






老梁专注于发现与分享实用的软件和经验,致力于解决您在系统软件方面所遭遇的难题。您的关注与支持,是我们前进的动力。
你们有没有遇到过这样的烦恼:在网上看到一张有趣的图片或者视频,结果上面打了一堆马赛克,让人看不清细节?别担心,我找到了一个神奇的工具,能帮你把这些碍眼的马赛克去掉,让图片和视频恢复清晰。
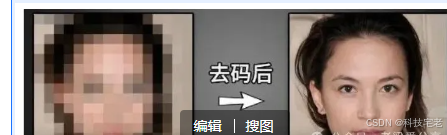
别急,我这就告诉你怎么用这个工具。首先,你得先下载这个工具,然后解压。解压后,你会看到一个叫做“启动程序.bat”的文件,双击它,工具就会启动。

启动后,你会看到两个选项:一个是处理图片,另一个是处理视频。你可以根据需要选择。选好后,你只需要找到你想要处理的文件,然后告诉工具你想让处理后的文件保存在哪里。接下来,就是点击开始处理,一切都交给工具吧。
如果你的电脑上装了360安全卫士之类的安全软件,可能会弹出警告。别担心,这个工具是安全的,你可以选择暂时关闭安全软件。而且,这个工具的源代码是公开的,你可以查看,确保没有确保没有安全隐患。
使用这个工具后,你会发现,原本模糊的图片变得清晰多了,甚至能看到很多之前看不到的细节。操作简单,效果惊人,这科技的力量真是让人大开眼界!
不过,我得提醒大家,不是所有的马赛克都能被完全去除。有些马赛克是直接嵌入到图片像素里的,那种就很难去掉。但CodeFormer能尽可能地修复视频或图片里的马赛克,虽然不能完全还原原图,但至少能让我们看得更清楚一些。
codeformer去马赛克的核心优势在于其卓越的去马赛克技术。通过先进的算法,可以精准地识别并去除图像中的马赛克区域,同时保持周围细节的完整性。无论是小范围的局部马赛克,还是大面积的模糊区域,都能够被有效处理,使原本模糊不清的部分变得清晰可见。
对于一些因各种原因导致损坏或者存在瑕疵的图片,这款应用同样有着出色的表现。它可以智能分析图像特征,自动填补缺失部分,调整色彩和亮度,使得修复后的图片看起来更加自然和谐,几乎看不出任何修补痕迹。
资源自取链接:夸克网盘分享


















 4582
4582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











