




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 中国开源大模型MiniMax-M2
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在人工智能的竞技场上,过去几年的主旋律一直是“军备竞赛”——参数更大、模型更强、算力更猛。从GPT-4到Claude 4,再到Grok-4,科技巨头们不惜血本地投入,打造出一个个性能惊人的“巨无霸”。然而,强大性能的背后,是普通开发者和中小企业难以承受的昂贵价格标签。百万Token(可以理解为AI处理文字的单位)动辄10到15美元的费用,让许多创新应用望而却步。
就在大家似乎默认“高性能AI=高成本”这条规则时,2025年10月,来自中国的AI独角兽公司MiniMax(稀宇极智)向牌桌上扔出了一张可能改变游戏规则的牌——正式发布并开源其新一代文本大模型MiniMax-M2。
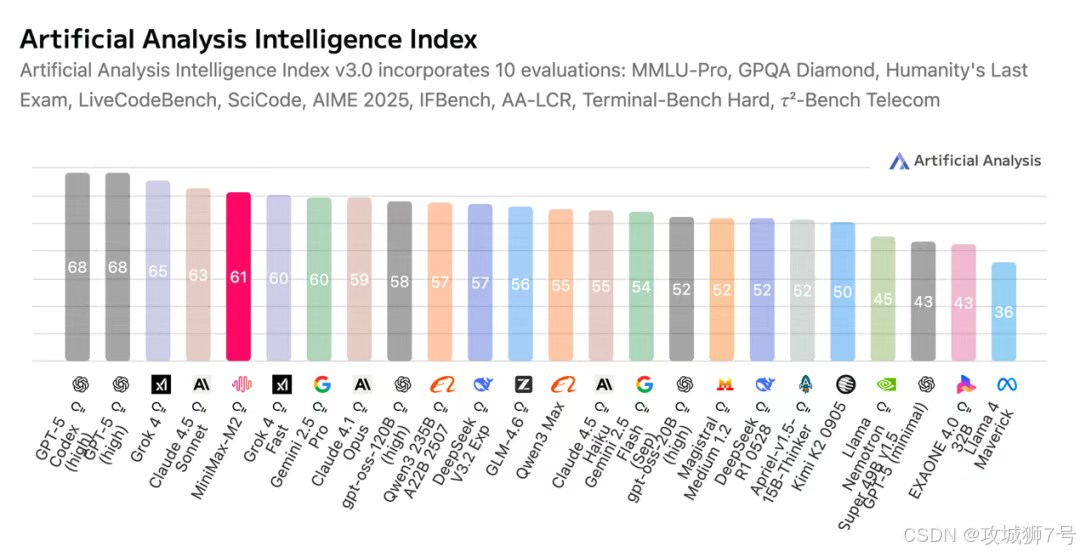
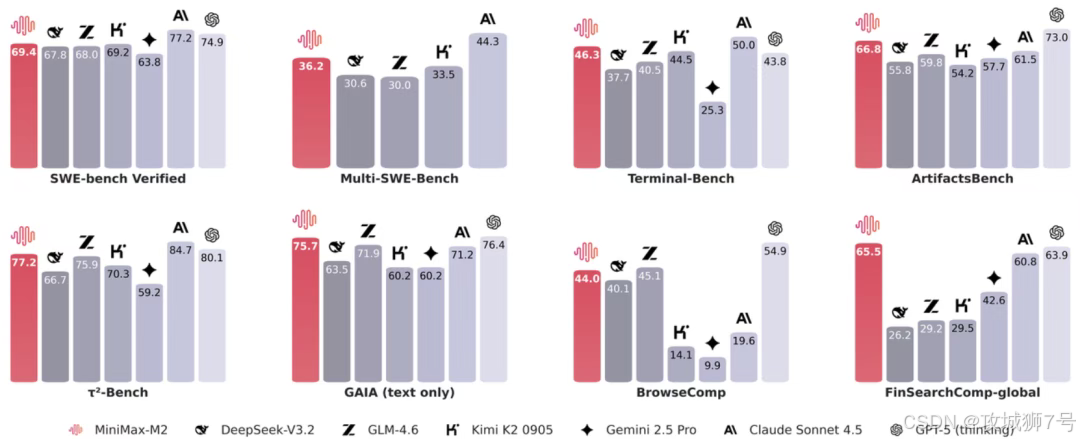
M2的口号响亮而直接:用不到Claude Sonnet 4.5模型8%的价格,实现与之相当的性能和更快的速度。这究竟是夸下海口,还是 gerçek的实力?
一、性能“亮剑”:不只是便宜货
要挑战现有格局,光靠低价是不够的,性能必须“能打”。M2在发布之初,就用一系列权威榜单的成绩证明了自己并非等闲之辈。
在全球知名的AI模型评测榜单Artificial Analysis (AA)上,M2的总分冲入全球前五,在所有开源模型中排名第一,甚至超越了谷歌的Gemini 2.5 Pro和Anthropic的Claude 4.1等闭源强手。
M2并非一个“偏科生”,而是一个专注于未来趋势的“特长生”。它的设计核心,是为当前最热门的两大应用场景——AI智能体(Agent)和代码生成——进行深度优化。
强大的智能体(Agentic)表现:它能出色地规划并稳定执行复杂的、长链条的任务,比如协同调用浏览器进行深度资料搜索,或是在电脑终端(Shell)执行命令。
优异的代码能力:它专为端到端的开发工作流打造,能够处理多个代码文件,执行从“编码”到“运行”,再到“调试”的完整循环,甚至通过测试来自动修复代码中的错误。
在实际测试中,M2在金融搜索基准测试中位列全球前二,仅次于马斯克的Grok-4;在深度搜索能力测试中,同样位列全球前二,仅次于GPT-5。这一系列的成绩单清晰地表明,M2的智能水平已经稳稳站上了全球第一梯队。
二、成本“破壁”:AI普惠的“中国方案”
如果说M2的性能是对标硅谷,那么它的价格则堪称“掀桌子”。
在性能旗鼓相当的情况下,MiniMax将M2的API服务价格定在了每百万Token输入0.3美元,输出1.2美元。综合下来,其使用成本不到GPT-5的12%,更是不到性能相近的Claude 4.5 Sonnet的8%。
这种极致的性价比,对于广大开发者和企业来说,意味着AI应用的门槛被前所未有地拉低了。过去需要高昂预算才能支撑的应用,现在可以用极低的成本来运行和迭代。M2的出现,让高性能AI不再是少数巨头的专属,而是真正开始走向普惠。
三、技术揭秘:如何做到“又好又便宜”?
M2实现“性价比奇迹”的背后,是其巧妙的技术架构和清晰的战略取舍。
3.1 核心武器:MoE架构
M2采用的是目前非常流行的MoE(Mixture of Experts,专家混合)架构。你可以把它想象成一个庞大的“专家智库”,而不是一个“全才”。
传统的模型在处理任何任务时,都需要调动体内全部的参数,就像一个公司,无论大事小事,所有员工都得一起上阵。而M2的总参数量虽然高达2300亿,但在处理任何一个任务时,它只会“唤醒”其中约100亿参数的“相关专家”来解决问题。
这种“按需激活”的设计,让它在保持强大能力的同时,极大地降低了计算开销,从而在性能、延迟和成本之间取得了绝佳的平衡。
3.2 战略进化:从M1到M2的“自我否定”
有趣的是,M2的技术路线,甚至是 对其前代产品M1的一次“否定”。
MiniMax在几个月前推出的M1模型,主打的是百万级Token的超长文本处理能力,其采用的是自创的“混合注意力”机制。但在实践中,团队发现这种架构虽然在处理长文档时表现出色,但在面对需要多步骤、长链条推理的Agent任务时,表现不够稳定。
于是,MiniMax果断地为M2选择了更适合执行型任务的“全注意力+MoE”路线,把所有资源都集中在代码生成、工具调用等Agent核心能力上。这并非简单的技术迭代,而是团队为了平衡不同应用场景所做的清晰取舍——M1强调“能想很久、能读很长”,而M2则强调“能执行、且便宜”。
四、真实世界评测:是“王者”还是“偏科生”?
榜单数据固然亮眼,但在真实的应用场景中,M2的表现又如何呢?一些开发者用它和同级别的Claude Sonnet 4.5进行了对比测试。
4.1 第一轮:制作元素周期表网页
(1)M2:耗时约20-30分钟,中间失败了一次。最终成品非常惊艳,设计美观,功能丰富(搜索、筛选、交互卡片)。但有硬伤:最重要的元素数据展示不完整,且搜索功能有Bug。
(2)Sonnet 4.5:速度飞快,3-4分钟搞定。成品简洁明了,118个元素展示完整。但功能相对单一,只有基本的点击查看信息功能。
4.2 第二轮:制作俄罗斯方块游戏
(1)M2:耗时约20分钟。成品同样设计美观,功能齐全(计分、暂停、下一个图形提示)。但存在一个关键Bug:方块不能自动下落。
(2)Sonnet 4.5:半分钟就制作完成。游戏功能完整,运行流畅,没有任何Bug。
从这些测试可以看出,M2和Sonnet 4.5各有千秋。Sonnet 4.5更像一个稳定可靠的“老手”,速度快,核心功能完成度高,但缺乏惊喜。M2则更像一个才华横溢但略显毛躁的“天才”,它的想法更多,设计更出彩,但稳定性和准确性上还有待打磨。
不过,考虑到M2不到8%的价格,却能交付出八九成的质量,甚至在创意上偶有超越,这个“性价比之王”的称号,可以说是实至名归。
结语:从“中国制造”到“中国创造”
M2的发布,其意义已经超越了一款模型本身。它背后折射出的,是中国AI在全球科技版图中的“角色变迁”。

就在不久前,Meta(Facebook母公司)发布的强化学习论文中,大规模采用了MiniMax原创的算法,并承认其是推动技术突破的关键。从底层算法被国际巨头采纳,到今天M2模型以“性能-成本”双重优势开源,我们看到了一条清晰的轨迹:中国AI正在完成从“应用模仿”到“算法原创”的战略转变。
M2的开源,正是一种“算法自信”的体现。它用一份独特的“中国方案”,向世界证明了高性能AI可以不必那么昂贵。未来,在全球开发者的手中,这款高性价比的模型将如何“开花结果”,值得我们拭目以待。
MiniMax-M2的开源地址为:https://huggingface.co/minimaxai/minimax-m2
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











