





SeedVR2 :基于对抗训练的单步扩散视频复原(SeedVR加速版)(2025)
本文将对《SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training》这篇文章进行解读,该文提出了SeedVR2,在SeedVR的基础上实现了加速,将多步扩散变成了单步扩散。SeedVR2的核心设计在于采用了自适应窗口注意力机制和零依赖教师模型的对抗后训练(APT)。参考资料如下:
参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
现在是数字化时代,图像与视频早已成为信息传递的关键载体。超分辨率(super resolution,SR)技术能够突破数据源的信息瓶颈,挖掘并增强低分辨率图像与视频的潜能,重塑更高品质的视觉内容,是底层视觉的核心研究方向之一。并且SR技术已有几十年的发展历程,方案也从最早的邻域插值迭代至现今的深度学习SR,但无论是经典算法还是AI算法,都在视觉应用领域内发挥着重要作用。
本专题旨在跟进和解读超分辨率技术的发展趋势,为读者分享有价值的超分辨率方法,欢迎一起探讨交流。
系列文章如下:
【1】SR+Codec Benchmark
【2】OSEDiff
【3】PiSA
【4】DLoRAL
【5】DOVE
【6】HYPIR
【7】SeedVR
【8】FlashVSR
一、研究背景
Diffusion-based的视频恢复(VR)虽然能生成高质量、细节丰富的视频,但通常需要数十步采样,导致计算成本和延迟极高,无法满足现实世界应用(如流媒体、实时编辑)的需求。
而单步Diff的图像复原\超分方法逐步取得了效果突破,成为了一种高效化的技术趋势,但当前多数方法有两个问题:
- 依赖于教师模型,性能受教师模型上限约束;
- 直接应用于视频时,因缺乏时空设计,效果不佳。
针对上述几个问题,该方案推出了一种高效的基于单步扩散的视频复原方法,其核心亮点如下:
-
首次实现“单步”扩散视频恢复: SeedVR2是首个在单步采样内实现高质量视频恢复的扩散模型。
-
自适应窗口注意力机制: 针对高分辨率视频恢复中预定义窗口大小导致的边界伪影问题,提出了一种动态调整窗口大小的机制。该机制在训练和推理时根据输入分辨率计算窗口尺寸,显著提升了模型在任意分辨率输入下的鲁棒性,是处理高分辨率视频的关键技术。
-
零依赖教师模型的对抗后训练(APT): 与依赖预训练教师模型进行蒸馏的方法不同,SeedVR2直接以一个预训练的扩散模型(SeedVR)为起点,通过对抗性后训练(Adversarial Post-Training, APT)进行端到端微调。这避免了教师模型性能上限的限制,并允许模型在单步内超越初始模型的性能。
-
专为视频恢复设计的训练改进:
-
渐进式蒸馏(Progressive Distillation): 在对抗训练前,先通过渐进式蒸馏(从64步逐步蒸馏到1步)来弥合初始多步模型与目标单步模型之间的巨大鸿沟,稳定训练过程并保持恢复能力。
-
特征匹配损失(Feature Matching Loss): 为解决高分辨率视频训练中计算LPIPS损失成本过高的问题,提出直接从判别器中提取多层特征进行匹配的损失函数。该损失在效率和效果上取得了良好平衡,是稳定大规模对抗训练的关键。
-
改进的损失函数组合: 采用RpGAN损失替代传统的非饱和GAN损失,并结合R1和R2正则化项,有效防止了训练过程中的模式崩溃,提升了训练稳定性。
-
二、方法细节
2.1 预备知识
扩散APT是一种将多步扩散模型转换为一步生成器的扩散加速方法。APT主要有两个训练阶段,即确定性蒸馏和对抗后训练。
-
确定性蒸馏:按照带有MSE损失的离散时间一致性蒸馏对蒸馏模型进行训练。教师模型采用了固定的classifier-free guidance(CFG)系数和一个预定义的负提示。
-
对抗训练:先通过预训练的扩散网络初始化判别器,然后引入额外的“cross-attention-only transformer blocks” 来生成logits用于损失计算。为了稳定训练和避免高阶梯度计算,APT提出了一个近似的R1损失来正则化判别器,判别器最终损失为非饱和GAN损失和近似化R1损失。
架构示意图如下

2.2 自适应窗口注意力
文中所提到像SeedVR这样的模型,使用的是预设大小的窗口注意力(例如 64x64)。
在处理高分辨率视频(如 1080p)时,这种固定大小的窗口在图像块(patch)的边界处会产生可见的不连续性(即边界伪影)。这种缺陷源于训练时的分辨率与测试时的分辨率不匹配。
这里提出了一种全新的注意力机制,其核心思想是让窗口大小在一定范围内根据输入的分辨率动态计算。从训练和测试两个阶段来看。
-
训练阶段的窗口计算:
-
给定一个编码后的输入视频特征图 X ∈ R d t × d h × d w × d c X \in \mathbb{R}^{d_t \times d_h \times d_w \times d_c} X∈Rdt×dh×dw×dc,其分辨率为 d h × d w {d_h \times d_w} dh×dw= 45 × 80。
-
在做Swin-MMDIT时,其窗口大小(window size)不是固定的,而是根据输入特征图的尺寸动态计算的。
p t = ⌈ min ( d t , 30 ) n t ⌉ , p h = ⌈ d h n h ⌉ , p w = ⌈ d w n w ⌉ p_t = \left\lceil \frac{\min(d_t, 30)}{n_t} \right\rceil, \quad p_h = \left\lceil \frac{d_h}{n_h} \right\rceil, \quad p_w = \left\lceil \frac{d_w}{n_w} \right\rceil pt=⌈ntmin(dt,30)⌉,ph=⌈nhdh⌉,pw=⌈nwdw⌉
其中, n t n_t nt, n h n_h nh, n w n_w nw分别是沿时间维度 d t d_t dt、高度维度 d h d_h dh、宽度维度 d w d_w dw划分的窗口数量。 [ ⋅ ] [ · ] [⋅]是向上取整函数。为了防止训练和推理时序列长度差距过大,对 d t d_t dt设置了一个上限 m i n ( d t , 30 ) min(d_t, 30) min(dt,30)。
-
由于训练数据的宽高比变化很大,即使训练分辨率固定,每次训练时计算出的窗口大小也会随之变化。这种设计迫使模型在训练阶段就学习处理各种不同大小的窗口,从而显著提升了模型在测试时对不同分辨率输入的泛化能力。
-
测试阶段的窗口计算:
为了进一步提高模型在高分辨率输入下的鲁棒性,测试时引入了一个“分辨率一致性窗口划分策略”。

-
给定一个测试时的视频特征图 X ^ ∈ R d ^ t × d ^ h × d ^ w × d ^ c \hat{X} \in \mathbb{R}^{\hat{d}_t \times \hat{d}_h \times \hat{d}_w \times \hat{d}_c} X^∈Rd^t×d^h×d^w×d^c 。
-
首先,计算一个“空间代理分辨率”(spatial proxy resolution) d ~ h × d ~ w {\tilde{d}_h \times \tilde{d}_w} d~h×d~w。
d ~ h = d h × d w × d ^ h d ^ w , d ~ w = d h × d w × d ^ w d ^ h \tilde{d}_h = \sqrt{d_h \times d_w \times \frac{\hat{d}_h}{\hat{d}_w}}, \quad \tilde{d}_w = \sqrt{d_h \times d_w \times \frac{\hat{d}_w}{\hat{d}_h}} d~h=dh×dw×d^wd^h,d~w=dh×dw×d^hd^w-
这个代理分辨率的宽高比必须与测试输入的宽高比完全一致, d ~ h × d ~ w = d ^ h × d ^ w {\tilde{d}_h \times \tilde{d}_w = \hat{d}_h \times \hat{d}_w} d~h×d~w=d^h×d^w。
-
同时,这个代理分辨率的面积必须与训练时的分辨率面积相同, d ~ h × d ~ w {\tilde{d}_h \times \tilde{d}_w} d~h×d~w = d h × d w {d_h \times d_w} dh×dw = 45 × 80。
-
然后,将这个代理分辨率 d ~ h × d ~ w = d ^ h × d ^ w {\tilde{d}_h \times \tilde{d}_w = \hat{d}_h \times \hat{d}_w} d~h×d~w=d^h×d^w代入到计算窗口的公式(公式1),与测试时的时间维度 d ^ t \hat{d}_t d^t一起,计算出最终的测试时窗口大小。
-
这个策略确保了测试时的窗口划分方式,在“空间”维度上,与训练时的划分方式在“比例”和“密度”上保持一致,从而最大限度地减少了因分辨率变化带来的不一致性,巧妙地解决了固定窗口在高分辨率视频修复中导致的边界伪影问题。如下图所示。


2.3 训练相关
这部分主要是解决两个问题:1. 如何得到高质量的单步扩散模型?;2. 如何稳定地进行对抗训练?
为此,SeedVR2采用了两大策略:渐进式蒸馏和损失改进。
1️⃣ 渐进式蒸馏 progressive distillation
初始模型与目标模型之间的差距较大,直接训练可能会削弱单步模型的能力。为了缓解这以问题,借鉴了渐进式蒸馏的思想。
-
从64步,逐步降到32步、16步、8步、4步、2步,最后到1步。
-
每个蒸馏过程约10K次迭代。
-
采用最简单的MSE损失函数。
-
逐步增加训练数据的时间维度,从图像到不同帧数的视频。
最终,从一个7B参数的模型,蒸馏出一个3B参数的模型,性能几乎不降,实现了“小而强”的效果!
2️⃣ 损失函数改进 Loss Improvement
作者要训练的是“史上最大的视频修复GAN”(生成器+判别器总参数量约16B),对抗训练极其不稳定。
怎么办?策略如下:
-
受R3GAN启发,改用 RpGAN(Relativistic GAN)损失代替传统GAN损失。不是直接判断“真/假”,而是判断“比平均真实度高或低”。
-
引入R2正则化,惩罚判别器在“假数据”上的梯度范数,防止其对假数据过于敏感。公式如下:
L a R 2 = ∥ D ( x ^ , c ) − D ( N ( x ^ , σ I ) , c ) ∥ 2 \mathcal{L}_{aR2} = \|D(\hat{x}, c) - D(\mathcal{N}(\hat{x}, \sigma \mathbf{I}), c)\|_2 LaR2=∥D(x^,c)−D(N(x^,σI),c)∥2
其中 x x x (表示从模型输出的速度场转换而来的样本预测, c c c是文本条件, σ σ σ控制扰动高斯噪声的方差, I I I表示单位矩阵。作者表示,上述损失改进保证了在训练数千次迭代也没有出现模式崩溃,训练将会更加稳定。 -
引入特征匹配损失。除了GAN Loss,还有L1和LPIPS Loss,这在像素空间计算会很费算力。于是,这里采用特征匹配损失,直接从判别器的第16、26、36层(即“仅交叉注意力的Transformer块”之前),提取特征。并且计算生成视频和真实视频在这些特征层上的L2距离。
L F = 1 3 ∑ i = 16 , 26 , 36 ∥ D i F ( x ^ , c ) − D i F ( x , c ) ∥ 1 \mathcal{L}_F = \frac{1}{3} \sum_{i=16,26,36} \|D_i^F(\hat{x}, c) - D_i^F(x, c)\|_1 LF=31i=16,26,36∑∥DiF(x^,c)−DiF(x,c)∥1
除此之外,还对损失权重做了精细调整:
-
生成器训练时:L1损失、特征匹配损失、GAN损失的权重都设为 1.0。
-
判别器训练时:GAN损失权重 = 1.0;R1 和 R2 正则化权重 = 1000(大权重,强制稳定)
三、实验论证
训练: 在72块NVIDIA H100-80G GPU上训练,使用约100帧720p的视频作为每批次数据。首先从头训练一个7B的SeedVR模型,然后在此基础上进行SeedVR2的对抗后训练。
数据集: 合成数据集(SPMCS, UDM10, REDS30, YouHQ40)和真实世界数据集(VideoLQ, AIGC28)。
对比方法: 与当前最先进的视频恢复方法进行比较,包括基于GAN的方法(RealViformer)、基于扩散的多步方法(VEnhancer, UAV, MGLD-VSR, STAR, SeedVR)等。
3.1 定量结果
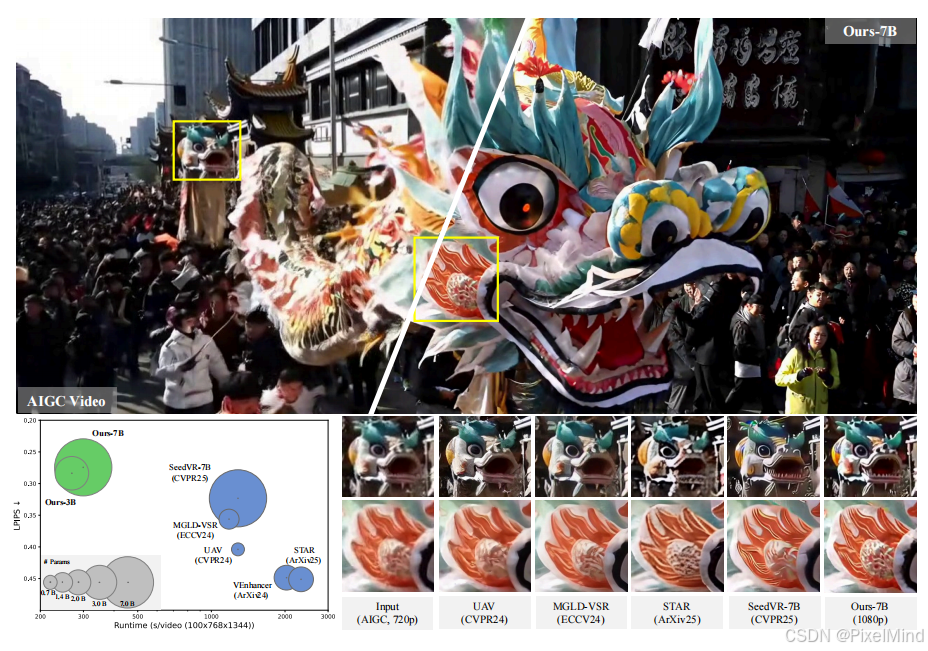
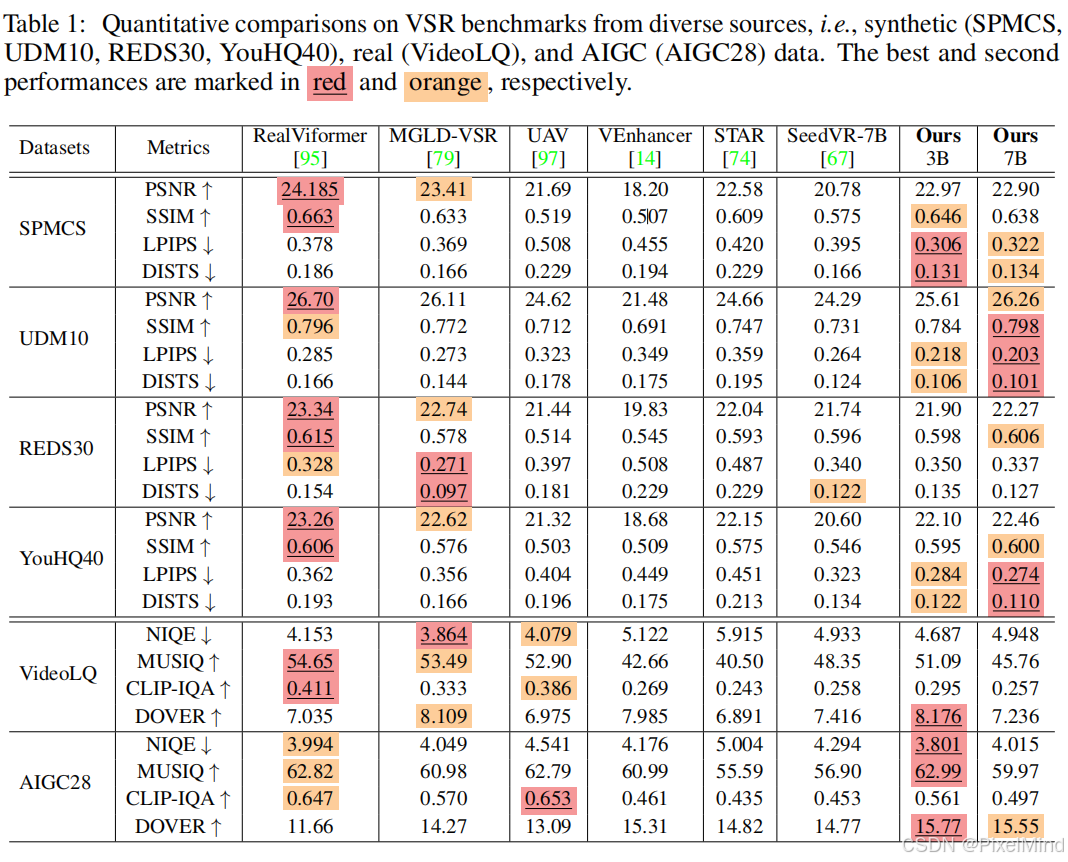
SeedVR2在多个合成数据集上,尤其是在感知指标LPIPS和DISTS上,表现优于或与SOTA方法相当。在真实世界数据集VideoLQ上,其NIQE、MUSIQ和DOVER得分与基线相当;在AIGC数据集上,其所有指标均取得了最高分。
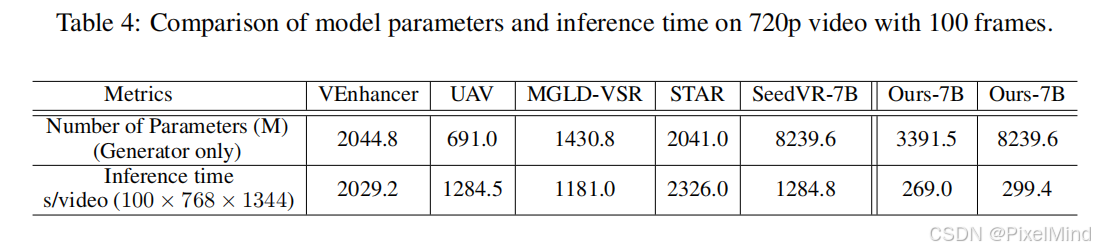
效率对比: SeedVR2(7B模型)的推理时间(约299.4秒/100帧720p视频)比其他需要50步的扩散模型(如VEnhancer的2029.2秒)快4倍以上,证明了其巨大的效率优势。
3.2 定性结果
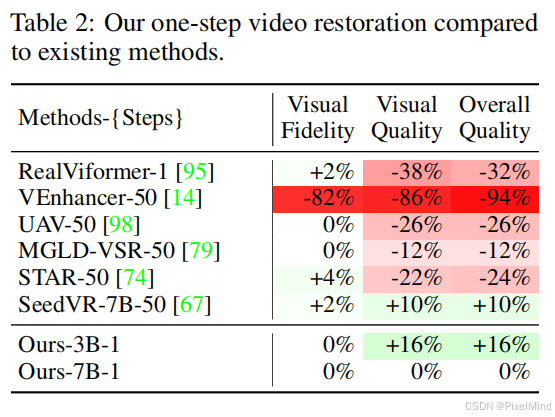
用户研究显示,SeedVR2(特别是3B模型)在视觉质量上明显优于其他所有方法,在视觉保真度上与多步的SeedVR相当。

3.3 消融实验
自适应窗口的作用已经在上面展示过了。其他方面的改进有效性如下表所示。例如,采用RpGAN+R1+R2损失比原始APT损失在感知指标上大幅提升;加入L1和特征匹配损失进一步优化了性能;渐进式蒸馏对最终性能至关重要。

四、总结和思考
SeedVR2是首个通过对抗后训练实现单步视频恢复的扩散模型。它通过引入自适应窗口注意力机制、渐进式蒸馏、特征匹配损失等一系列针对视频恢复的创新设计,成功地将一个需要多步采样的扩散模型转化为一个高效、高质量的单步生成器。
实验表明,SeedVR2不仅在效率上比现有方法快4倍以上,而且在视觉质量和客观指标上也达到了相当甚至更优的水平。尽管目前仍存在对视频VAE效率的依赖以及在极端退化情况下的鲁棒性问题,但SeedVR2为未来的视频恢复研究提供了重要的思路和强大的基线模型。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。

















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









