




在前几篇实战中,我们多次用到 StandardScaler 和 MinMaxScaler。有同学问:
“是不是预处理方法越复杂,分类效果就一定更好?”
答案是否定的。预处理的核心是 让特征尺度合理,但是否能提高分类精度,要看数据和模型。本篇通过实验直观对比几种常见预处理方式,看看它们对遥感分类的影响。
🧩 四种常见预处理方法
-
StandardScaler:均值=0,方差=1(最常用)。
-
MinMaxScaler:缩放到 [0,1] 区间。
-
RobustScaler:用中位数和 IQR,抗异常值。
-
Normalizer:把每个样本缩放到单位范数。
💻 实例代码:可视化 + 分类对比
# -*- coding: utf-8 -*-
"""
Sklearn案例⑨:预处理对比
1) PCA 投影可视化
2) 预处理+SVM 分类精度对比
"""
import os, numpy as np, scipy.io as sio, matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler, Normalizer
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# ===== 参数 =====
DATA_DIR = "your_path" # ← 修改为你的数据路径
PCA_DIM, TRAIN_RATIO, SEED = 30, 0.3, 42
# ===== 1. 加载数据(只取有标签像素) =====
X = sio.loadmat(os.path.join(DATA_DIR, "KSC.mat"))["KSC"].astype(np.float32)
Y = sio.loadmat(os.path.join(DATA_DIR, "KSC_gt.mat"))["KSC_gt"].astype(int)
coords = np.argwhere(Y != 0)
X_all = X[coords[:,0], coords[:,1]]
y_all = Y[coords[:,0], coords[:,1]] - 1
X_train, X_test, y_train, y_test = train_test_split(
X_all, y_all, train_size=TRAIN_RATIO, stratify=y_all, random_state=SEED
)
# ===== 2. 定义预处理方法 =====
scalers = {
"Standard": StandardScaler(),
"MinMax": MinMaxScaler(),
"Robust": RobustScaler(),
"Normalizer": Normalizer()
}
# ===== 3. 可视化:PCA 2D 投影对比 =====
plt.figure(figsize=(10,8))
for i, (name, scaler) in enumerate(scalers.items(), 1):
Xs = scaler.fit_transform(X_train)
pca = PCA(n_components=2, random_state=SEED).fit(Xs)
Xp = pca.transform(Xs)
plt.subplot(2,2,i)
plt.scatter(Xp[:,0], Xp[:,1], c=y_train, s=6, cmap="tab20")
plt.title(name); plt.axis("off")
plt.suptitle("不同预处理方法的特征分布(PCA投影)", fontsize=14)
plt.tight_layout(rect=[0,0,1,0.96])
plt.show()
# ===== 4. 分类精度对比(SVM) =====
results = {}
for name, scaler in scalers.items():
Xtr_s = scaler.fit_transform(X_train)
Xte_s = scaler.transform(X_test)
pca = PCA(n_components=PCA_DIM, random_state=SEED).fit(Xtr_s)
Xtr_p = pca.transform(Xtr_s)
Xte_p = pca.transform(Xte_s)
clf = SVC(kernel="rbf", C=20, gamma=0.005)
clf.fit(Xtr_p, y_train)
acc = accuracy_score(y_test, clf.predict(Xte_p))
results[name] = acc
print(f"{name:10s}: OA = {acc*100:.2f}%")
# ===== 5. 可视化分类精度 =====
plt.figure(figsize=(7,4))
names, accs = list(results.keys()), [v*100 for v in results.values()]
plt.bar(names, accs, color="skyblue")
for i,a in enumerate(accs):
plt.text(i, a+0.3, f"{a:.1f}%", ha='center')
plt.ylabel("Overall Accuracy (%)")
plt.title("不同预处理方法对比 (SVM分类器)")
plt.ylim(min(accs)-5, min(100,max(accs)+6))
plt.tight_layout(); plt.show()
🔍 结果与思考
PCA 可视化:不同预处理方法会改变特征的投影分布。
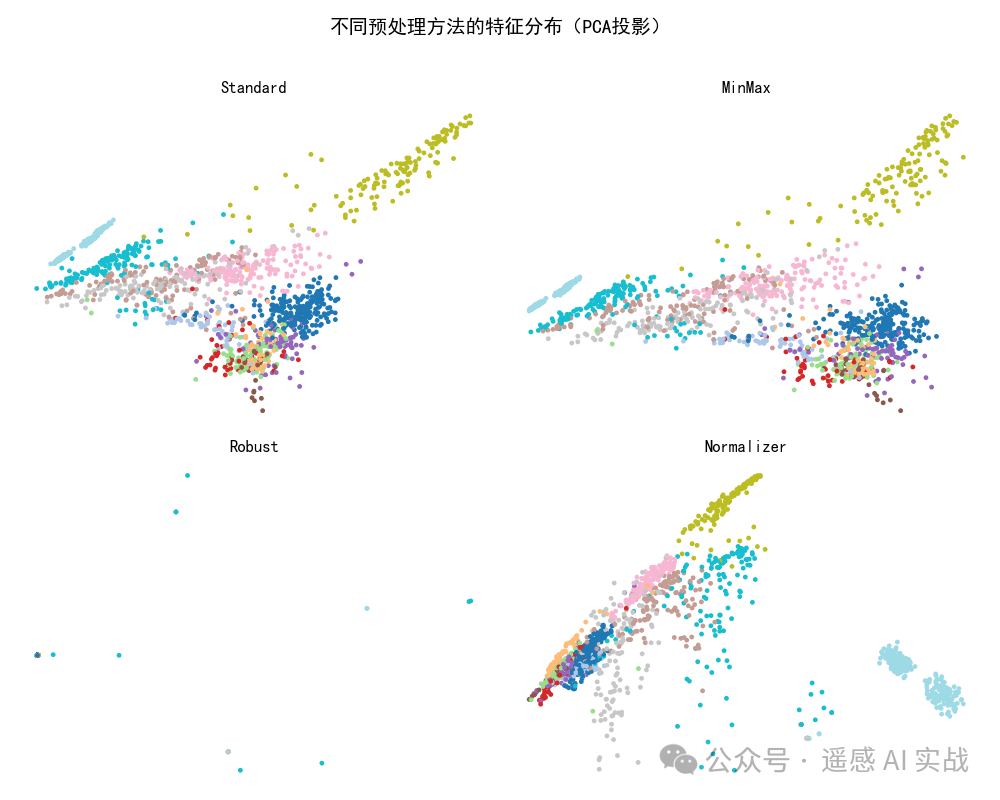
分类精度对比:有时差别不大,甚至可能几乎相同。
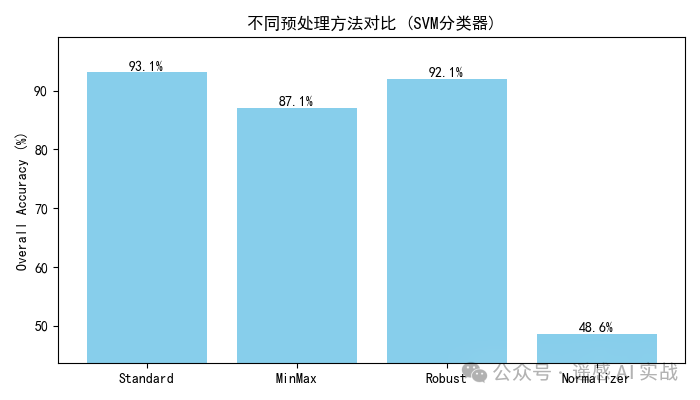
关键点:
-
-
StandardScaler 通常是安全的默认选项;
-
MinMaxScaler 在特征范围差异大时有帮助;
-
RobustScaler 抗异常值;
-
Normalizer 更适合做光谱角或方向性分析。
-
✅ 总结
-
预处理≠保证提升精度:它主要是为模型提供合理输入。
-
选择依赖场景:分类器 + 数据特征决定了预处理的必要性。
-
建议:做实验时至少尝试
StandardScaler和MinMaxScaler,并结合结果选择。
欢迎大家关注下方我的公众获取更多内容!


















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











