



目录
四、ToonComposer的意义:解放创造力,而非取代创造者

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 AI动画制作工具:ToonComposer
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:一张画稿生成一部动画
如果你曾对动画制作稍有了解,或者仅仅是看过一些动画的幕后花絮,你一定会被那个庞大而繁琐的工程所震撼。一部短短几分钟的动画短片,背后可能是由成百上千张独立画稿组成的“帧的海洋”。从确定关键动作的“关键帧”,到填补动作之间空白的“中间帧”,再到为每一帧上色,这个过程充满了大量重复、耗时且考验耐心的劳动。这道高墙,不仅将无数充满热情的爱好者挡在门外,也常常让专业的动画工作室在人力与时间成本的压力下举步维艰。
然而,一场由AI驱动的变革正在悄然发生。近日,由香港中文大学、腾讯PCG应用研究中心(ARC Lab)和北京大学的学者们联合推出的一款名为 ToonComposer 的工具,正试图彻底颠覆这个传统的工作流程。它提出的核心理念听起来就像是来自未来:动画师只需要提供一张彩色的参考图来定下风格,再加上几张关键的动作草图,ToonComposer就能自动生成一段完整、流畅且风格统一的高质量动画。
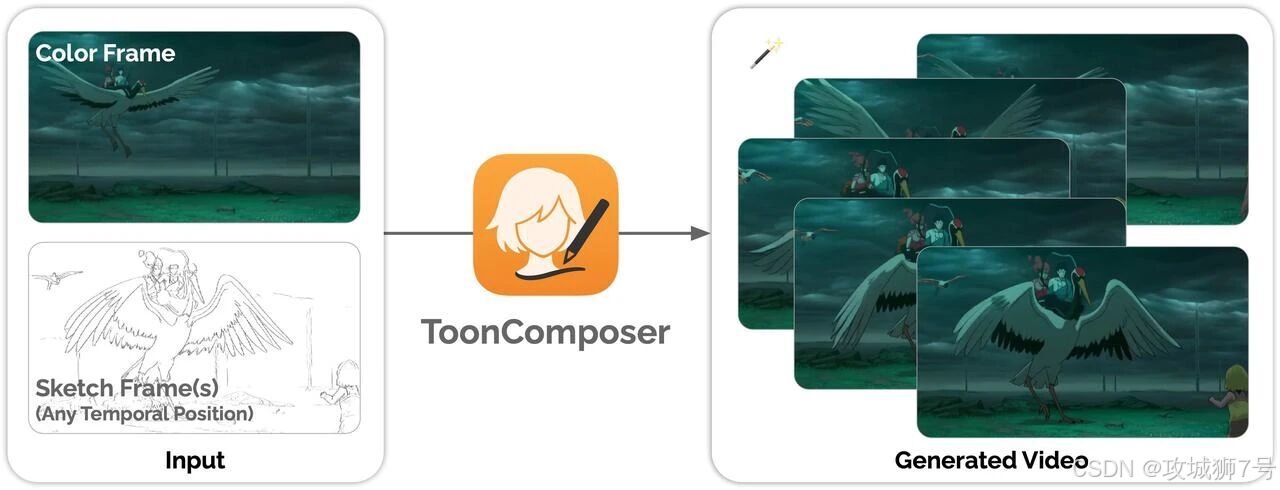
这不仅仅是一个简单的工具,它代表了一种全新的创作范式。本文将深入探讨ToonComposer是如何工作的,它背后的“黑科技”是什么,以及它将为动画行业乃至整个创意领域带来怎样的深远影响。
一、告别“接力赛”:动画制作的百年痛点
要理解ToonComposer的革命性,我们首先需要回顾一下传统动画(乃至此前AI辅助动画)的工作模式。这个流程可以被比作一场“接力赛”:
(1)第一棒:关键帧绘制。这是最具创造性的环节。资深动画师会画出动作的起点、终点以及最核心的几个姿态,这决定了动画的“灵魂”。
(2)第二棒:中间帧生成。这是最繁重的环节。动画师或AI工具需要在这几个关键帧之间,补充绘制大量的“中间帧”,以确保动作看起来连贯流畅。这个过程的工作量极大,AI虽然可以辅助,但往往会产生瑕疵或动作僵硬的问题。
(3)第三棒:上色。这是最后也是极为耗时的环节。每一帧都需要被精确地上色,并且要保证所有帧的色彩风格、光影完全统一。

这个“接力赛”模式最大的问题在于,误差会逐棒传递和放大。中间帧的生成如果稍有偏差,上色环节就可能出错;而如果将这两个环节交给不同的AI工具处理,风格不统一、动作断层等问题几乎无法避免。最终的结果就是,动画师需要花费大量时间去修复这些由分步处理带来的瑕疵。
ToonComposer的思路则完全不同。它不做“接力赛”,而是要成为一个“全能运动员”,将第二棒(中间帧)和第三棒(上色)合并为一个统一、同步的自动化流程。这就是其核心概念——“生成式后关键帧(Generative Post-Keyframing)”。
在这个新流程下,动画师只需要完成第一棒的创意工作,把“接力棒”(关键帧草图和风格参考)交给ToonComposer,它就能一口气冲向终点,生成最终的成品。这个端到端的模型同时理解动作的连续性和色彩的风格,从根本上避免了分步处理带来的误差累积问题。
二、ToonComposer背后的三大“黑科技”
那么,ToonComposer是如何实现这一强大功能的呢?它的背后,是基于先进的Diffusion Transformer(一种强大的视频生成模型)并在此之上进行的三项关键技术创新。
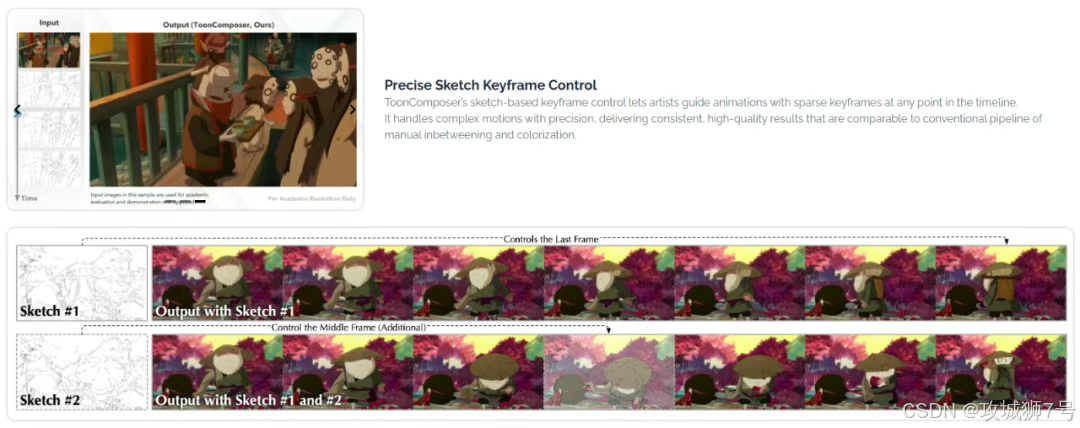
(1)稀疏草图注入机制 (Sparse Sketch Injection):让AI“读懂”你的草图
这可能是最核心的技术。我们如何让AI精确地理解动画师画的几张简单草图,并将其作为整个动画的“骨架”来指导运动?
“稀疏草图注入”机制就解决了这个问题。你可以把它想象成给AI一张带有时间戳的地图。当动画师提供一张草图时,他可以指定这张草图应该出现在动画的第几秒(或第几帧)。ToonComposer通过一种“位置编码映射”技术,将这个时间信息和草图的视觉特征“绑定”在一起,然后“注入”到视频生成模型的处理流程中。
这样一来,AI就不再是盲目地模仿草图的画风,而是能够精准地理解:“哦,在第1秒时,角色应该是这个站立的姿态;在第3秒时,他要跳到这个空中姿态。” 哪怕动画师只提供了这两张草图,AI也能在它们之间生成平滑、合理的过渡动作。这个机制赋予了艺术家前所未有的控制力,让他们可以用最少的工作量,精确地主导动画的走向。

(2)空间低秩适配器 (SLRA):教会AI画“卡通”而不是“视频”
当前主流的视频生成AI,大多是在海量的真实世界视频数据上训练的。这导致了一个问题:它们天生就倾向于生成写实的、带有复杂光影和纹理的画面。如果你直接让它们去生成卡通,结果往往不伦不类,既没有卡通的简洁美感,动作也可能因为风格冲突而变得僵硬。
为了解决这个问题,研究团队设计了“空间低秩适配器(SLRA)”。这个名字听起来很复杂,但原理却很巧妙。它像一个安装在AI模型上的“风格滤镜”,专门用来调整模型对空间维度的理解,而不去干涉它对时间维度(即动作)的理解。
具体来说,SLRA会引导模型去学习卡通的特有视觉特征,比如简化的线条、平涂的色块、饱和的色彩以及夸张的造型。但它会有意地“绕过”模型中负责处理时间连续性的部分。这样做的结果是,模型成功地“学会”了如何绘制卡通画风,同时它原有的、强大的时序建模能力被完整地保留了下来。最终生成的动画,既有统一的卡通美学,又有流畅自然的动作。
(3)区域控制机制 (Region-wise Control):把“留白”的权力交给AI
在动画创作中,并非画面的每一个角落都需要艺术家亲力亲为。很多时候,我们可能只想画一个正在奔跑的角色,而把背景交给AI去处理。
“区域控制”功能就为此而生。在训练阶段,模型会学习“看图填空”:研究人员会随机地遮挡草图的某些区域,然后让模型根据剩余的可见部分和文本提示,去“脑补”并重建被遮挡的内容。
经过这样的训练,模型就获得了智能填充的能力。在实际创作时,动画师可以只画出前景的角色,然后用工具标记出背景区域,告诉AI:“这块地方你来画。”AI便会根据上下文(比如角色的动作、光照方向等)以及可能的文本提示(比如“在森林里奔跑”),智能地生成动态的、与前景相协调的背景。这进一步解放了艺术家的双手,让他们可以更专注于核心内容的创作。

三、实际效果如何?数据说了算
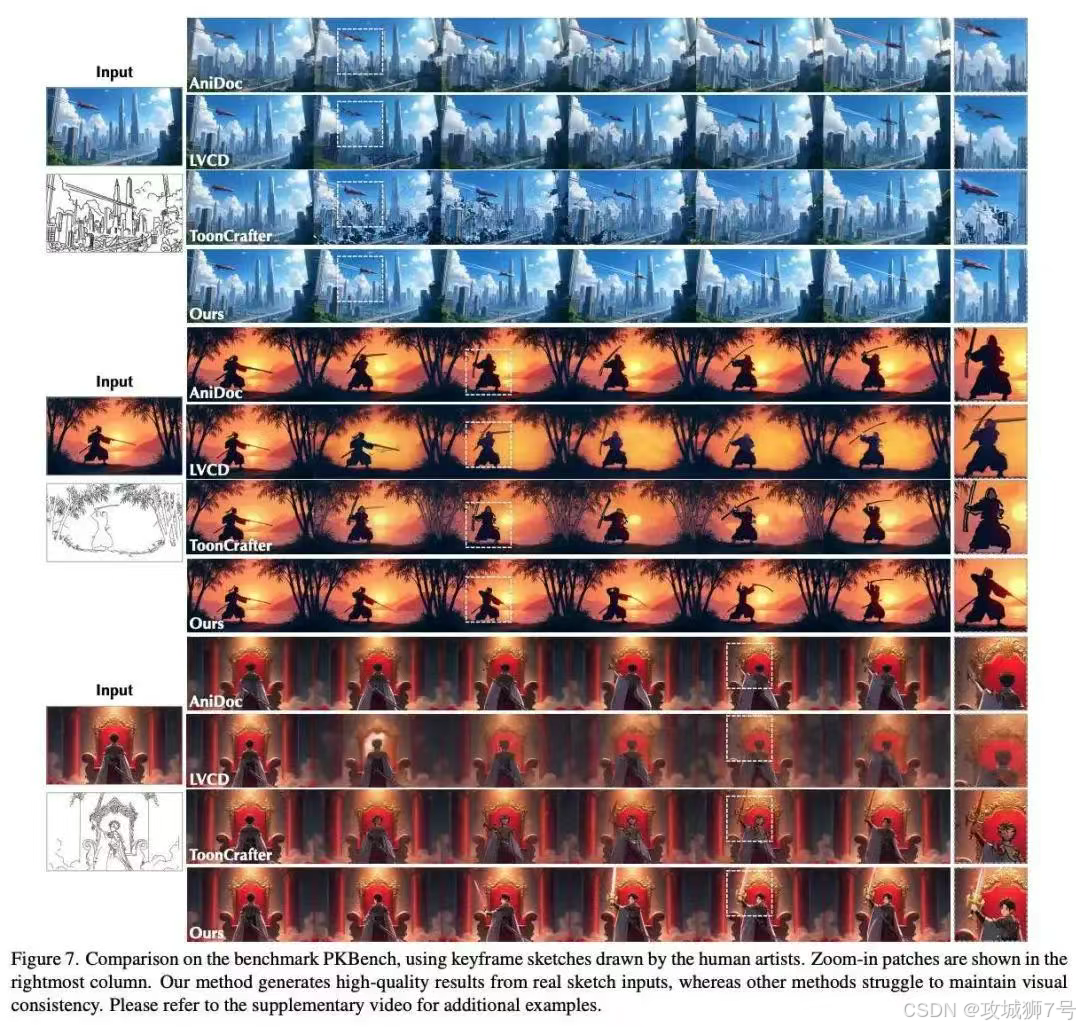
一个新工具是骡子是马,终究要拉出来遛遛。为了客观地评估ToonComposer的性能,研究团队专门构建了一个名为PKBench的评测基准,其中包含了由专业动画师手绘的、更贴近真实应用场景的草图。
在与现有的其他AI辅助动画生成方法的对比中,ToonComposer在多项关键指标上都取得了压倒性优势。无论是视觉质量(画面清晰度、细节保留)、动作连贯性还是风格一致性,都显著优于对手。
更有说服力的是人类的直接评价。在一项盲测中,47名参与者(包括专业人士)被要求从“美学质量”和“动作质量”两个维度对不同工具生成的动画进行评价。结果显示,To-onComposer获得了超过70%的压倒性支持率。这意味着,它生成的动画不仅在技术指标上领先,也更符合人类的审美偏好。
四、ToonComposer的意义:解放创造力,而非取代创造者
ToonComposer的出现,标志着AI在动画领域的应用进入了一个全新的阶段。它并非要取代动画师,恰恰相反,它旨在成为他们最强大的创作伙伴。通过将创作者从繁重、重复的“画大饼”式劳动中解放出来,它让艺术家能够将宝贵的精力更专注于故事叙述、角色设计、镜头语言和创意表达等这些真正需要人类智慧和情感的核心环节。
这项技术极大地降低了动画制作的门槛。对于独立创作者、小型工作室,甚至是普通爱好者来说,制作一段高质量的动画短片不再是遥不可及的梦想。一个有创意的学生,或许仅凭一人之力,就能完成过去需要一个团队数周才能完成的工作。
当然,ToonComposer目前仍处于早期阶段,较高的计算成本是其走向大规模应用前需要解决的问题。但它所倡导的“后关键帧”理念,无疑为整个行业指明了一个更高效、更智能、更富创造力的方向。我们有理由相信,在不久的将来,当这类工具变得更加成熟和易用时,一个属于全民的“动画时代”或许真的会到来,无数富有想象力的作品将因此诞生,为世界带来更多精彩。
项目官网:https://lg-li.github.io/project/tooncomposer
GitHub仓库:https://github.com/TencentARC/ToonComposer
HuggingFace模型库:https://huggingface.co/TencentARC/ToonComposer
arXiv技术论文:https://arxiv.org/pdf/2508.10881
在线体验Demo:https://huggingface.co/spaces/TencentARC/ToonComposer
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!























 到【灌水乐园】发言
到【灌水乐园】发言









