




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阿里通义开源Qwen3-Omni
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
AI领域一直在追逐一个梦想:创造一个像人一样,能同时看、听、说、思考的“全能”模型。最近,阿里巴巴通义千问团队朝着这个目标迈出了重要一步,开源了新一代原生全模态大模型——Qwen3-Omni。
从官方发布的资料来看,Qwen3-Omni的成绩单堪称华丽:在36项音视频基准测试中,32项拿到开源模型最佳,22项达到SOTA(业界顶尖)水平。更关键的是,它宣称在增强音视频这些“新才艺”的同时,传统的文本和图像“主科”成绩没有下滑,做到了“全模态不降智”。
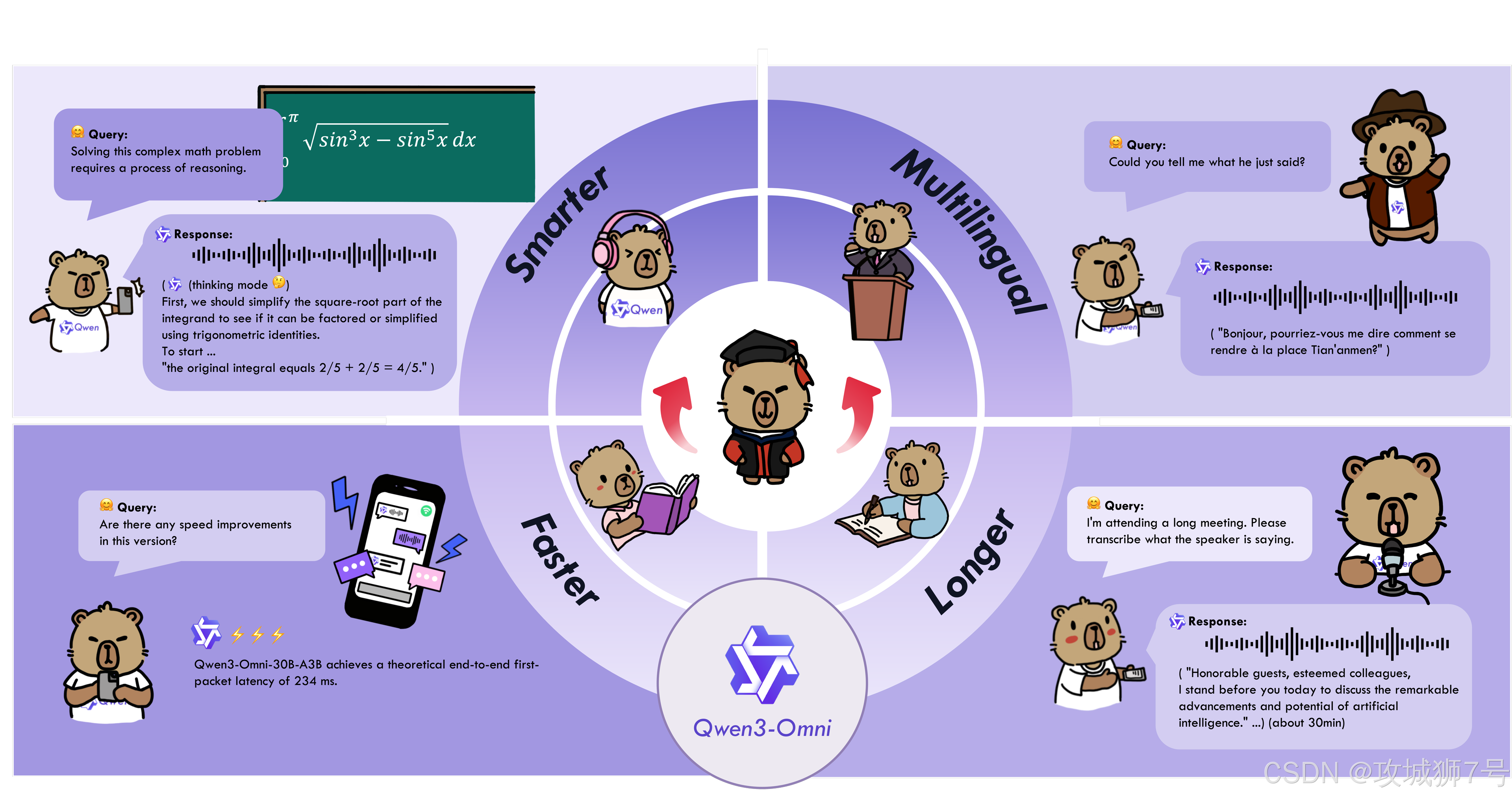
这听起来非常诱人。但它究竟是如何做到的?在真实的聊天场景中,它的表现真的和“跑分”一样惊艳吗?让我们一起来深入了解一下。
一、拆解Qwen3-Omni:如何做到“一心多用”还不乱?
要让一个模型同时处理多种类型的信息,还要保证各项能力都拔尖,最大的挑战就是避免“模态权衡”——也就是为了提升A能力,不得不牺牲B能力。Qwen3-Omni给出的解决方案,是一个名为“思考者-表达者”(Thinker-Talker)的创新架构。
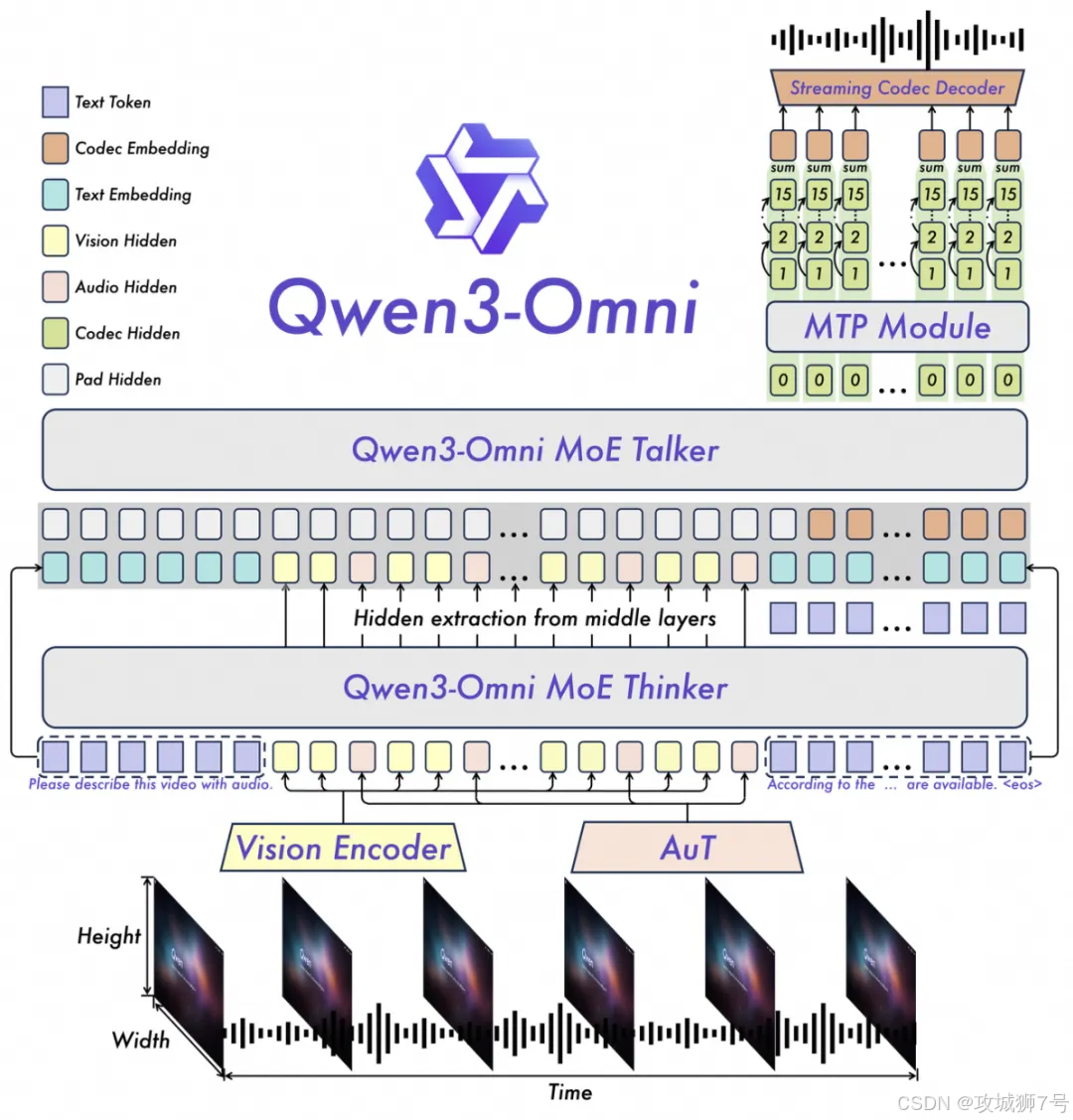
这个名字很形象,我们可以把它理解为一次精巧的“团队分工”:
(1)思考者(Thinker):这是模型的“大脑”,基于混合专家(MoE)架构。它专门负责最核心的逻辑、知识和推理,也就是理解你输入的文字、图片、视频背后到底是什么意思。因为它专注于语义理解,所以模型的“智商”基本盘就稳住了。
(2)表达者(Talker):这是模型的“嘴巴”,同样基于MoE架构。它不直接处理复杂的逻辑,而是接收来自“大脑”(Thinker)处理好的高层语义信息,然后专注于一件事——如何把这些意思用流畅、自然的语音实时说出来。
除了这个核心分工,它还配备了强大的“感官”系统:
* 视觉:强大的视觉编码器,能同时处理图像和视频。
* 听觉:自研的AuT音频编码器,用2000万小时的数据训练,听力超群,能支持长达30分钟的音频输入。
这种“各司其职”的设计,解决了两个核心痛点:一是保证了核心理解能力不掉线;二是让语音生成可以做到流式输出,延迟极低(官方数据是音频对话延迟低至211毫秒),听起来就像和真人聊天一样。
二、纸面上的“全能选手”有多强?
基于这套架构,Qwen3-Omni展现出了非常全面的能力:
(1)语言覆盖广:支持119种文本语言,19种语音输入和10种语音输出,还能说粤语、四川话等多种方言。
(2)功能强大:支持长音频理解(会议纪要、课程转录)、工具调用(Function Call,可以操作外部API)、个性化定制(通过系统提示词设定人设)等高级功能。
(3)版本灵活:除了强大的30B(300亿参数)主版本,还提供了一个轻量的Flash版,降低了使用门槛。
总而言之,从技术报告和官方介绍来看,Qwen3-Omni在架构设计和性能指标上都展现了顶级的实力,是一个非常亮眼的开源多模态模型。
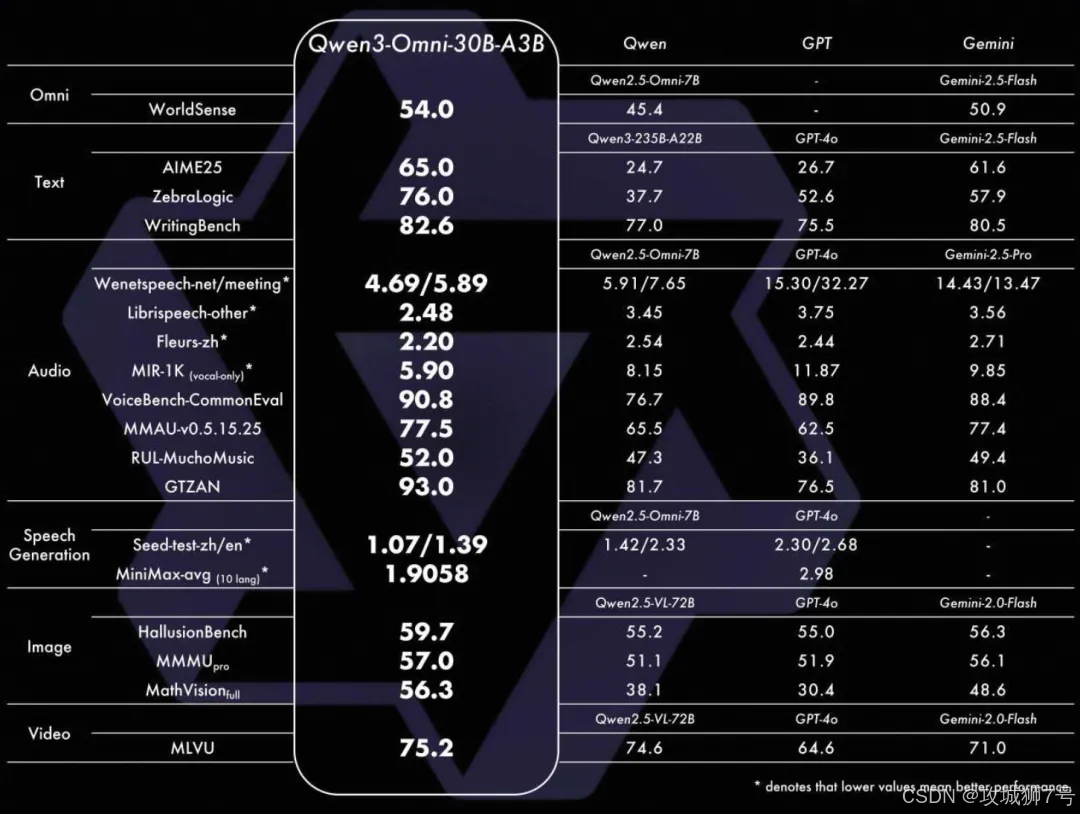
Omni-30B-A3B 性能图
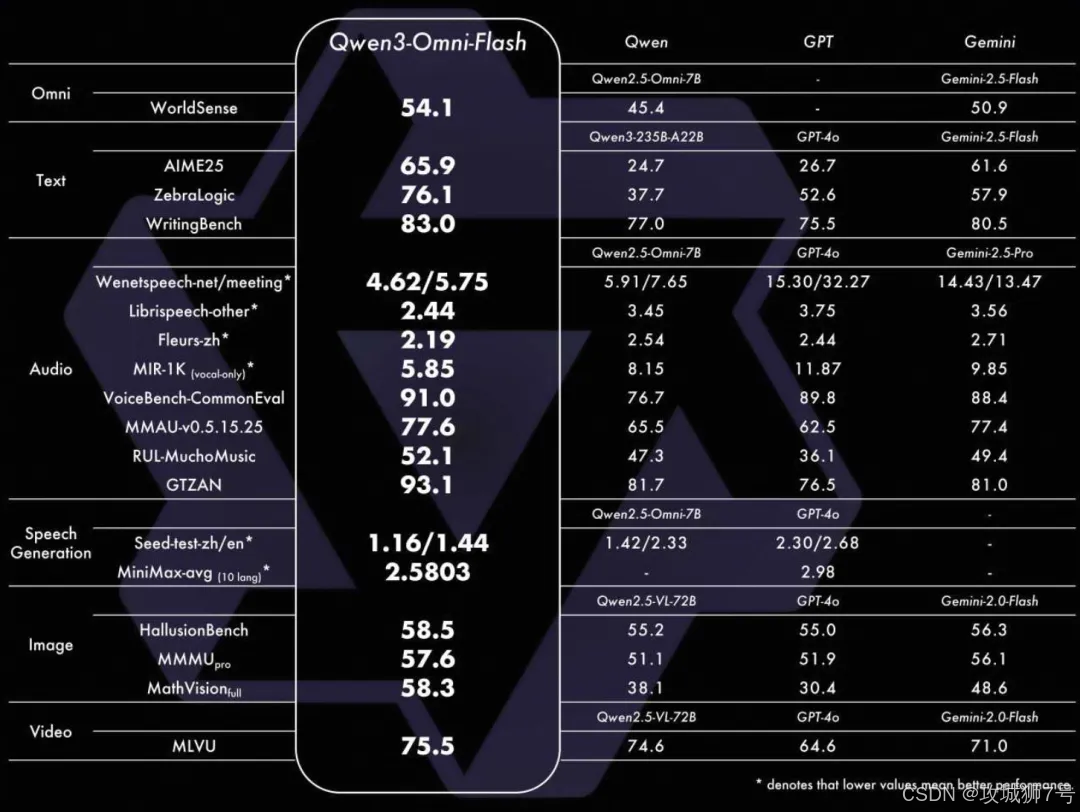
Qwen3-Omni-Flash 性能图
三、理想与现实:当“跑分学霸”走进真实对话
然而,基准测试的“高分”能完全等同于用户体验的“高分”吗?
就在Qwen3-Omni发布后,AGI-Eval大模型评测社区对其进行了一次专注于真实交互场景的专项评测。这份评测报告,为我们揭示了“理想”与“现实”之间的差距。
评测团队设计了覆盖共情、学习、娱乐、解决问题等多个生活化场景,邀请多位测试员与模型进行实时的音视频对话。结果可能有些出人意料:在满分3分的“自然流畅度”打分中,Qwen3-Omni的平均分只有0.37分。
问题主要出在以下几个方面:
(1)交互混乱,像个“社牛”,但不受控制
* 语言“漂移”:在中文对话中,模型会毫无征兆地切换到英语甚至俄语,即使用户要求换回来,它也可能“一意孤行”。
* 人称错乱:分不清“你”和“我”。比如,用户在编辫子,问模型“我在干什么?”,模型回答:“对,我正在编头发呢。”
(2)认知偏差,逻辑时常“掉线”
* 答非所问:当用户咨询社交问题时,模型突然开始用英文聊起了2022年世界杯。
* “幻觉”频现:在对话中,会无视用户的语音,突然开始评论用户的外貌(“你头发看起来很茂密呢”),或者在用户没有展示任何东西时,开始编造一份不存在的医疗报告。
(3)核心能力存在短板
* 动态捕捉失效:几乎无法识别视频中的连续动作,比如模仿动物或猜纸球在哪只手。
* 静态识别错误率高:连用户伸出几根手指这么简单的任务都无法正确识别,更不用说病例报告单上的文字了。
* 短期记忆差:对话进行到一半,很容易忘记之前的上下文和任务目标,比如忘记了正在玩的游戏规则。
结语:一个重要的里程碑,也是一次深刻的警示
那么,我们该如何看待Qwen3-Omni的这种“矛盾”表现?
首先,必须肯定的是,Qwen3-Omni在技术架构上的创新和其在基准测试上的优异表现,是多模态领域一个重要的里程碑。它向我们展示了“原生全模态”的巨大潜力,并且通过开源,极大地推动了整个社区的技术进步。
然而,AGI-Eval的评测报告也给了整个行业一个深刻的警示:基准测试的胜利,与一个用户真正觉得好用、可靠的产品之间,依然存在着巨大的鸿沟。
当模型走出设定好题目的“考场”,进入开放、动态、需要深度理解上下文的真实世界时,交互的稳定性、认知的准确性、记忆的持久性这些基础能力,才是决定其价值的基石。
Qwen3-Omni的案例,让我们更清醒地认识到,AI的发展道阻且长。从“SOTA”(State-of-the-Art,顶尖水平)到“Usable”(可用),再到“Reliable”(可靠),每一步都需要克服无数的挑战。而正视这些挑战,正是推动技术不断向前的关键所在。
💻 GitHub开源地址
https://github.com/QwenLM/Qwen3-Omni
🤖 模型库
https://modelscope.cn/collections/Qwen3-Omni-867aef131e7d4f
🎬 在线Demo试玩
https://chat.qwen.ai/?models=qwen3-omni-flash
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 817
817





 到【灌水乐园】发言
到【灌水乐园】发言









