




在很多遥感应用中,我们并不总能获得足够的标注样本。比如:
-
新区域没有实地调查数据;
-
部分年份没有高质量的样本;
-
标注工作代价昂贵。
这时,无监督学习 尤其是 聚类(Clustering) 就派上用场了。它可以仅依靠光谱特征对像素进行分组,形成初步的“伪分类结果”,再结合少量人工标注进行后续分析。
往期内容和数据链接如下:
🧩 sklearn.cluster 常见方法
-
KMeans:最经典的聚类方法,基于欧式距离最小化。
-
MiniBatchKMeans:大数据优化版,更适合整幅影像。
-
AgglomerativeClustering:层次聚类,自底向上逐步合并。
-
DBSCAN:基于密度的聚类,可发现任意形状簇,能识别噪声。
-
SpectralClustering:基于图论的聚类,适合复杂结构。
在遥感实验中,最常用的是 KMeans,因为它简单高效,结果可解释性强。
💻 代码示例:KSC 数据无监督聚类
# -*- coding: utf-8 -*-
"""
Sklearn案例⑯:聚类与无监督分类(KSC 数据)
"""
import os, numpy as np, scipy.io as sio, matplotlib.pyplot as plt, matplotlib
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
# ===== 中文显示 =====
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['axes.unicode_minus'] = False
# ===== 参数 =====
DATA_DIR = r"your_path" # ← 修改为你的 KSC 数据路径
PCA_DIM = 20 # 聚类前先降维,加快计算
SEED = 42
# ===== 1. 读取数据 =====
X_cube = sio.loadmat(os.path.join(DATA_DIR,"KSC.mat"))["KSC"].astype(np.float32)
Y_map = sio.loadmat(os.path.join(DATA_DIR,"KSC_gt.mat"))["KSC_gt"].astype(int)
h, w, b = X_cube.shape
coords = np.argwhere(Y_map!=0)
X_all = X_cube[coords[:,0], coords[:,1]]
y_all = Y_map[coords[:,0], coords[:,1]] - 1
num_classes = y_all.max()+1
print(f"标签像素: {len(y_all)}, 类别数: {num_classes}")
# ===== 2. 标准化 + PCA =====
scaler = StandardScaler().fit(X_all)
X_std = scaler.transform(X_all)
X_pca = PCA(n_components=PCA_DIM, random_state=SEED).fit_transform(X_std)
# ===== 3. 聚类模型 =====
models = {
"KMeans": KMeans(n_clusters=num_classes, random_state=SEED, n_init=10),
"层次聚类": AgglomerativeClustering(n_clusters=num_classes),
"DBSCAN": DBSCAN(eps=2, min_samples=5) # 参数需调节
}
# ===== 4. 聚类结果可视化(抽样二维PCA显示)=====
fig, axes = plt.subplots(1, 3, figsize=(13,4), constrained_layout=True)
for ax,(name,model) in zip(axes, models.items()):
labels_pred = model.fit_predict(X_pca)
sc = ax.scatter(X_pca[:,0], X_pca[:,1], c=labels_pred, cmap="tab20", s=5)
ax.set_title(name)
plt.suptitle("KSC 数据无监督聚类二维可视化", fontsize=14)
plt.show()
# ===== 5. 整图聚类(仅KMeans示例)=====
X_flat = X_cube.reshape(-1, b)
X_flat_std = scaler.transform(X_flat)
X_flat_pca = PCA(n_components=PCA_DIM, random_state=SEED).fit_transform(X_flat_std)
kmeans = KMeans(n_clusters=num_classes, random_state=SEED, n_init=10)
labels_full = kmeans.fit_predict(X_flat_pca).reshape(h, w)
plt.figure(figsize=(7,6))
plt.imshow(labels_full, cmap="tab20")
plt.title("KSC 整图无监督分类 (KMeans)")
plt.axis("off")
plt.show()
🔍 结果解读
-
二维散点图:通过 PCA 压缩后,可以直观看到不同聚类方法对样本的分组效果。
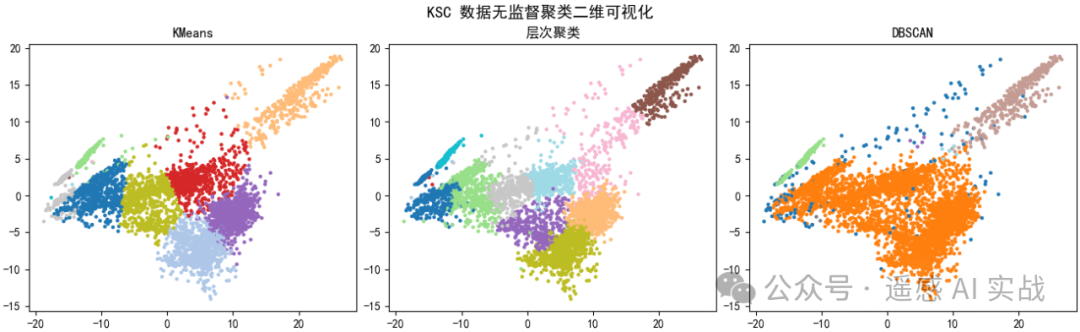
-
整图结果:KMeans 聚类后,整幅影像被自动划分为若干类别,虽然和真实标签不完全一致,但在缺乏样本时非常有参考价值。

-
不同方法特点:
-
KMeans:速度快,适合大规模影像;
-
Agglomerative:更适合小样本,能得到层次树状结构;
-
DBSCAN:能识别噪声,但需要调参,否则可能出现所有样本都归为一类的情况。
-
✅ 总结
-
sklearn.cluster提供了丰富的聚类方法,可作为 无监督分类基线。 -
在遥感实验中,聚类结果可作为 样本生成、模式探索 的辅助工具,尤其在缺乏标注时很有价值。
-
建议:先用 KMeans 快速跑一遍,再根据数据特点尝试层次聚类或 DBSCAN。
欢迎大家关注下方公众号获取更多内容!


















 43
43

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











