




 本文围绕MobileNet v2展开,它面向算力有限的移动模型。介绍了其新型模块中的关键结构inverted residual和linear bottleneck,阐述了linear bottleneck中以ReLU为例说明非线性映射问题及信息损失,还对比了MobileNet v2与ResNet的bottleneck结构,最后提及减少计算量方法和PyTorch实现接口。
本文围绕MobileNet v2展开,它面向算力有限的移动模型。介绍了其新型模块中的关键结构inverted residual和linear bottleneck,阐述了linear bottleneck中以ReLU为例说明非线性映射问题及信息损失,还对比了MobileNet v2与ResNet的bottleneck结构,最后提及减少计算量方法和PyTorch实现接口。
mobileNet v2和v1一样面向的是算力有限的mobile models.
主要贡献是一个新型module:

这里面提到了两个关键结构:inverted residual, linear bottleneck,
而linear bottleneck是用在inverted residule里面的。
关于linear bottleneck,有一个故事线,
故事讲了non-linear存在的问题,为什么要用linear,以ReLU为例。
下面就来讲讲这个故事:
首先给了一个前提假设,nerual network的兴趣区域特征应该能被嵌入一个低维的空间,
比如一个很深的卷积层,它里面的特征应该能被嵌入某个低维空间。

然而如果减少层数到低维,又会遇到non-linear映射的问题,比如ReLU,
回忆一下ReLU结构
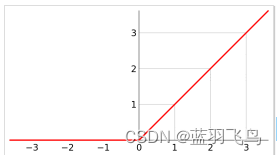
那ReLU有什么问题呢,你会发现它只能映射右半边,而损失掉左半边。
特征经过它的映射会变成分段的线。

为了证明这一点(ReLU确实有信息损失),作者用一个spiral做了实验,
先用随机的矩阵T把spiral映射到n维空间,经过ReLU后再用T-1映射回来,
当维度n比较小时(2,3), 确实会损失,而维度高时会好一些。

所以说如果input的有很多channels, 那么就有可能信息得到保留,

因此得到2个性质:

又是low-dimensional, 又是higher-dimensional,很绕口有木有,
其实是想说,兴趣区域的信息会嵌入到低维的空间中,但是在activation时需要一个高维的输入。
第1条说明了什么呢,
如果信息保留下来,那肯定是经过ReLU的右半边,右半边是线性的,所以为线性layer打下了基础。

ReLU能保留兴趣区域的信息,前提是信息在低维子空间。
所以这个故事得到了一个结论,
假设兴趣区域的信息就在低维子空间,
那么可以插入linear bottleneck来得到它。
因为linear layer不会造成信息的损失,然后non-linear再bottleneck结构中确实会影响performance.
你肯定想说为什么是linear bottleneck而不是linear 其他的,
mobileNet v2提出的就是改进版的bottleneck结构。
mobileNet v2中的bottleneck, 它的名字叫做

透露了几个点:
bottleneck里面沿用了mobileNet v1的深度可分离卷积,还有residuals
具体如下
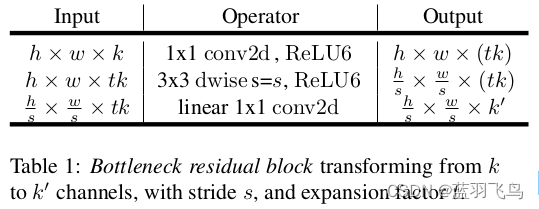
第一层是expansion,增加channel到t倍的,t 默认是6
然后是3x3深度卷积,再配上1x1卷积调整output channel。
对比一下resNet中的 bottleneck,
具体的参考链接
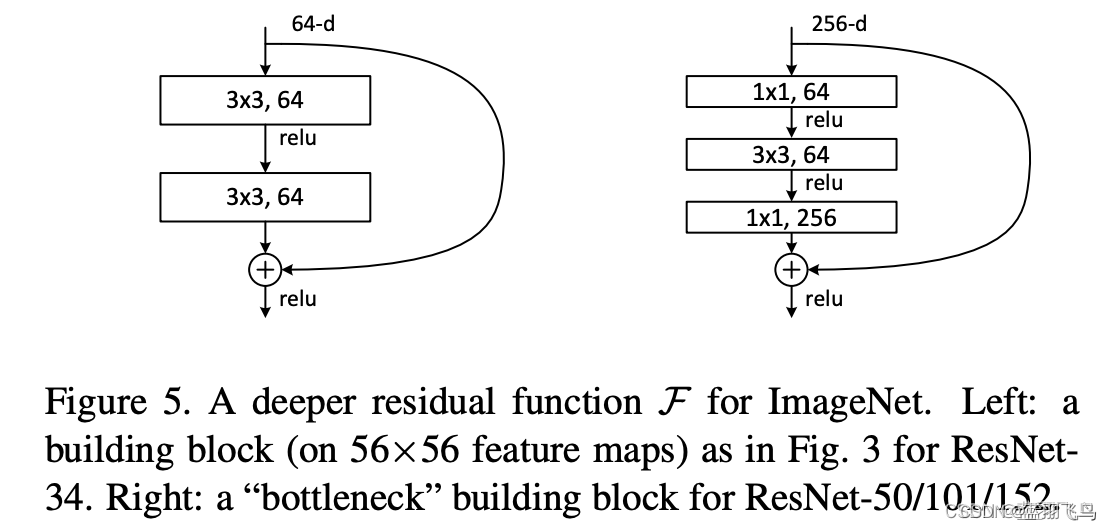
你会发现resNet的bottleneck,channel是在bottleneck结尾处扩张的,
而mobileNet v2中,channel是在bottleneck开头处扩张的,正好反过来,
所以叫做inverted residual.
因为inverted会更省内存


整体结构如下
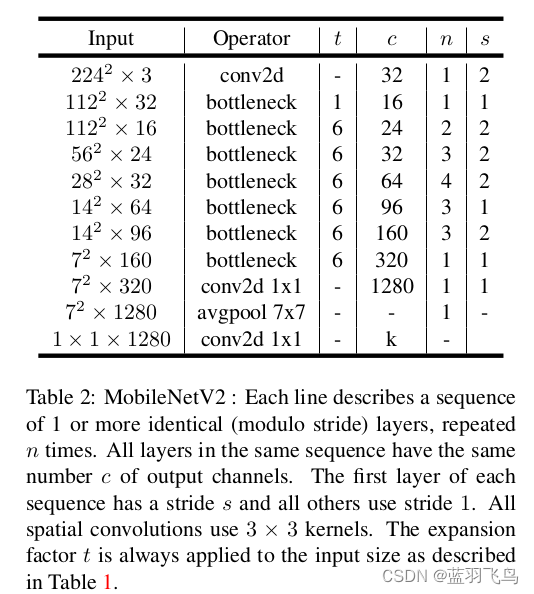
如果想进一步减少计算量,可以在除了最后一个layer的其他layer加上width multiplier(缩放channel)

关于shortcut连接到哪一层

pytorch已经有实现好的mobileNet v2接口,使用方法
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'mobilenet_v2', pretrained=True)
源码解析可以参考这篇文章



















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











