






最近,尝试在写故事,然后用sd配图。
其中,单人场景很容易生成。

但是多人场景的话,很难稳定生成满意的图像。
网上学了一招,用additional networks + controlnet openpose,可以稳定生成2-3人的场景,也分享给大家。
下面以一个双人场景为例
1.安装插件和模型
(1)下载安装好sd插件,additional network。地址https://github.com/kohya-ss/sd-webui-additional-networks。
(2)下载安装好sd插件,controlnet(https://github.com/Mikubill/sd-webui-controlnet)和oppenpose引导模型(https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main)。
2.找到你想生成的双人场景真人图,方便controlnet openpose识别人体姿态,比如下面这张图。

(图:小象馆)
3.设置openpose
点击enable启用,pixel pefect,allow preview;
预处理器选择openpose,模型选择openpose,(如果模型这里没有openpose,则记得下载openpose引导模型并放在SD的extensions\sd-webui-controlnet\models文件夹里面后,点击模型右侧的刷新按钮)
Control weight 权重这里设置0.8,让ai控制的姿势更自然一些。
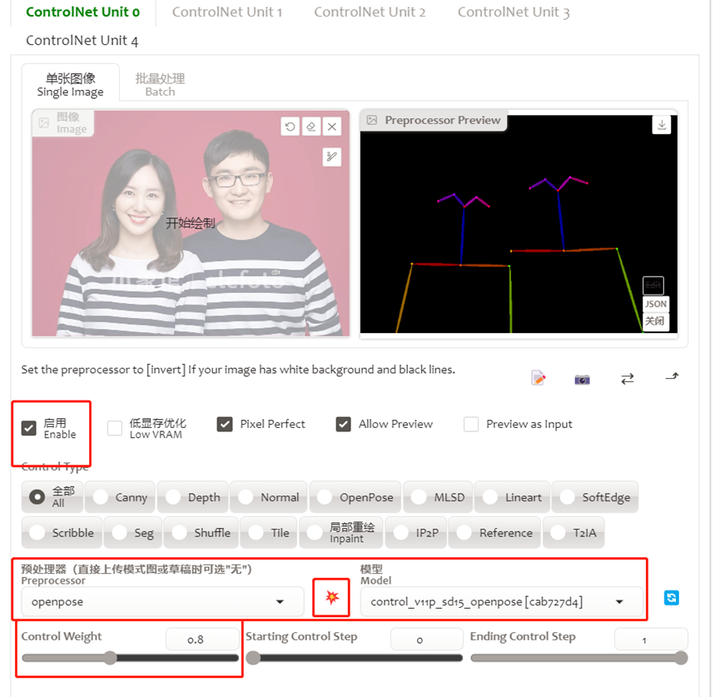
点击预处理器右侧的爆炸图标,就能看到骨架预览图,如果识别出来的骨架图觉得不太满意,需要微调也可以用openpose editor之类的工具对骨架识别并微调动作之后,再放进来controlnet使用。
4.设置additional networks
(1)把你想使用的lora模型,放入SD的extensions\ sd-webui-additional-networks\models\lora里面。
(2)启用附加网络,并在下方选择你想要用的lora模型,并分别设置权重为0.8.

(3)接下来就是重点了,展开额外参数extra args
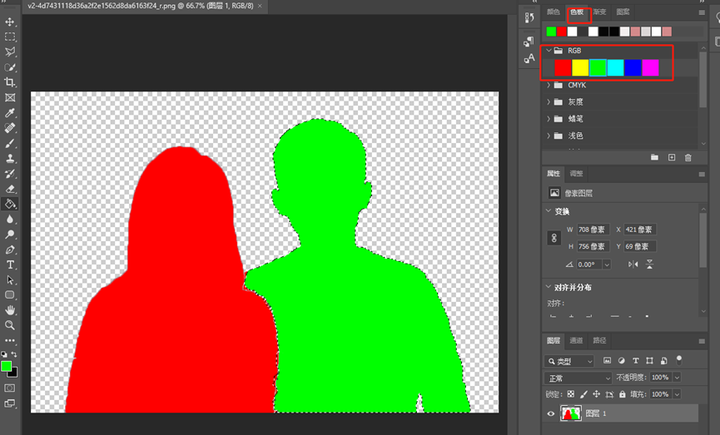
上传一张用ps或者之类的工具制作的人物色块png图片。(除了色块之外,全部背景需要是透明的。)
颜色需要是标准的rgb颜色的红绿黄。
抠图就直接用快速选择工具或者之类的抠图工具,把人物抠出来,再用油漆桶工具填充纯色,再把图片导出成png即可。
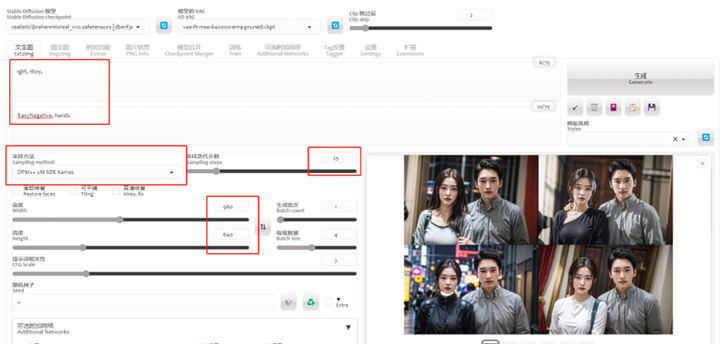
5.设置提示词等基本参数
提示词我是随便写的,因为就要一个男生一个女生出现在图像里,其他的就懒得写了,你如果对背景有要求可以加一些更丰富更细致的提示词。
采样器dpm+2m sde karras
步数step适度调高到25-30
图像尺寸比例参考你原来的底图,避免被压缩裁剪或拉伸变形。
然后开始生成。

提醒一下,
如果你的小黑窗出现了报错,那么大概率additional networks出现了问题,虽然画面会出现两个人一男一女没问题,位置姿势也没问题,但你的lora未生效,要指定人物就完全无法做到。
类似下面这种报错。
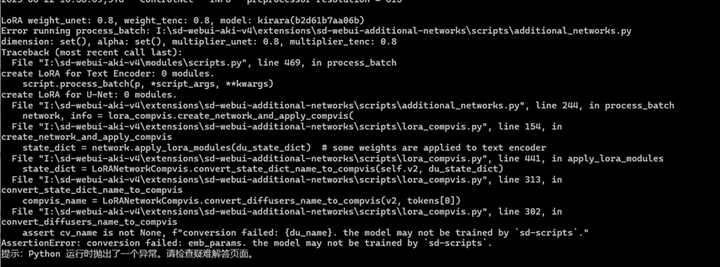
报错的话,需要重新安装最新的additional networks再试。
而如果类似下面这种,没有lora报错,并且显示了应用蒙版通道apply mask channel,那么代表你这种用不同的lora控制不同的人物是成功且生效的。
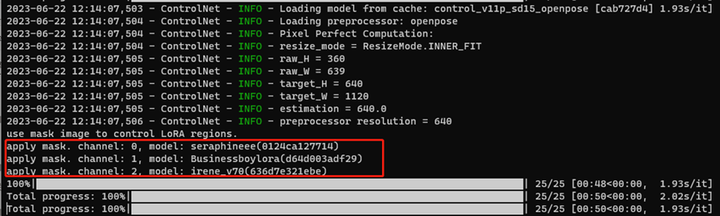
6.你会发现生成的男女主基本都是稳定的形象,可以用lora很好控制人物形象和特征,保持人物的统一性,同时生成多人图像也不容易崩。
比如随着剧情推进,女主找上了前男友。(女主不变换男主)

男主一怒之下,找了个小三。(男主不变换女主)

啊这,有点狗血。(没办法,狗血的剧情才有更多人喜欢看)
7.接着,我们再回来教程这里,如果说,两人场景控制人物形象和面容能比较容易实现,那么三人场景能否做到呢?答案是可以的。
比如我们祭出这张李寻欢同学的名场面图片。

同样用上面的处理方式一步一步来生成。
然后我们可以得到这样的图。

如果你喜欢大女主,不想让臭男人左拥右抱,那么可不可以呢?可以。

但是三个人的控制程度比两个人的控制更难一些,很难指定某个人物用特定某个lora,还需要多生成一些图像来抽卡,才能得到相对满意的图像。
但至少,比之前生成2-3人的图像,相对来说已经可控高了不少。
不管你用来做小说配图还是插画什么的,都方便很多。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[优快云大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









