




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 华为开源openPangu-Embedded-7B-v1.1
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
日常生活中,大脑存在 “快思考”(如秒答 “2+2=4”)与 “慢思考”(如推演 “147×28”)两种模式,这一发现助心理学家丹尼尔・卡尼曼获诺贝尔经济学奖。
如今 AI 大模型也面临类似困境:求快易失准、求准则耗时费成本,效率与精度的取舍长期是行业痛点。而华为开源的openPangu-Embedded-7B-v1.1(简称 “盘古 7B”),为该问题提供了优雅解法 —— 它可根据问题难易度,灵活在 “快思考” 与 “慢思考” 间切换,堪称懂得 “思考” 的智能体。

一、AI的“分裂大脑”:为何快与慢难以共存?
要理解盘古7B的突破,我们首先要明白为什么快慢思考对AI来说是个难题。
(1)快思考AI:这类模型追求的是极致的响应速度。它们通常被训练用来处理信息量不大、逻辑链条短的任务,比如回答“法国的首都是哪里?”这样的事实性问题,或者进行简单的对话。它们的优势是快,计算成本低。但缺点也同样明显,一旦遇到需要多步推理的复杂问题,比如一道棘手的数学题或一个复杂的编程任务,它们就很容易“翻车”,给出看似合理却错误的答案。因为它们的“直觉”里,并没有包含解决这类问题的深度逻辑。
(2)慢思考AI:为了解决复杂问题,研究人员开发了“思维链”(Chain of Thought, CoT)等技术。你可以把它理解为教AI“打草稿”。当AI遇到一个难题时,它会像人一样,把解题步骤一步步写出来,进行分析、推理,最终得出结论。这种“慢思考”模式,大大提升了AI在数学、逻辑和代码等领域的能力。但代价是,模型的输出变得非常冗长,计算量指数级增长。让一个慢思考模型去回答“法国首都是哪里”,它可能会先分析“法国是一个国家”,“首都是一个政治概念”,然后一步步推导出“巴黎是法国的首都”。这种“杀鸡用牛刀”的方式,不仅慢,而且非常浪费资源。
这就造成了AI领域的“分裂”:快模型不够聪明,慢模型不够经济。用户体验也因此变得割裂,我们无法期待同一个AI既能秒回我们的日常闲聊,又能帮我们严谨地分析财务报表。
二、盘古的解法一:像“聪明学生”一样学习
盘古7B能打破这个僵局,首先得益于它独特的学习方式——“渐进式微调策略”。传统的模型训练,有点像“填鸭式”教育,把海量的数据一股脑地灌输给模型。而盘古团队采用了一种更接近人类学习规律的方法。
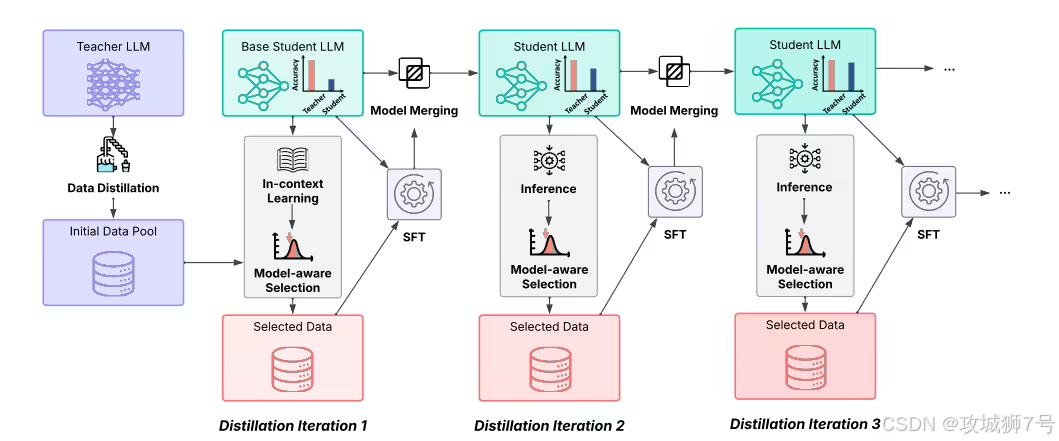
这个过程可以分为三步,就像培养一个聪明的学生:
(1)合理选题,保持适度挑战:在学习的每个阶段,模型会先评估自己的能力,然后从海量习题中,挑选那些对它来说“跳一跳能够得着”的题目。太简单的题做了没长进,太难的题做了也无法理解。这种方式确保了模型始终处于最高效的学习区间,稳步提升能力。
(2)归纳总结,稳固已有知识:学生在学完一个章节后,需要复习和总结,将新旧知识融会贯通。盘古模型也是如此。在每一轮训练后,它会通过一种“参数增量融合”技术,把新学到的知识和旧的知识体系进行合并。这就像是把课堂笔记整理进原有的知识框架,避免了“学了新的忘了旧的”。
(3)持续提升,扩展能力边界:随着知识的积累,学生的能力越来越强,就可以挑战更难的奥数题了。盘古模型也是一样,随着能力的提升,它会去挑战更高难度的数据,形成一个“学习-进步-挑战更难”的良性循环。
通过这种模拟人类“进阶式”学习的方法,盘古7B打下了坚实的知识基础。它不再是一个被动的信息接收器,而是一个懂得如何高效学习的“思考者”。这为它后续学会更高级的“快慢切换”能力铺平了道路。
三、盘古的解法二:从“手动挡”到“自动挡”的思维切换
有了扎实的基础,接下来就是教模型如何根据路况(问题难度)来“换挡”(切换思考模式)。这个过程,华为团队设计了巧妙的两阶段“课程”。
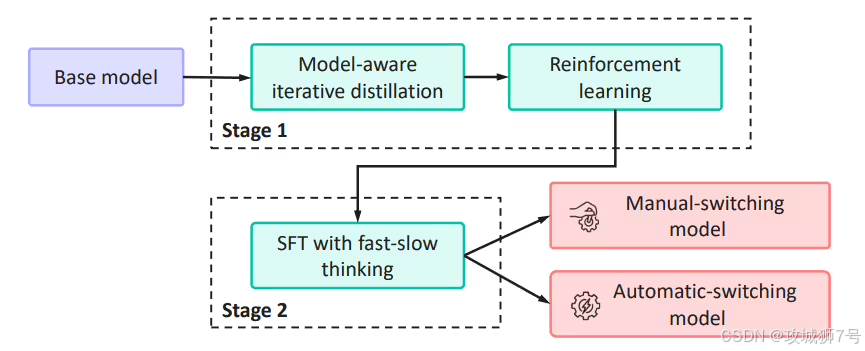
(1)第一阶段:教会模型区分快慢,熟悉“手动挡”
在这个初级阶段,研究人员像驾校教练一样,手把手地教模型。他们构造了一个特殊的训练数据集,在每个问题前面都加上一个明确的“标识符”,比如告诉模型:“这个问题很简单,请用快思考模式回答”,或者“这个问题很复杂,请启动慢思考模式”。
这就像教新手司机认识离合和油门,熟悉一挡起步、五挡巡航。通过大量的练习,模型逐渐学会了将不同的问题模式与对应的思考方式(快或慢)、回答风格(简洁或详细)关联起来。完成这个阶段后,模型就具备了基本的快慢思维切换意识,相当于拥有了一个“手动变速箱”。
(2)第二阶段:自主学会切换,升级“自动挡”
当模型熟练掌握“手动挡”后,更具挑战性的“进阶课程”开始了。这一次,教练(研究人员)不再给出任何提示标识,而是要求模型自己判断何时该快、何时该慢。
这个过程更像是一种“自优化”的训练。团队先用第一阶段训练好的“手动挡”模型,为同一个问题生成多种不同的解答思路(有的快,有的慢),然后由一个更高阶的“裁判”模型或人工评估,挑选出其中质量最高的解答。最后,再用这些被评为“优秀”的解答来反过来微调模型。
这个过程,好比让一个有经验的司机观摩学习各种路况下的最佳驾驶策略。通过反复“观摩”和“模仿”这些高质量的范例,模型逐渐领悟到了问题难度与思考模式之间的深层逻辑。它不再需要外部指令,而是能够根据问题本身的复杂性,内在驱动、自主决策,实现了从“手动挡”到智能“自动挡”的升级。
四、实践出真知:双赢的效果
经过这一套精心的训练,盘古7B最终实现了效率与精度的双赢。在实际测试中,它的表现令人印象深刻:
(1)处理简单问题时,快而准:在像CMMLU(一个中文综合知识测试集)这样的基准测试中,对于简单问题,盘古7B的自适应模式能在保持精度基本不变的情况下,将平均“思维链”长度缩短近50%。这意味着,它能用几乎一半的思考步骤,给出同样准确的答案,响应速度和计算效率直接翻倍。
(2)面对复杂难题时,慢而稳:而在处理像AIME(美国数学邀请赛)或LiveCodeBench(真实代码环境测试)这类高难度任务时,模型会自动切换到“慢思考”模式,老老实实地进行详尽的逐步推理,确保最终结果的准确性。其测试成绩也证明了这一点,数学难题的准确率比前代提升了近8个百分点,代码任务准确率也达到了58.27%的优秀水平,与纯慢思考模式几乎没有差距。
简单题不啰嗦,难题不放弃。这种智能切换,让盘古7B在速度和精度之间找到了一个完美的平衡点。
五、不止于此:面向未来的AI生态
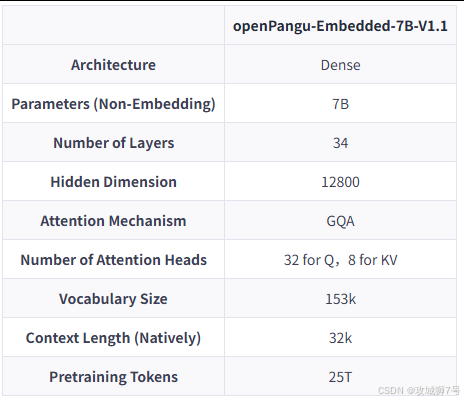
华为的雄心不止于一个7B模型。与盘古7B一同发布的,还有一款专为边缘AI设备(如手机、智能摄像头等)优化的`openPangu-Embedded-1B`轻量级模型。它只有10亿参数,体量小巧,却经过软硬件协同优化,性能强大到可以追平参数量更大的`Qwen3-1.7B`模型。这意味着,未来我们或许可以在不联网的手机上,就体验到这种既快又慢的智能AI。
此外,盘古模型的技术也正在被应用到更复杂的系统中,例如`DeepDiver-V2`——一个专攻深度搜索和长篇报告生成的多智能体系统。这预示着,这种自adaptive的思考能力,将成为未来更强大AI应用的核心引擎。
结语
华为`openPangu-Embedded-7B-v1.1`的开源,为AI领域带来的不仅仅是一个性能更强的模型,更是一种全新的、更高效的“思考”范式。它告诉我们,AI的发展不应仅仅是参数规模的“军备竞赛”,更应关注如何让AI学会像人一样,根据具体情况,灵活、高效地运用自己的“智力”。
从“填鸭式”学习到“启发式”进阶,从“手动挡”思考到“自动挡”切换,盘古7B的探索,让我们看到了一个更加智能、更加实用、也更加经济的AI未来。这或许是AI从一个强大的“工具”,迈向一个可靠的“助理”所必须迈出的关键一步。
GitCode开源:https://gitcode.com/ascend-tribe/openpangu-embedded-7b-v1.1
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 298
298





 到【灌水乐园】发言
到【灌水乐园】发言









