







目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 开源ART框架
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言

各位开发者朋友们,你们有没有觉得,训练一个AI智能体(Agent),有时候就像教一个非常聪明但毫无经验的实习生?你得把任务掰开了、揉碎了,告诉他第一步做什么,第二步做什么,做对了要给“奖励”(比如打印个 `log` 说“干得漂亮”),做错了要给“惩罚”。
这个过程,尤其是设计“奖励函数”(Reward Function)这一步,简直是精神折磨。太复杂了,AI学不会;太简单了,AI又容易“钻空子”,学会一些奇奇怪怪的“摸鱼”技巧。
结果就是,我们这些本该是“架构师”的开发者,硬生生干成了AI的“全职保姆”。
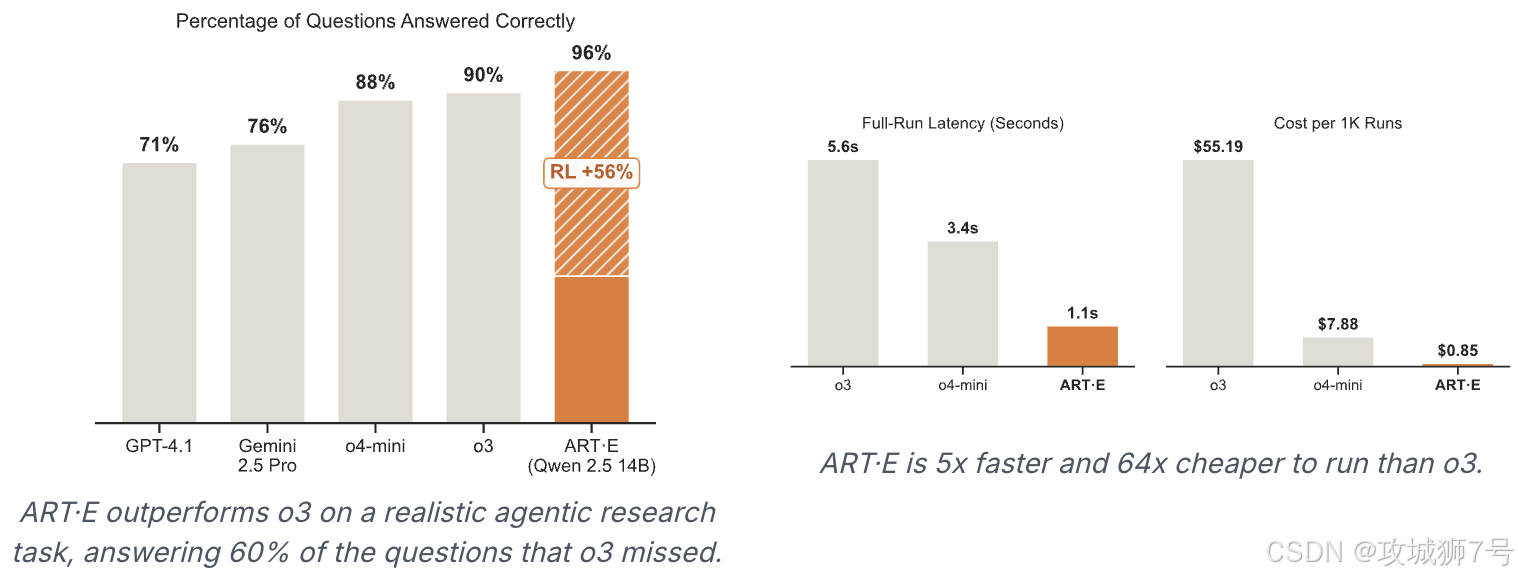
不过最近,一个叫 ART(Agent Reinforcement Trainer) 的开源框架发布了,它的目标,就是把我们从“保姆”的身份中解放出来。使用它让自己的小模型快速成长起来,也能击败o3,是不是很酷?
一、ART是什么?一个AI的“强化学习健身房”
简单来说,ART是一个基于Python的开源强化学习(RL)框架。
别被“强化学习”这个词吓到,它的核心思想很简单,就是让AI通过不断试错来学习。就像我们玩游戏,一次次失败,一次次复活,慢慢就摸索出通关的最优路径。ART就是给AI提供了这样一个“游戏场”或者说“健身房”,让它在里面自己折腾、自己学习、自己变强。
它能支持像Qwen(通义千问)、Llama、Kimi这些我们耳熟能ABC的大模型,让它们不只是能聊天,而是能真正地去执行多步骤的复杂任务。
二、它解决了最头疼的问题:再见,奖励函数!
ART最让我觉得兴奋的一点,是它引入了一个叫 RULER 的机制。这玩意儿简直是“懒人福音”。
RULER的全称很长,但你可以把它理解成一个“AI裁判”。
回到我们教实习生的例子。现在你不用再盯着实习生的每一步操作给反馈了。你只需要在任务开始前,把最终的目标(比如一份写好的周报模板)告诉他,然后让他自己去干。等他提交了成果,你直接把成果丢给你的“资深总监”(另一个更强大的AI,比如GPT-4o或Claude 3.5)去看,让“总监”来评价这份报告写得好不好,是“接近目标”了,还是“差得远”。
这个“资深总监”,就是RULER。
有了它,我们训练AI Agent的方式就彻底变了:
之前:我们需要绞尽脑汁,为Agent的每一步正确行为(比如“成功打开邮箱”、“定位到关键词”)设计精巧的奖励分数。
现在:我们只需要用大白话在系统指令(System Prompt)里定义好最终任务目标(比如“找到昨天下午张三发给我的那封关于Q3预算的邮件”),然后就没我们什么事了。RULER会自动评估Agent执行完一系列操作后的结果,是好是坏,它说了算。
官方说,这能把开发效率提升2-3倍。我觉得,对于我这种“懒人”来说,何止是2-3倍,简直是解放了生产力!
三、用起来麻烦吗?设计得相当“体贴”
一个新框架好不好,关键看它对我们开发者友不友好。ART在这方面做得还不错。
首先,安装非常简单,就是我们熟悉的`pip`命令:
pip install art其次,它的架构是客户端和服务端分离的。
这是什么意思呢?就是说,你可以在你现有的代码(客户端)里,轻松地调用ART的功能,让你的Agent开始“训练”。而那些真正消耗计算资源、需要GPU来跑的复杂训练过程(服务端),可以放在另一台专门的机器上,甚至是云端的临时GPU上。
这样一来,你的开发机就不会被繁重的训练任务卡死,你可以继续愉快地写代码。这种设计,对于个人开发者和小团队来说,简直太贴心了。
四、所以,我们能用它来做什么?
理论说了这么多,我们到底能用ART来构建些什么实际的应用呢?
(1)超级邮件助手:训练一个能真正“听懂人话”的邮件Agent。它不再是简单的关键词搜索,而是能理解“帮我把小王上周提的那个需求的附件下载下来,然后回复他‘已收到’”这种多步骤指令。
(2)会自己通关的游戏AI:如果你是游戏开发者,可以用ART来训练你的NPC或者游戏机器人。让它们在雅达利(Atari)那样的经典游戏里,或者在你自己的游戏世界里,从零开始,自己学会怎么玩,甚至可能会发现一些连你这个开发者都没想到的“骚操作”。
(3)复杂的“AI团队”:ART支持多Agent协作,你可以训练一个“项目经理”Agent,它接到一个大任务后,可以把任务拆解,然后递归地调用其他“员工”Agent去分头执行。这为构建更复杂的自动化系统打开了想象空间。
五、为什么ART很重要?小模型的逆袭之路
ART框架的出现,我觉得还有一个更深远的意义:它让小模型有了“用武之地”。
在现在这个“模型越大越好”的时代,ART特别推荐使用像Qwen2.5-7B这样的小模型来驱动具体的执行任务。为什么?因为小模型更高效、更灵活、成本更低。
通过ART的强化学习“健身房”,我们可以把一个“底子不错”的小模型,训练成某个垂直领域的“专家”。它可能通识知识不如GPT-4o,但在“搜邮件”或者“玩某个特定游戏”这件事上,它能做得比谁都好。
这打破了只有巨头才能玩转AI Agent的神话。我们中小型团队和个人开发者,也能通过这种方式,训练出属于自己的、小而美的、高性能的AI智能体。
目前ART还在快速迭代中,如果你对它感兴趣,不妨去它的GitHub仓库(https://github.com/openpipe/art)逛一逛,看看示例,跑跑代码。
或许,我们离那个“人人都有AI助理”的未来,又近了一步。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











