




目录
二、LLaSO的“三板斧”:一套开源的“数据+考场+范本”组合拳
2.1 第一板斧:LLaSO-Align & Instruct —— 不仅要“听懂”,更要“听透”
2.2 第二板斧:LLaSO-Eval —— 打造一个公平的“标准化考场”
2.3 第三板斧:LLaSO-Base —— 一个用于“打样”的强大参考模型
三、实战检验:在“标准考场”上,LLaSO-Base表现如何?
四、 LLaSO的真正意义:不止于一个模型,而是一套“基础设施”

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 逻辑智能开源LLaSO
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:语音大模型为何陷入发展瓶颈?
你是否想过,未来的语音助手不仅能听清你的指令,还能从你疲惫的语气中察觉到“你该休息了”?或者在你口述一段会议录音后,它不仅能生成文字稿,还能自动分析出谁在会上情绪激动,谁又在敷衍了事?
这些场景的实现,都依赖于大型语音语言模型(LSLM)的进步。然而,相比于图像、文本大模型领域的日新月异,语音大模型的发展一直显得有些“混乱”和“缓慢”。
这个领域长期被四大难题所困扰,就像一群武林高手,虽然各有神功,但因为没有统一的度量衡和比武规则,谁也说不清谁更强,也难以互相学习借鉴:
(1)技术路线分化:各家采用的架构五花八门,没有一个公认的、效果最好的“标准范式”。
(2)训练数据私有:许多顶尖模型都依赖私有的海量数据进行训练,就像秘不外传的武功秘籍。这导致其他研究者无法复现,也搞不清模型的强大究竟是来自算法创新,还是单纯的“数据堆料”。
(3)任务范围局限:现有的大部分公开数据,只关注“语音转文字”这种基础任务,却忽略了语音中更丰富的信息,比如情感、口音、语调和说话意图等“弦外之音”。
(4)交互模式单一:大多数模型只支持“用文字下指令,让模型分析音频”,很少能处理更自然的纯语音对话。
这些问题共同导致了研究的“碎片化”,大家各说各话,系统性的技术突破变得异常困难。
一、“规矩制定者”登场:LLaSO框架是什么?
为了打破这一僵局,来自北京深度逻辑智能科技的研究团队推出了LLaSO——全球首个完全开放、端到端的语音大模型研究框架。

如果说之前的语音AI领域是一个混乱的江湖,那LLaSO的目标就是为这个江湖“立规矩”。
它不是简单地发布一个更强的模型,而是革命性地提供了一个“全家桶”,里面包含了研究语音大模型所需的一切基础资源:海量且高质量的开源数据、统一且全面的评测基准、一个强大且可复现的参考模型。
LLaSO的出现,旨在为整个行业铺平道路,让所有人都能站在同一条起跑线上,用同样的“尺子”去衡量彼此的进步,从而加速整个领域的创新。
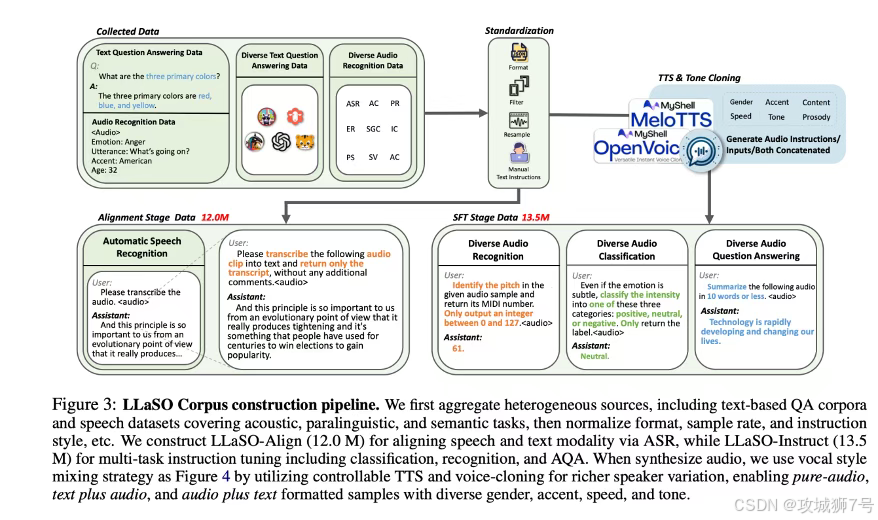
二、LLaSO的“三板斧”:一套开源的“数据+考场+范本”组合拳
LLaSO的解决方案,可以概括为三记强有力的“组合拳”,分别解决了数据、评测和参考实现三大难题。
2.1 第一板斧:LLaSO-Align & Instruct —— 不仅要“听懂”,更要“听透”
LLaSO首先解决了最核心的“数据”问题,它提供了两个庞大且精心构建的数据集:
(1)LLaSO-Align(对齐数据集):这是一个包含1200万样本的庞大语料库,专注于“语音转文字”这个基础任务。它的目标是让模型打下坚实的基础,学会将语音信号和文字的语义精准地对应起来。这是模型能“听懂”话语的第一步。
(2)LLaSO-Instruct(指令数据集):这是LLaSO最具革命性的贡献。这个拥有1350万样本的多任务指令库,不再局限于简单的语音转文字。它涵盖了20种不同的语音任务,不仅要识别“说了什么”,更要理解“说话的内涵”,比如:
* 说话人特征识别:判断说话人的性别、年龄、口音。
* 内容深层分析:预测话语意图、提取关键信息。
* 情感与韵律感知:识别语音中的情感色彩。
更重要的是,这个数据集系统性地支持三种交互模式,包括极具挑战性的纯语音对话,让模型能够应对更真实的交互场景。
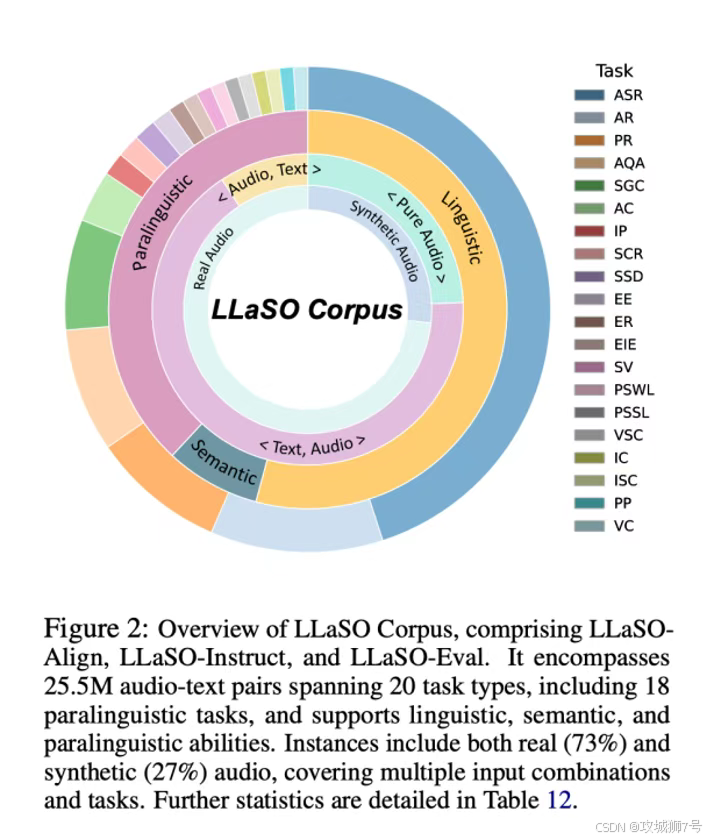
2.2 第二板斧:LLaSO-Eval —— 打造一个公平的“标准化考场”
有了高质量的训练数据还不够,如何公平地评判一个模型的好坏?LLaSO为此推出了LLaSO-Eval,一个包含超过1.5万个样本的“标准化考场”。
在这个考场里,所有模型都必须回答同样的“考卷”,覆盖了LLaSO-Instruct中所有的20种任务。最终的得分高低一目了然,确保了评估的公平性、全面性和可复现性。这彻底改变了过去各家模型“自说自话”、王婆卖瓜式的评测乱象。
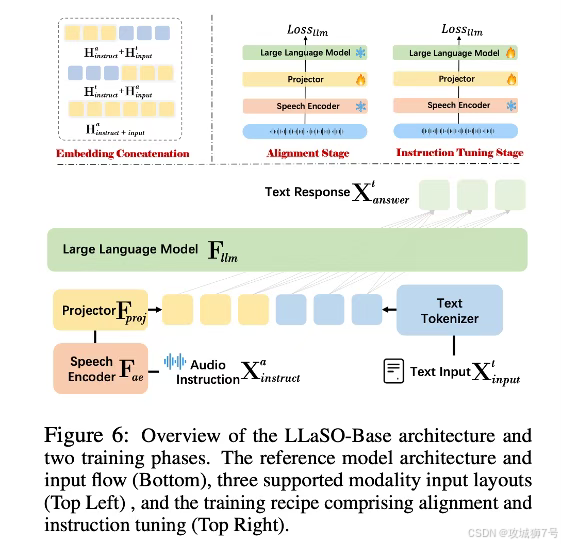
2.3 第三板斧:LLaSO-Base —— 一个用于“打样”的强大参考模型
为了证明自己这套“数据+考场”的框架是切实有效的,团队还训练并发布了一个名为LLaSO-Base的参考模型。
这个拥有38亿参数的模型,其设计目标并非追求性能的极致,而是为了提供一个完全依赖LLaSO公开数据、可被轻松复现的强大基线。它就像一个用标准教材和标准考卷教出来的“优秀范本”,向整个社区展示了:即便不使用任何私有数据,只用我们这套开源的“全家桶”,你也能打造出一个业界顶尖的语音大模型。
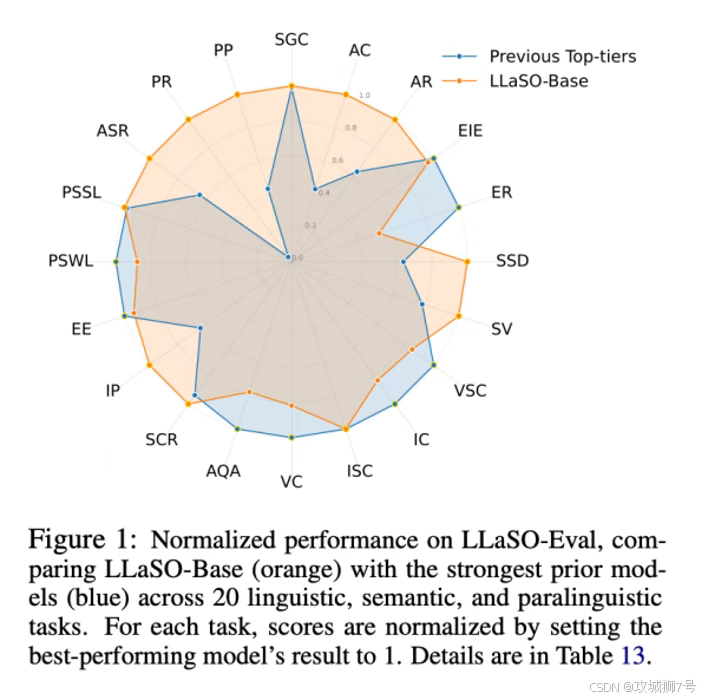
三、实战检验:在“标准考场”上,LLaSO-Base表现如何?
那么,这位“模范生”在“标准考场”上的成绩究竟如何?研究团队将LLaSO-Base与包括Qwen2-Audio、Kimi-Audio等在内的10个业界主流模型进行了正面硬碰硬的比较。
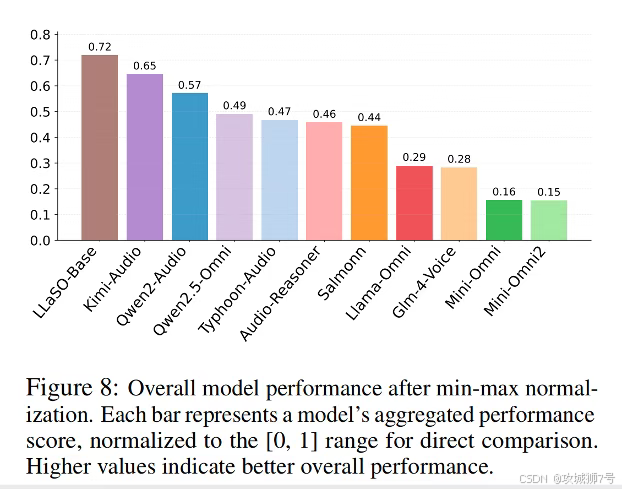
(1)综合实力:全面领先
在LLaSO-Eval的总分上,LLaSO-Base取得了0.72的最高分,位列第一,显著优于表现第二的Kimi-Audio(0.65分)和第三的Qwen2-Audio(0.57分)。这一结果强有力地证明了LLaSO框架的有效性。
(2)单项能力:在“听懂”和“听透”上均表现卓越
在基础的“语音转文字”(ASR)任务上,LLaSO-Base展现了压倒性优势,词错误率和字错误率均为所有模型中最低,证明其“听懂”基本功最为扎实。
在更复杂的“副语言学”任务上(即理解“弦外之音”),LLaSO-Base的优势更为显著。在音素识别、语音命令识别等精细内容分析任务上,其指标以数量级的优势领先于所有对手。
更关键的是,许多其他模型在面对这些复杂任务时,会直接选择“拒绝回答”,而LLaSO-Base几乎从不回避,展现了其强大的指令遵循能力和任务泛化性。
(3)关键发现:任务多样性是王道
实验得出一个极其重要的结论:那些像LLaSO-Base一样,在更多样化的任务上进行训练的模型,其综合性能远超那些只针对少数任务(如音频问答)进行优化的模型。这证明了LLaSO框架所倡导的“广泛任务覆盖”训练策略的正确性和有效性。
四、 LLaSO的真正意义:不止于一个模型,而是一套“基础设施”
LLaSO的发布,其意义远不止是开源了一个强大的模型。它为整个语音AI领域提供了一套前所未有的、完整的、开放的“基础设施”。
它的出现,将带来三大深远影响:
(1)极大降低研究门槛:从此,研究者不再需要耗费巨额成本去收集和标注数据,可以直接在LLaSO提供的世界级数据集上,专注于算法和模型的创新。
(2)建立公平的竞争环境:统一的评估基准让所有模型都能在同一标准下被衡量,良币驱逐劣币,真正推动技术向前发展。
(3)加速社区驱动的创新:当整个社区都基于一个共同的、透明的、可复现的框架进行研究时,技术的积累和迭代速度将呈指数级增长。
可以说,LLaSO正在成为语音大模型领域的“ImageNet时刻”,为整个领域从“各自为战”的混乱时代,迈向“协同创新”的新纪元,奠定了坚实的基础。
结语:从“听见”到“听懂”,语音AI的新篇章
LLaSO的出现,为那个能听懂我们“弦外之音”的未来,铺平了道路。它通过彻底的开放和共享,打破了长期以来阻碍创新的壁垒。
我们有理由相信,在这个“全家桶”式开源项目的催化下,语音大模型的下一波创新浪潮即将到来。一个真正懂你、懂我、懂人心的AI语音应用,正变得前所未有的清晰和可能。
论文地址:https://arxiv.org/abs/2508.15418v1
代码地址:https://github.com/EIT-NLP/LLaSO
模型地址:https://huggingface.co/papers/2508.15418
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



























 到【灌水乐园】发言
到【灌水乐园】发言









