




论文提出了一种可扩展的多数据集目标检测器(
ScaleDet),可通过增加训练数据集来扩大其跨数据集的泛化能力。与现有的主要依靠手动重新标记或复杂的优化来统一跨数据集标签的多数据集学习器不同,论文引入简单且可扩展的公式来为多数据集训练产生语义统一的标签空间,通过视觉文本对齐进行训练,能够学习跨数据集的标签语义相似性来进行标签分配。经过训练后,ScaleDet可以很好地泛化任意具有可见和不可见类的上游和下游数据集来源:晓飞的算法工程笔记 公众号
论文: Training data-efficient image transformers & distillation through attention

Introduction
计算机视觉的重大进步是由大规模数据集推动的,大规模数据集对于训练具有良好泛化能力的识别模型至关重要。但收集大量带标注的数据集既费钱又费时,为了在没有额外标注成本的情况下利用更多训练数据,最近的研究集中于统一多个数据集。从更多视觉类别和更多样化的视觉领域中学习,然后进行检测和分割。
要跨多个数据集训练目标检测器,需要应对几个挑战:
- 多数据集训练需要统一跨数据集的异构标签空间,来自两个数据集的标签可能指代相同或相似的对象。
- 数据集之间的训练设置可能不一致,不同大小的数据集通常需要不同的数据采样策略和学习计划。
- 多数据集模型应该比单数据集模型表现更好,但异构的标签空间、数据集之间的域差异以及对较大数据集的过拟合风险使得这一目标的实现更难。
为了解决上述挑战,现有研究大多手动重新标记类或训练多个特定于数据集的分类器。但这些方法缺乏可扩展性,随着数据集的增加,手动重新标记工作量和训练多个分类器的复杂性迅速增加。

与上述研究不同,ScaleDet是可扩展的多数据集目标检测器,主要有两个创新点:
- 可扩展的公式统一多个标签空间。
- 新颖的损失公式学习跨数据集的硬标签和软标签分配:硬标签用于消除类标签的歧义,而软标签作为正则化器关联相似类标签。
总体而言,论文的贡献如下:
- 论文提出了一种用于目标检测的新型可扩展多数据集训练方法,利用文本编码根据语义相似性来统一和关联跨数据集的标签,通过视觉文本对齐训练单个分类器来学习硬标签分配和软标签分配。
- 论文通过大量实验证明
ScaleDet在多数据集训练中具有令人信服的可扩展性、通用性以及性能。 - 论文评估了
ScaleDet在具有挑战性的Object Detection in the Wild基准上的可转移性,证明其在下游数据集上具有不错的泛化能力。
ScaleDet: A Scalable Multi-Dataset Detector
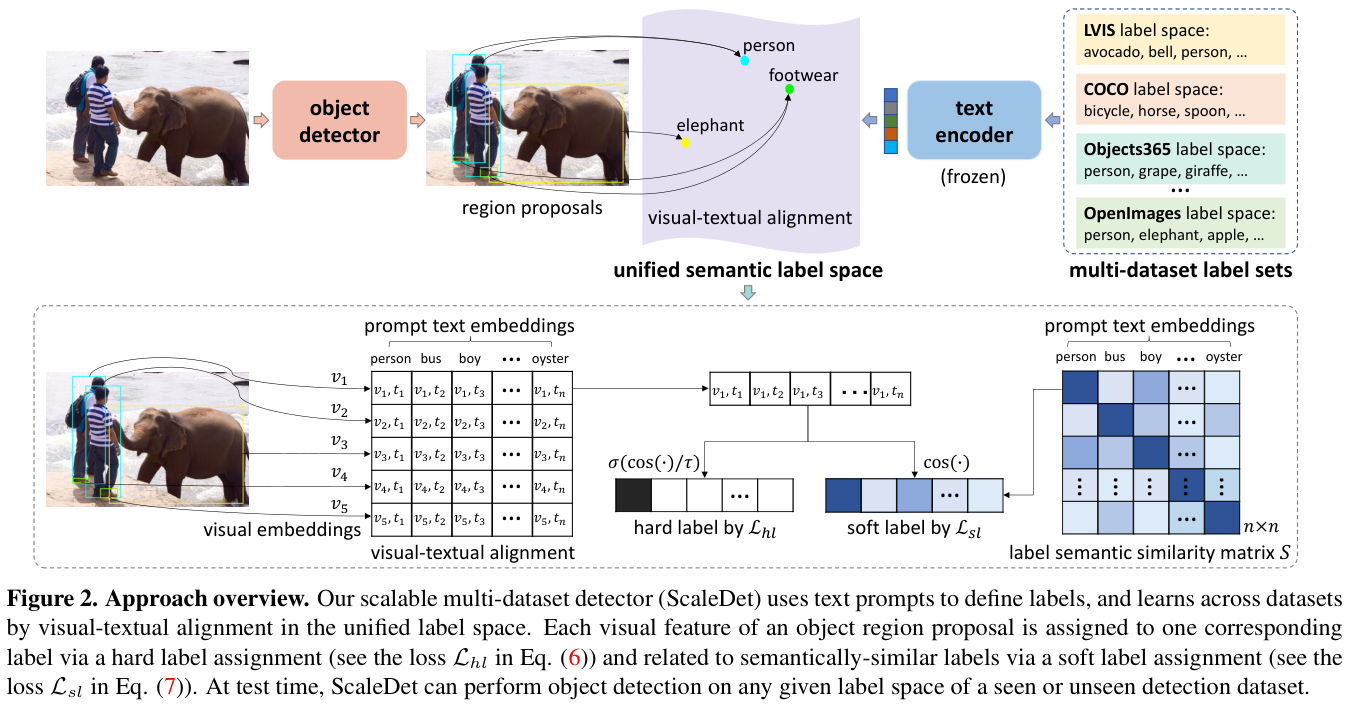
ScaleDet通过统一不同的标签集以形成统一的标签语义空间(图2顶部)进行跨数据集学习,并通过硬标签和软标签分配实现视觉文本对齐来进行训练(图2底部)。
Preliminaries and problem formulation
典型的对象检测器旨在预测对象的 b i ∈ R 4 b_{i}\in{\mathbf{R}}^{4} bi∈R4边界位置以及在给定 n n n个类中的类标签 c i ∈ R n c_i \in \mathbb{R}^n ci∈Rn。给定图像 I I I ,检测器的图像编码器(例如 CNN 或 Transformer)提取框特征和视觉特征,将其送到边界框回归器 B B B 和视觉分类器 C C C进行预测。检测器通过最小化边界框损失 L b b o x \mathcal{L}_{b b o x} Lbbox 和分类损失 L c l s \mathcal{L}_{cls} Lcls 来学习边界框的预测以及框特征和视觉特征对应的类标签,即,
L D e t = L b b o . + L c l s \mathcal{L}_{D e t}=\mathcal{L}_{b b o.}+\mathcal{L}_{c l s} LDet=Lbbo.+Lcls
现有的目标检测器通常采用一级或二级框架,其中可能包含额外损失项。单级检测器使用回归损失来回归对象位置的属性,如中心性,两阶段检测器则改为使用包含专用损失函数的RPN网络来预测每个框是目标的概率。
在这项工作中,论文专注于重新制定分类损失 L c l s \mathcal{L}_{cls} Lcls,在两级检测器之上解决多数据集训练问题。
给定一组 K K K 数据集 { D 1 , D 2 , … , D K } \{D_1, D_2, \dots, D_K\} { D1,D2,…,DK} 及标签空间 { L 1 , L 2 , … , L K } . \{L_{1},L_{2},\dots,L_{K}\}. { L1,L2,…,LK}. ,论文的目标是训练一个可扩展的多数据集检测器,该检测器可以很好地泛化上游和下游检测数据集。
之前的多数据集学习器手动将跨数据集的相似标签关联或合并到联合标签,而论文提出了一个简单但可扩展的公式来进行标签统一,无需手动合并任何标签。
Scalable unification of multi-dataset label space
如图2上部分所示,每次训练都从多个训练集中随机抽取一小批图像一起提取视觉特征 { v 1 , v 2 , … , v j } \{v_1, v_2, \ldots, v_j\} { v1,v2,…,vj},其中 v i ∈ R D v_{i}\in{\mathbf{R}}^{D} vi∈RD 是 D D D 维向量。每个视觉特征 $ v_{i}$ 通过标签分配与一组文本编码 { t 1 , t 2 , … , t n } \{t_{1},t_{2},\ldots,t_{n}\} { t1,t2,…,t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









