以容纳一次传输及其确认。在接收到心跳消息后,服务器时钟实现同步。
4.1 检测阶段
每个节点 i, 1 ≤ i ≤ n,在检测阶段的第 i个时隙采集其样本(即功耗值 p i)。如果其读数超过上限,即 p i> α c n,则生成一个警报,并将该读数(p i)作为对心跳消息的确认发送给管理器。否则,忽略心跳消息且不执行任何操作。如果在第s个时隙接收到警报,管理器将根据网络是否可靠来判断是否需要启动聚合阶段。令当前检测窗口中迄今已发送警报的服务器集合表示为 A。
可靠网络 。假设在某个检测间隔的第s个时隙生成了一个警报。考虑到这是一个可靠网络,可以认为没有服务器消息丢失。因此,在前s台服务器中其余的 s − |A| 台服务器每台的功耗读数最多为 α c n,因为它们未产生警报。其余 n −s 台服务器每台的功耗值最多为1。因此,基于第s个时隙的警报,管理器可以估计总功率为 ∑j ∈A pj+(s − |A|) α cn +(n− s)。因此,如果在第s个时隙生成了警报,则当满足以下条件(条件(1))时,管理器将启动聚合阶段,如图10所示,
∑ j ∈A pj+(s − |A|) αc n +(n− s)> c. (1)
不可靠网络 。现在我们考虑一种场景,其中一些服务器的警报丢失了。因此,如果在一个检测窗口的第s个时隙生成了一个警报,则前s − |A|台服务器中的每一台可能由于其警报被认为已丢失而最多具有1的功耗读数。因此,n− |A| 台服务器中的每一台的功耗最多为1,从而估计总功率为∑j ∈A pj+(n − |A|)。该技术可同时处理链路故障和节点故障。因此,如果在第s个时隙生成了一个警报,管理器将启动聚合阶段
∑ j ∈A pj +(n− |A|)> c. (2)
如果在检测阶段没有警报,或所有报警消息均因传输故障而丢失,则当当前阶段结束后,控制器将恢复下一个检测阶段(使用相同的机制再次检测激增)。
4.2 聚合阶段
为了最小化聚合延迟,CapNet 采用基于滑动窗口的协议来确定总功耗,记为pagg。控制器使用大小为 ω 的窗口。在任意时刻,它以轮询方式选择 ω 台服务器(或者,如果尚未收集读数的服务器少于 ω 台,则选择所有这些服务器),这些服务器将在下一个窗口中依次发送其读数。这 ω 个服务器 ID 被按顺序排列在一条消息中。在窗口开始时,控制器广播该消息,并在广播后启动一个长度为 τd + ωτ u 的定时器,其中 τd 表示最大下行通信时间(即控制器的数据包传递到服务器所需的最长时间), τ u 表示最大上行通信时间(服务器到控制器)。接收到广播消息后,消息中 ID 顺序为 i, 1 ≤ i ≤ ω 的任何服务器,在 (i − 1)τu 时间后发送其读数。其他服务器则忽略该消息。
消息。如果定时器触发或收到了来自所有 ω节点的数据包,则控制器会创建下一个窗口,包含尚未被调度或在前一个窗口中数据包丢失的 ω服务器。为处理传输失败,每个服务器最多在 γ个连续窗口中被调度,其中 γ是网络中最差情况下的期望传输次数(ETX)。该过程持续进行,直到收集到所有服务器的读数,或没有服务器被重试超过 γ次。
为了减少聚合延迟,我们应将窗口大小 ω设置得足够大。然而,它不能被任意设置得过大。过大的窗口大小要求管理器消息的有效载荷大小更大(因为数据包包含 ω节点ID,用于指示下一个窗口的调度)。虽然可以使用位图技术来保持管理器的消息大小较小,但由于服务器的时钟漂移,窗口大小仍然受到限制。请注意,在接收到管理器的广播消息后,任何其ID在消息中顺序为i、 1 ≤ i ≤ ω的服务器,将在(i − 1)τu时间之后传输其读数。因此,如果窗口大小过大,在长时间窗口下由于时钟漂移可能导致两个服务器的传输时间重叠。因此,窗口大小的设定应同时考虑管理器的消息大小和服务器的时钟漂移。
4.3 控制阶段
在完成聚合阶段后,如果pagg> c,其中c是上限,则进入控制阶段。控制阶段通过控制算法生成封顶控制指令,然后控制器广播消息,要求部分服务器进行封顶。为了应对广播失败的情况,会重复广播γ次(因为广播无确认机制)。服务器通过动态电压频率调节或 CPU降频响应封顶消息,这会引入操作系统(OS)级别的延迟以及硬件引起的延迟[22]。
如果控制算法需要 η次迭代,则在第一轮执行封顶控制指令后,控制器将再次运行聚合阶段,以重新确认封顶操作是否正确执行。该过程最多继续(η − 1)次迭代。在控制阶段完成后,或在误报情况下完成聚合阶段后,系统将恢复到检测阶段。
4.4 延迟分析
鉴于功率封顶的时间关键性,CapNet 实现有界延迟非常重要。在此,我们提供了 CapNet 功耗封顶延迟的解析延迟上界,该上界由检测阶段延迟、聚合延迟、操作系统级延迟和硬件延迟组成。在实际中,实际延迟通常低于该上界。系统管理员可利用此分析来配置集群,以确保功率封顶满足时序约束。
聚合延迟 :对于n个服务器的集群,总聚合延迟 Lagg在无传输故障的情况下可被上界估计如下。注意每个 ω传输窗口最多需要 τu ω+ τ d个时间单位。最多可能有 n ω 个窗口,每个窗口中ω个服务器进行传输。最后一个窗口仅需 τu(nmod ω)+ τ d时间来容纳剩余的 (n mod ω)个服务器。因此,
La gg ≤(τu ω+ τ d) ⌊ ωn⌋+(τu(n mod ω)+ τ d).
考虑到 γ为网络中的最坏情况期望传输次数(ETX),
L a gg ≤((τu ω+ τ d) ⌊ ωn⌋+(τu(n mod ω)+ τ d))γ. (3)
上述值 ue 只是一个分析上的上限,在实际中延迟可能会短得多。
检测阶段的延迟:检测阶段耗时记为Ldet。在一个检测窗口内,协议永远不会需要最后 c − 1台服务器的读数,因为如果需要功率封顶,则必须在此之前启动聚合阶段(假设并非所有警报都丢失)。因此,在前(n − c+ 1)个时隙内生成的警报必须触发聚合阶段。因此,
Ldet ≤ ⌊hn⌋(n− c+ 1). (4)
总功耗封顶延迟 :为了处理一次功耗封顶事件,系统首先执行检测阶段和聚合阶段,随后广播控制消息γ次,耗时τdγ。此外,当控制消息到达服务器后,还存在操作系统级延迟;在处理器频率调整后,还会产生硬件引起的延迟。设最坏情况下的操作系统级延迟和硬件级延迟分别用Los和Lhw表示。因此,单次迭代中的总功率限制延迟,记为Lcap,其上界满足
Lcap ≤ Ldet+ Lagg+ τdγ+ Los+ Lhw.
A η次迭代控制意味着,一旦执行了功耗封顶命令,控制器将需要再次从服务器收集所有读数,并在接下来的(η − 1)次迭代中重新确认封顶
操作是否正确完成。因此,对于 η次迭代控制,上述界限由以下给出
Lcap ≤ Ldet+(Lagg+ τcγ+ Los+ Lhw)η. (5)
5 容错
一个重要的挑战是在集群中处理功率封顶管理器的故障。在本文中,我们重点关注功率封顶管理器中的失效停止模型。我们利用一种故障转移机制,使附近机架中的功率封顶管理器能够接管其功率封顶管理器已发生故障的机架的管理功能。当某个管理器发生故障时,附近的管理器可以接管其服务器。我们首先通过跨机架测量表明,附近的控制器通过无线传感器网络与机架中的节点通信是可行的。
5.1 跨机架测量
类似于第2.3节中的设置被用于评估跨机架的无线电传播。实验在密苏里州圣路易斯华盛顿大学的一个数据中心进行。我们将一个发射节点放置在一个机架内,将一个接收节点放置在另一个不同的机架内。我们使用26信道和0dBm的发射功率进行传输,并记录接收方的所有信号强度值。我们重复该实验,将接收节点放置在不同的机架中,使得两个机架之间的行数不同。具体而言,我们将发送节点放置在第1行的一个机架内,并在第2、3、4和5行的每个机架中各放置一个接收节点。图 11显示了当接收节点位于不同机架(与发送节点距离不同)时,1,000次传输的RSSI值的累积分布函数。该图表明,无线电设备能够跨越几个机架并保持可接收的信号强度,因为从第1行发出的传输可以到达第4行,且RSSI值高于 −70dBm。该结果表明,当某个电源管理器发生故障时,附近的电源管理器将能够与其服务器通信。
5.2 故障处理机制
对于每个功耗封顶管理器(控制器),我们从附近的机架中指定一个备用功率限制管理器,当该管理器发生故障时,由其接管对应服务器的管理。在我们的设计中,功耗封顶管理器使用一个独立的 802.15.4无线电,通过一个不同于两个集群中服务器通信所用的信道,与其备份管理器进行通信。
备份管理器可以根据心跳消息检测管理器的故障。具体而言,管理器B可以定期向其备份管理器A发送心跳信号。如果A在一定时间窗口内未收到一定数量的心跳消息(即未收到任何心跳),则会判定B已发生故障。对于每个功耗封顶管理器,都会分配或手动设置一个备份管理器。通过分配多个备份管理器,可以处理级联故障。
我们解释故障处理机制,假设当控制器B发生故障时,备用控制器A将接管B的服务器。A将其信道切换至B的信道,并广播一条恢复消息,该消息重复 γ次以确保所有节点接收到广播,之后B的所有节点加入A。设A的服务器编号为1, 2, …,na,而B的服务器编号为1, 2, …, nb。此时A的检测间隔被划分为时隙,每个时隙长度由
⌊ h na+ nb⌋.
如果时隙太短,可以增加检测间隔h。现在,A集群中每个索引为i的节点在加入B后将被重新索引为(na+i)。随后,相同的事件驱动协议在包含(na+ nb)台服务器的A集群中运行。当B恢复后,A将放弃B的服务器,并要求它们切换回原来的信道。
6 实验
在本节中,我们展示了CapNet的实验结果。目的是评估CapNet在数据中心真实环境设置下满足功率封顶实时要求的有效性和鲁棒性。
实现 。 CapNet 的无线通信部分在 TinyOS [15]平台上使用 NesC 实现。为了符合实际的数据中心实践,我们在功率封顶管理器端实现了控制管理。在我们的实现中,无线设备通过串行接口直接插入服务器。
工作负载轨迹 。 我们使用了一家全球公司在连续6个月期间运营的多个地理分布的数据中心的工作负载需求轨迹。每个集群包含数百台服务器,跨越多个机箱和机架。这些集群运行多种工作负载,包括网络搜索、电子邮件、Map‐Reduce作业和云应用,服务于全球数百万用户。每个集群采用同构硬件,尽管不同集群之间可能存在差异。我们使用了两个代表性服务器集群C1和C2的工作负载轨迹。在这两个集群中,每台服务器均有连续6个月、每2分钟间隔的CPU利用率数据。虽然我们认识到全系统功耗包含存储、内存,以及其他组件,除了中央处理器外,之前的一些研究表明,服务器的利用率与其功耗大致呈线性关系[24, 25, 27, 53]。因此,在所有实验中,我们使用服务器的中央处理器利用率作为功耗的代理指标。
6.1 实验设置
6.1.1 实验方法
我们使用TelosB节点进行CapNet的无线通信实验。首先,我们在华盛顿州雷德蒙德的微软数据中心部署了81个节点(1个作为管理器,80个用于服务器)。集群中的服务器已通电并正常运行。当我们实验超过80台服务器以测试可扩展性时,一个节点会模拟多个服务器并为其进行通信。例如,在实验480台服务器时,第1个节点负责前6台服务器,第2个节点负责接下来的6台服务器,依此类推。这是可行的,因为在检测阶段或聚合阶段不会有两个节点同时传输。而控制阶段则向所有服务器发送一条通用的广播消息。
我们将80个传感器节点全部放置在机架中。管理节点放置在机架顶部(ToR),并通过其串行接口连接到作为管理器的个人计算机(PC)。机架中的任何传感器节点均无与管理节点的直接视线连接。利用工作负载需求轨迹,CapNet以基于轨迹驱动的方式运行。对于每台服务器,在某一时间戳从其对应的无线节点发送的读数,均从这些轨迹中相同时间戳处获取。由于我们拥有每2分钟间隔的数据,在基于轨迹驱动的实验中,两个连续数据点之间某一时间戳的功耗值通过这两个数据点之间的线性插值获得。尽管数据轨迹长达6个月,我们的实验实际上并不运行6个月。当我们取这些轨迹的一个子集(例如4周)时,协议会跳过没有峰值的长时间间隔。例如,当我们已知(通过预读轨迹)在时间t1和t2,之间没有峰值时,协议便会跳过t1和t2之间的时间段。因此,我们的实验在几天内完成,而不是4周。
6.1.2 超额订阅与跳闸时间
我们使用图8中的跳闸时间作为基础,以确定在各种实验中所需的不同封顶值。在图 8中,X轴显示电流负载与额定电流的比值,即超额订阅幅度。Y轴显示相应的跳闸时间。在我们的实验中,对于特定的超额订阅幅度,我们考虑X轴上的相同值(超额订阅幅度),并将Y轴上对应的跳闸时间作为截止时间。跳闸曲线显示为一个容差带。该带的上曲线表示上界(UB)跳闸时间,超过此上界的时间即为跳闸区域,意味着如果电流持续时间长于上界跳闸时间,则断路器将跳闸。该带的下曲线表示下界(LB)跳闸时间,低于此下界的时间属于非跳闸区域。两条曲线之间的带状区域是断路器是否跳闸具有不确定性的区域。下界跳闸时间是一个非常保守的界限。在我们的实验中,我们使用传统跳闸时间的下界和上界来验证CapNet的鲁棒性。
6.1.3 CapNet 参数
在所有实验中,我们使用 26信道 和 −3dBm 的发射功率。从服务器节点发送的每个数据包的有效载荷大小为 8字节,足以传输功耗读数。从管理器发送的每个数据包的最大有效载荷大小为 29字节,这是 TelosB节点 上 IEEE 802.15.4 无线电协议栈的最大默认大小。该有效载荷大小设置得较大,以容纳调度和控制信息。对于聚合协议,窗口大小ω设为 8。较大的窗口大小可以降低聚合延迟,但要求管理器消息的数据包有效载荷更大(因为数据包包含 ω个节点ID,用于指示下一个窗口的调度)。在聚合协议中, τ d和 τ u均设为 25毫秒。管理器使用这些值设置其超时时间。这些值相对于两个无线设备之间的最大传输时间来说相对较大。节点间的通信所需时间两个无线设备之间的延迟在几毫秒的范围内。但在我们的设计中,管理节点通过其串行接口连接到个人计算机。TelosB的串行接口在个人计算机与传感器节点之间的通信中并不总是具有固定延迟。经过实验并观察到该时间存在较大变化后,我们将 τd和 τu设置为25毫秒。
6.1.4 控制仿真
在我们的实验中,我们模拟了最终控制动作,因为我们使用工作负载轨迹。我们假设一个数据包足以包含整个控制消息。为了处理控制广播失败的情况,我们重复进行控制广播 γ= 2次。我们通过对数据中心机架的广泛测量研究表明,这也是任意两个无线传感器节点之间链路的最大ETX。在接收到控制广播消息后,节点会产生操作系统级延迟和硬件级延迟。我们使用在三台配备不同处理器的服务器上进行功率封顶实验所测得的操作系统级和硬件级延迟的最大值和最小值:英特尔至强L5520(频率2.27GHz,4核)、英特尔至强L5640(频率 2.27GHz,双路插槽,12核带超线程)以及AMD Opteron 2373EE(2.10GHz,8核带超线程),每台服务器均运行Windows Server 2008 R2[22]。通过实验得到的操作系统级和硬件级延迟范围如图12所示。我们在此范围内使用均匀分布生成操作系统和硬件级延迟。
6.2 数据中心峰值功耗分析
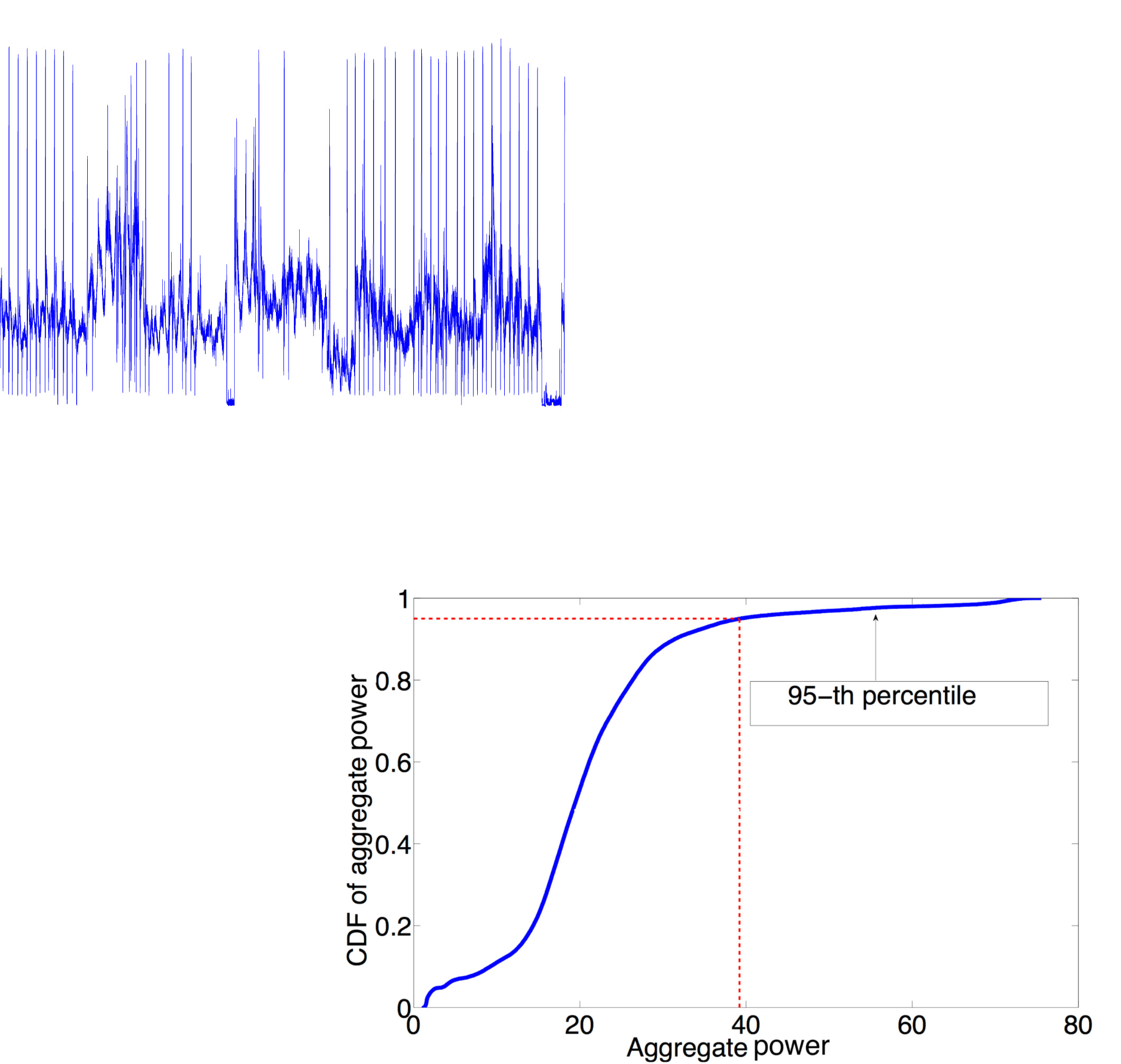
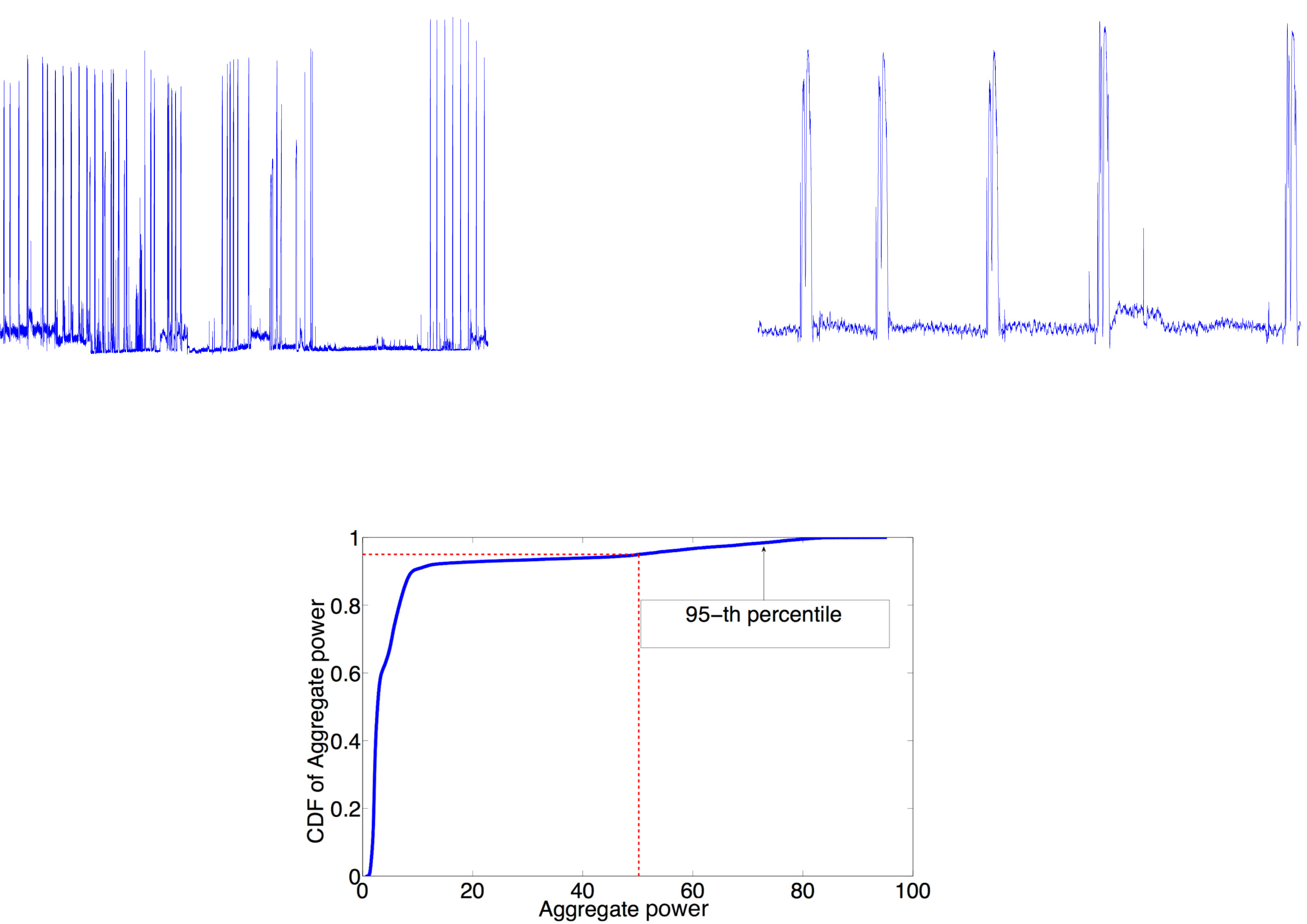
我们首先分析CapNet协议是否与利用数据轨迹得出的数据中心功耗行为一致。为简洁起见,我们展示了3个机架的数据轨迹分析结果:来自集群C1的机架R1和R2,以及来自集群C2的机架 R3。为了说明数据中心中功耗随时间的变化情况,图13(a)展示了集群C1中机架R1上60台服务器在连续两个月内的总功率,该时间段在图13(b)中放大显示了连续6天的情况。对于每个机架,我们使用连续两个月内总功率的第95百分位数作为功率上限(如图13(c)所示)。类似地,图 14展示了集群C2中机架R3的功耗轨迹。
我们首先探讨了服务器的功率动态以及功率封顶事件的不可预测性。利用两个月的数据,图15显示,连续两个峰值之间的时间间隔范围可以从几分钟到几百小时。我们将功率跃变定义为超过功率上限的功率值与之前低于该上限的测量值之间的差值。如图15(b)所示,每个机架中60台服务器的功率跃变可在0到51之间变化(而它们的总功率处于[0, 60]范围内)。该结果表明了采用事件驱动协议的必要性。
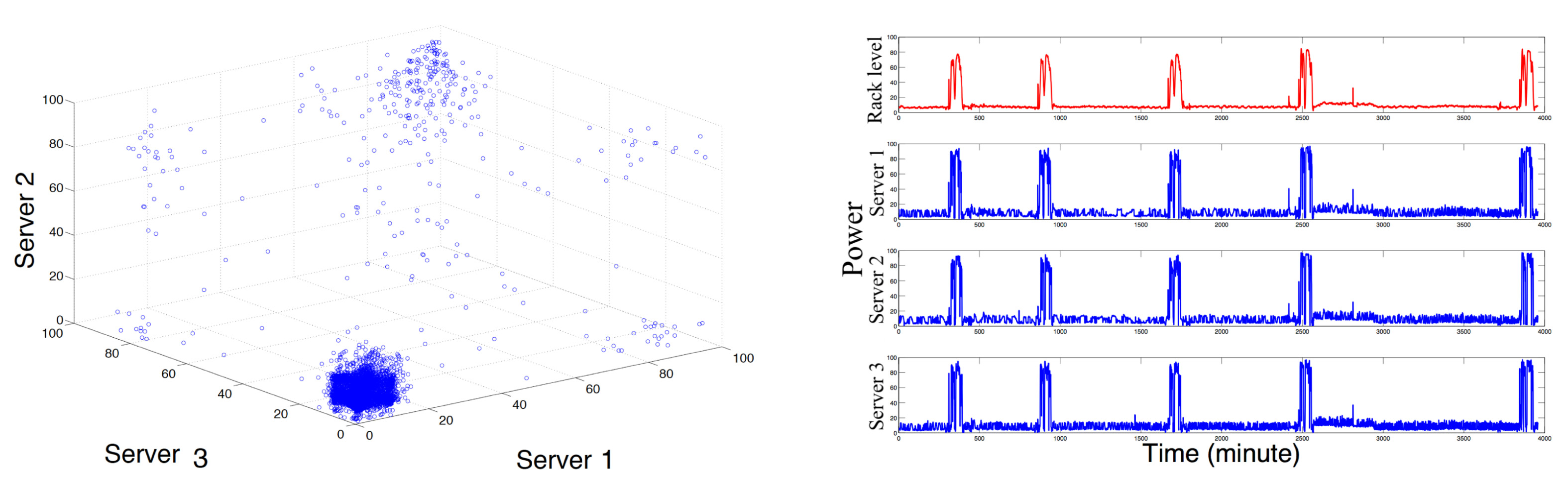
我们首先分析了集群内不同服务器功率峰值之间的相关性。在图16(a)中,机架R3 内三台服务器两个月原始数据的散点图表明,这些服务器的功耗之间存在强烈的正值相关性,其功率峰值和谷值经常同时出现。图16(b)显示了集群级别(或机架级,因为该集群包含一个机架)总功耗(上方)以及该机架中三台服务器的单个功耗(持续1周),显示了服务器之间以及集群聚合后的同步功率峰值。这种情况通常发生在同一集群中的服务器运行相似工作负载,从而导致同步功耗特性。我们进一步假设每台服务器的本地上限为 c 60 (考虑 α= 1),并在图16(c)中展示了当集群级总功率超过上限c时,超出本地上限的服务器数量的累积分布函数。该图表明,在80%的情况下,当集群级(机架级)总功率超过上限c时,超出本地上限的服务器数量(每个机架60台服务器中)分别为:机架R3为43台,机架R1为55台,机架R2为50台。这显示出较强的集群内同步功率激增表明,基于本地服务器级测量来检测集群级功耗激增是可行的。
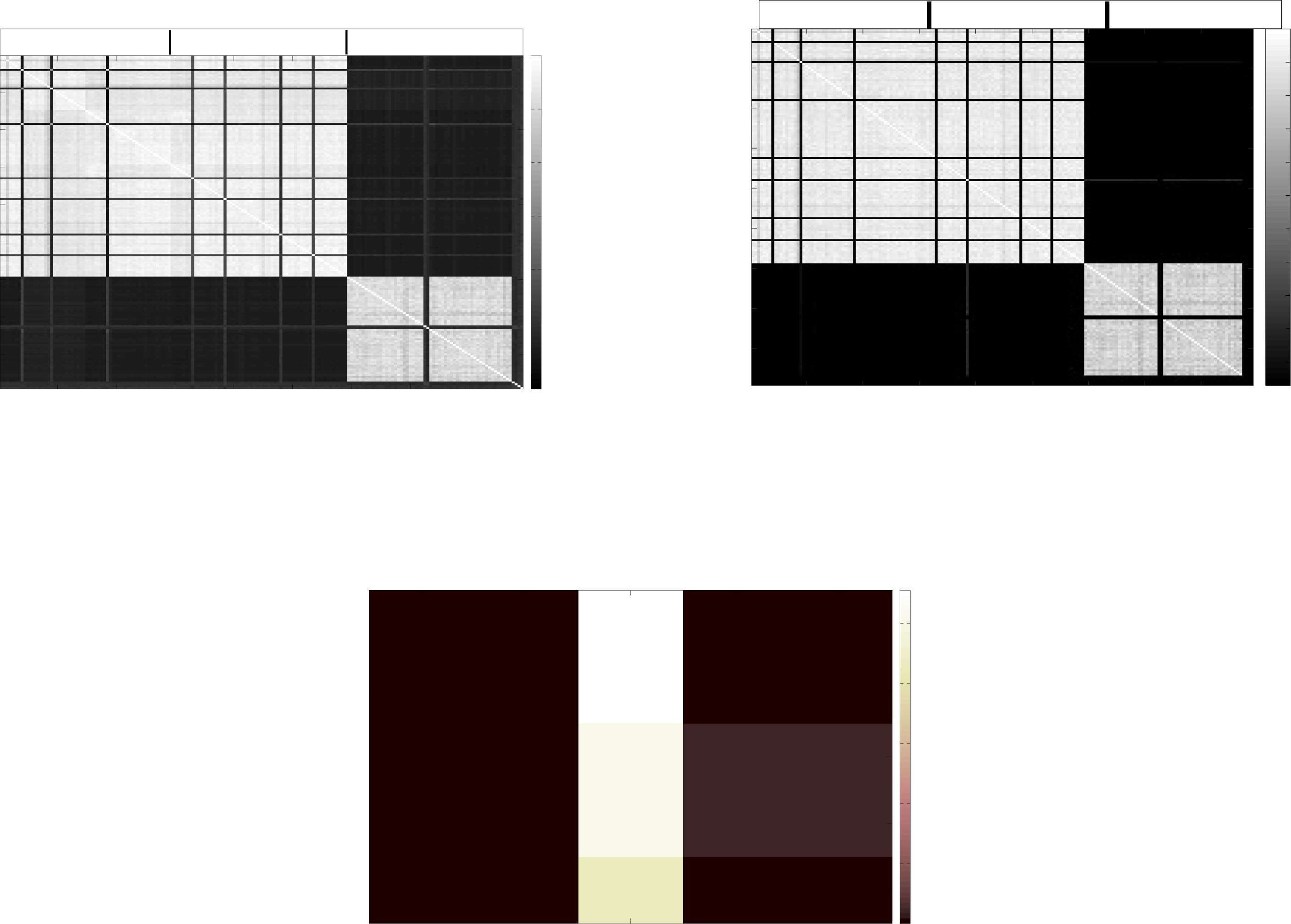
图17(a) 利用1周内的原始功耗数据,展示了来自不同机架和集群的180台服务器之间的相关性。该图像为一个 180 × 180矩阵的可视化结果,以服务器编号作为索引。即,该矩阵中位于[i,j]位置的元素表示第i台与第j台服务器之间数值(5040个样本)的相关系数。我们可以清楚地看到,同一机架内的服务器具有强正相关性,同一集群内的服务器也呈正相关,而不同集群之间的服务器相关性较弱或呈负相关。图17(b) 显示了峰值与非峰值之间相关性的类似结果(通过考虑波形,其中峰值为1,任何非峰值为0)。这种情况通常发生于同一集群中的服务器承载相似工作负载,从而导致同步功耗特性[24]。图17(c) 展示了两个集群中不同机架同时达到峰值的概率。该二维矩阵中位于[i,j]位置的元素表示集群1中的第i个机架与集群2中的第j个机架同时处于峰值的概率。这些概率值位于[0, 0。0056]范围内。这种显著的集群间异步性inter-clusterasynchrony表明,使用事件驱动协议(仅在检测到事件时进行无线通信)可显著减少由不同集群中事件驱动的CapNet所产生的传输所引起的集群间干扰。
我们观察到同一集群内服务器的功耗行为具有高度同步性,而不同集群之间则表现出强烈的异步性。跟踪分析的主要意义在于,CapNet协议与真实的数据中心功耗行为一致。由于集群内同步性表明了本地事件检测策略可能具有的有效性,因此我们的协议在存在企业数据中常见的强集群内同步性时尤为有效。
正如我们在跟踪分析中所观察到的数据中心情况。然而,如果集群内功率峰值缺乏同步性, CapNet 不会导致不必要的功率封顶控制或比周期性协议产生更多的无线流量。这种同步性仅会提升 CapNet 的性能。
6.3 功率封顶结果
现在我们展示CapNet事件驱动协议的实验结果。首先,我们将它的性能与周期性协议和一种典型的CSMA/CA协议进行比较。然后,我们从服务器数量方面分析其可扩展性。我们首先仅针对简单情况进行实验,即控制回路的一次迭代即可达到持续功率水平;随后,我们也分析在需要多次控制迭代才能达到持续功率水平时的控制迭代次数的可扩展性。我们还在不同的封顶值以及存在干扰集群的情况下进行了实验。需要注意的是,各集群的封顶值可能不同,因为一个集群的上限取决于其服务器的功耗值以及服务器的数量。在所有实验中,检测阶段长度h被设置为 100 ∗ nms,其中n是服务器数量。我们设定该值的原因是,这使得检测阶段的每个时隙等于100ms,足以接收一个警报并从管理器向服务器发送一条消息。设置更大的值会减少检测阶段的周期数,但会降低监控的粒度。为了给服务器分配 α c n的本地上限,我们首先使用 α= 1进行实验。之后,我们在不同 α值下进行实验。条件 1用于检测并启动聚合阶段。在结果中,松弛量 定义为跳闸时间(即截止时间)与实现功率封顶所需总延迟之间的差值。也就是说,负松弛值意味着截止时间错过。我们使用下界松弛量 和上界松弛量 分别表示基于下界跳闸时间和上界跳闸时间计算出的松弛量。在我们的结果中,有些情况下的时序要求可能较宽松,而另一些情况下则非常严格,结果展示了所有情况。我们特别关注严格截止时间,并希望避免任何截止时间错过的发生。
6.3.1 与基线的性能比较
图 18展示了在单次迭代控制环路中,使用一个机架上的 60台服务器得到的结果。我们为该机架使用了为期四周的数据轨迹。我们将每个2分钟间隔内所有数据点的总功率值的第95百分位数设为其上限c。在分配本地上限时,我们使用 α= 1。在使用这些轨迹运行协议时,协议观测到了所有峰值。聚合延迟的上界(Laдд)由公式(3)给出,并被设为周期性协议的周期。图 18(a)显示了事件驱动协议和周期性协议的下界松弛量。该图仅绘制了超额订阅幅度大于1.5的情况下的累积分布函数,以便获得更清晰的分辨率,因为在较小幅度时松弛量过大(这些情况并不重要)。由于上限跳闸时间很容易满足,因此我们也省略了相关结果。每种协议的非负下界松弛值表明其能轻松满足跳闸时间要求。因此,使用持续通信(即简单周期性协议)并无优势。
尽管事件驱动协议中的松弛量由于在检测阶段花费了一些时间而比周期性协议的短,但在80%的情况下,事件驱动协议仍能提供超过57.15秒的松弛量,而周期性协议为 57.88秒。这种差异并不显著,因为如图18(b)所示,在所有功率封顶事件中,90%的情况下的检测发生在检测周期的第一个时隙内。只有10%的情况是在检测阶段的第一个时隙之后发生,并且所有检测均在第6个时隙内完成,尽管该阶段总共有60个时隙(对应60台服务器,每台服务器一个时隙)。这些结果表明,CapNet的本地检测策略能够快速确定事件。这也说明实际测得的功耗封顶延迟与公式(5)中推导出的悲观分析值有较大差异 (或更短)。此外,在本实验中,总共94.16%的检测阶段没有来自服务器的任何传输。因此,如果与周期性协议相比,该
需要在网络中持续通信,事件驱动协议至少抑制了94.16%的传输,同时两种协议的实时性能相似。
我们还评估了在数据轨迹中前6次封顶事件期间,使用BoxMAC(TinyOS中的默认基于 CSMA/CA的协议[15])进行功率封顶通信时的性能。图18(c)显示,在执行一次功耗封顶事件的通信过程中,其丢包率超过74%。这是因为所有60个节点同时尝试发送数据,而802.15.4 CSMA/CA在默认设置下的退避周期太短,导致频繁重复碰撞。由于我们丢失了大部分数据包,因此不再考虑CSMA/CA下的延迟。增加退避周期虽可减少碰撞,但会导致较长的通信延迟。在后续实验中,我们排除了CSMA/CA,因为它不适合用于功率封顶。
6.3.2 服务器数量方面的可扩展性
在我们的数据轨迹中,每个机架最多有60台活动服务器。为了测试更多服务器的情况,我们将同一集群中的多个机架合并,因为它们具有相似的功耗模式(正如我们在第6.2节中已经讨论的那样)。为了缩短实验时间,在所有后续实验中,我们将上限设置为第98百分位(这将导致较少的封顶事件)。图19展示了通过分别合并2、4和8个机架得到的120、240和480台服务器的下界松弛分布(针对单次迭代封顶)。因此,即使是480台服务器,单次迭代也能轻松满足截止时间(因为在每种配置中,所有松弛量值均为正值)。
6.3.3 在不同 α下的实验
现在我们使用480台服务器,通过为服务器分配 α的本地上限 α c n进行不同取值的实验。图20中的结果展示了在不同 α下误报率与功耗封顶延迟之间的权衡。当我们把 α的值从1降低到0.80时,误报率从45%到2%下降。这是因为当 α的值减小时,CapNet 在检测潜在事件前会考虑多次告警。请注意,此警报与整个时间窗口相比,功率封顶仅在最多5%的情况下发生,因此该比率非常小。因此,警报也极少产生。由于等待多次告警会增加检测延迟,当 α的值减小时,总功耗封顶延迟随之增加。然而,由于这种延迟的增加仅发生在与总封顶延迟相比可忽略的检测阶段,因此对截止时间丢失率几乎没有影响。图中显示,在 α变化的情况下,截止时间丢失率保持为 0。
6.3.4 控制迭代次数的可扩展性
现在我们考虑一种保守情况,即需要控制回路进行多次迭代才能达到持续功率水平[22, 44, 65]。根据参考文献[65]中的实验,机架级回路在最坏情况下最多可能需要16次迭代(这种情况极为罕见)。因此,我们现在开展实验,考虑多种控制迭代次数(最多16次,假设为悲观场景)。我们在图21中绘制了在不同迭代次数下、不同数量服务器的实验结果。如图21(a)所示,在16次迭代情况下,120台服务器中有13%的情况出现负松弛量,意味着未满足下限跳闸时间。然而,在100%的情况下均满足了上限跳闸时间。请注意,此处我们采用了相当悲观的设置,因为使用16次迭代以及尝试满足行程时间的下限均为非常保守的考虑。对于120台服务器在8次迭代的情况下,有0.13%的情况松弛量为负值。但在80%的情况下,松弛量分别高于4次、8次和16次迭代对应的92.492秒、66.694秒和22.238秒,表明跳闸时间很容易满足,系统可以安全地过度订阅。对于4次迭代,最小松弛量为23.2秒。为了保持图像分辨率,我们未显示上限松弛,因为它们全部为正值。对于480台服务器(图21(b)和(c)),在2次、4次、8次和16次迭代下,分别有98.95%、97.86%、94.93%和67.2%的下限跳闸时间被满足。对于240个节点,在8次迭代下有5%的情况错过截止时间,在16次迭代下有13.94%的情况错过截止时间。
在所有情况下,我们都在100%的案例中遇到了上限跳闸时间。请注意,假设16次迭代并考虑下限跳闸时间是一种非常保守的假设,因为这种情况很少发生。因此,上述
结果表明,即使对于480台服务器,在大多数情况下,CapNet中因功率封顶所产生的延迟仍处于保守的延迟要求范围内。
6.3.5 在变化的封顶值下的实验
到目前为止,我们进行的所有实验中,CapNet 都能够满足上限跳闸时间。现在我们对设置进行一些更改,通过增加超额订阅幅度,使得上限跳闸时间变得更小,从而遇到某些场景。为此,我们现在降低封顶值以缩短跳闸时间,制造可能错过上限跳闸时间的场景,以检验协议的鲁棒性。我们再次将总功率的第95百分位数设为封顶值。由于更小的封顶值意味着更大的过载程度,这会使之前的封顶事件具有更短的截止时间。为了节省实验时间,我们仅使用了120台服务器及其4周数据轨迹进行测试。图22显示,由于截止时间现在变得更短,我们错过了更多的下限跳闸时间,也错过了一些上限跳闸时间。然而,在8次和16次迭代下,分别仅有0.11%和1.02%的情况错过了上限跳闸时间,而下界截止时间在4次、8次和16次迭代下分别有2.14%、6.84%和26.56%的情况被错过。最多至3次迭代时所有截止时间均被满足(图中未显示)。我们仅展示了较高迭代次数下的结果,这些情况很少发生。结果表明,即使在更大的过载程度下,该协议仍具有良好的鲁棒性,例如在使用16次迭代时,仅有1.02%的上限跳闸时间被错过。
6.3.6 多个集群存在情况下的实验
我们通过图17(c)中的数据中心轨迹分析表明,两个集群同时超过封顶值的概率不超过0.0056。然而,在本节中,我们将从悲观视角进行一些实验。具体而言,我们进行了一项实验,观察在干扰集群存在的情况下CapNet的性能表现。
我们通过以下方式模拟一个由480台服务器组成的干扰集群。我们选择一个邻近集群,并在机架中放置一对传感器节点:一个位于机架顶部(ToR),另一个位于机架内部。我们将它们的发射功率设置为最大值(0dBm)。位于ToR的传感器节点代表其管理器,并以真实管理器控制480台服务器的方式进行通信。机架内的传感器节点则响应,仿佛它连接到了全部480台服务器中的每一台。具体而言,管理器执行一个持续 100 ∗480ms的检测阶段,而机架内的节点在 1到480之间随机选择一个时隙。在该时隙内,它以5%的概率生成一个警报,因为封顶情况的发生不超过5%的情况。每当管理器接收到警报时,它就会产生一次通信突发,其模式与实际处理 480台服务器时相同。完成此通信模式后,管理器恢复检测阶段。
我们使用4周数据轨迹运行主集群(实验所用系统),并在图23中绘制结果。图23(a)显示了在有干扰和无干扰情况下(当没有其他集群时)4周数据中不同限电事件的延迟。在存在干扰集群的情况下,延迟大多会增加。这是因为事件驱动协议经历了丢包,并通过重传来处理这些丢包,从而增加了网络延迟。虽然最大延迟增加了124.63秒,但在80%的情况下,延迟增加小于15.089秒。我们注意到,这种较大的延迟增加是由于检测阶段中的警报丢失,导致检测推迟到下一阶段(即阶段长度为48秒)。尽管如此,在所有情况下功率封顶均成功,除非控制广播丢失。在375个事件中,有4次广播即使经过2次重复仍在某些服务器上丢失,导致1.06%的情况发生控制失败。在多迭代情况下,该值变为0。对于多迭代情况,至少有一次控制广播成功,因此因控制消息丢失而导致的限电失败为零。然而,由于检测阶段中传输失败与恢复引起的延迟增加,我们遇到了限电失败。在16次迭代中,40.27%的情况下错过了行程时间的上限以及32.08%的情况下错过了行程时间的下限。然而,我们在此使用了一个保守假设。对于4次迭代,丢失率为5.06%和8.26%。而对于2次迭代,丢失率仅分别为2.13%和2.4%,非常轻微。结果表明,即使在干扰下,CapNet在满足功率封顶的实时要求方面仍表现出良好的鲁棒性。
6.3.7 处理节点故障
请注意,对于每个功耗封顶管理器,都有一个预先指定的位于附近机架的备用功率限制管理器,当该管理器发生故障时,将接管其服务器的管理。功耗封顶管理器使用一个独立的802.15.4无线电,通过一个不同于两个集群中服务器通信所用的信道,与它的备份管理器进行通信。注意,一个管理器B可以周期性地向其备份管理器(例如,A)发送心跳信号。如果A在一定时间窗口内未收到特定数量的心跳信号(即,在一定时间窗口内没有收到任何心跳),则会判定B已发生故障。由于我们并未实际设计配备两个无线电的管理器硬件,在实验中,我们模拟了管理器B发生故障、管理器A接管B的服务器管理的情景。我们希望评估在此情景下B的服务器上的性能表现。我们选取了由B管理的120台服务器,并分析它们为期4周的数据。A拥有另一组120台服务器。A使用20信道,B使用26信道。两个集群均采用8次迭代控制。
为了模拟故障,我们关闭 B。然后A发起故障转移过程,步骤如下:首先,A要求其自身的服务器切换到B的信道,并且自身切换到B的原始信道,同时要求B的节点加入。所有广播重复 2次。图24显示了B的120台服务器在整整4周内的下界松弛量的累积分布函数。大约50%的情况下延迟非常长,因为在这些情况下,A除了管理自身的120台服务器外,还需管理A B的120台服务器B。少数情况下错过了下界截止时间,这是由于额外的通信以及在加入A的集群过程中所花费的时间导致的。然而,在所有情况下均满足了上界截止时间。这些结果
表明在CapNet协议中可以处理功率管理器故障场景,而不会导致严重的性能下降。
7 讨论与未来工作
尽管本文讨论了可行性、协议设计与实现,但作为信息物理系统,未来仍需研究一些工程挑战,例如闭环控制回路、安全性、电磁干扰(EMI)和合规性等问题。
7.1 使用控制理论闭合反馈回路
我们开发了基于无线网络的功率封顶网络协议。此类系统的性能可以通过信息物理协同设计方法进行优化,即通过将数据中心功耗封顶系统设计为一个信息物理系统[46]。这种信息物理协同设计框架可以基于控制理论方法[47]来构建。通过这种方法,相比现有研究中针对单服务器[41]以及基于有线网络的集群级功率封顶[64]所采用的启发式解决方案,能够实现更精确的功率封顶。因此,在无线网络上基于反馈控制理论实现CapNet是一项具有前景的未来工作。具体而言,假设一个集群中有m台服务器,编号为1, 2, 3, …, m。为了建模功耗,令pi(k)表示服务器i的功耗,fi(k)表示时间k时服务器i的处理器频率级别。上限(设定点)为c。在时间k时集群的总功耗为paggr(k) =∑ m i=1 pi(k)。图25展示了该集群的反馈回路架构。控制目标是保证paggr(k)在调节时间(稳定时间)内收敛到c。我们可以利用文献[65]中研究的被控变量paggr(k)与操纵变量fi(k)之间的关系,并将系统的动态模型表示为(矩阵形式)
p(k+ 1)= p(k)+ Aδf(k),
其中 p(k)=[p1(k), …, pm(k)] T; δf(k)=f(k) ‐ f(k‐1)=[δf 1(k), …, δfm(k)] T。
7.2 将CapNet扩展到功率封顶之外
尽管我们的工作仅考虑了功率封顶管理,但企业数据中心需要多种管理功能。大规模数据中心的持续、低成本和高效运行在很大程度上依赖于其管理网络和系统。这些管理功能包括开关服务器、主板传感器遥测、冷却管理、各种其他电源管理、温度和湿度控制,以实现更佳且更安全的服务器运行。诸如系统重映像、网络配置、(虚拟)机器分配以及服务器健康监控等高级管理功能[17, 34] dependlargely此类管理功能。因此,在未来,我们希望将CapNet扩展为包含所有此类管理功能,作为工业物联网的一个重要类别[60]。
测量数据中心内部的温度和湿度分布有多种方法。许多现代服务器还配备了多个板载传感器,用于监控中央处理器、磁盘和I/O控制器等关键服务器组件附近的热状况。这些传感器用于检测并防止因过热导致的硬件故障。一些新型服务器还在进气口处配备了温度传感器,我们的系统可以利用这些传感器来估计机房环境条件。现代服务器硬件具有内置的功耗计量能力(例如,使用基于主板或电源的功率传感器)。如前所述,为了使CapNet 更有效,未来的服务器应在主板上设计嵌入式无线芯片。因此,所有这些传感器都可以集成到同一个CapNet框架中,以包含所有此类监控功能。将数据中心的所有管理和监控功能集成到一个框架中,可以利用我们之前关于支持多种应用的共享无线传感器网络的研究成果[23, 68]。
7.3 双层架构
未来,我们计划通过第二层网络将CapNet扩展至整个数据中心,其中所有集群的功率封顶管理器通过电视频谱白空频段连接 [54–56]。电视 白空指的是已分配但未使用的电视频道,无许可设备可作为次要用户使用这些频段 [9, 10]。它们能够轻易穿透障碍物,因此在需要长传输距离的无线传感器网络应用中具有巨大潜力。由于白空频段几乎 everywhere 都可用,尤其是在室内环境中,并可用于长距离通信 [21],因此,我们能够在单跳网络内覆盖现有任何数据中心内的所有功率封顶管理器。因此,白空频段网络可能是无线DCM的一种有前景的方案。我们最近设计的白空频段传感器网络(SNOW)已证明可在长距离上实现大量传感器与基站之间的异步、低功耗、双向和大规模并发通信 [52, 54–56]。因此,未来我们将探索采用SNOW技术作为无线DCM的低功耗广域网。
7.4 安全性和弹性
CapNet 的一个关键挑战和局限性在于它引发了数据中心管理系统的安全性问题。由于该系统依赖于无线控制,可能会有人恶意接入无线网络并接管数据中心。如上所述,使用低功耗广域网技术进行数据中心管理可能会加剧这一安全问题,因为其无线通信具有长距离传输能力,信号可传播


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









