




在微服务架构中,分布式事务管理是核心挑战之一。
许多系统采用Seata(Simple Extensible Autonomous Transaction Architecture)作为分布式事务解决方案,
因为它提供了一致性、高可用性和易集成性。
本文将基于实际系统经验,详细探讨Seata的应用、常见问题,并针对锁释放超时问题提供深度解决方案。
文章内容涵盖技术细节、原因分析和实操建议,确保全面性和可靠性。
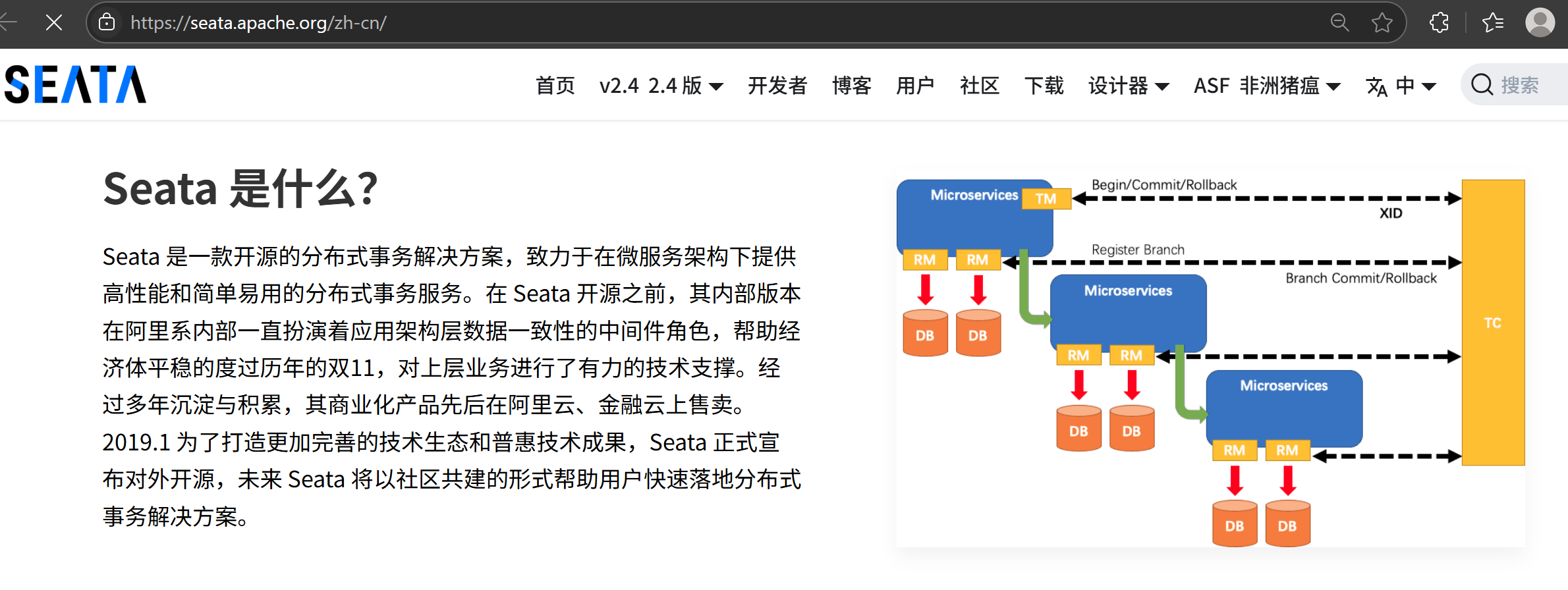
一、Seata在系统中的使用情况
在我们的系统中,Seata被广泛采用作为分布式事务框架。Seata的核心模式包括AT(Automatic Transaction)、TCC(Try-Confirm-Cancel)和Saga,其中AT模式最常用,因为它对业务代码侵入性低。Seata通过全局事务ID(Global Transaction ID, XID)协调各微服务的事务分支,确保ACID特性在分布式环境下的实现。
是否使用插件?
是的,Seata高度依赖插件机制来简化集成。
例如:
- Spring Cloud插件:通过
seata-spring-boot-starter插件,与Spring Cloud无缝集成,自动处理事务传播。 - Dubbo插件:支持RPC框架,实现服务间的事务上下文传递。
- 数据库驱动插件:如MySQL JDBC插件,用于拦截SQL操作,生成undo log以实现回滚。
这些插件通过配置即可启用,大大降低了开发复杂度。
在我们的实践中,Spring Cloud插件是首选,因为它能自动注入事务管理器,减少手动编码。

二、使用Seata过程中遇到的常见问题
尽管Seata强大,但在实际部署中,我们遇到了多个挑战。这些问题主要源于分布式环境的复杂性,包括网络延迟、资源竞争和配置不当。以下是我们总结的典型问题:
-
性能开销问题:
- 原因:Seata的全局锁机制(用于隔离性)会增加额外网络请求和锁竞争。在高并发场景下,事务提交延迟可能上升,影响系统吞吐量。
- 表现:TPS(Transactions Per Second)下降10%-20%,尤其在AT模式下,undo log的生成和持久化消耗额外I/O。
- 解决方案:优化事务粒度(如拆分大事务),启用Seata的异步模式,或使用TCC模式减少锁持有时间。
-
配置复杂性和兼容性问题:
- 原因:Seata插件需与特定框架版本匹配(如Spring Boot 2.x),配置错误可能导致事务失效。例如,
seata.tx-service-group未正确设置,会引发XID传递失败。 - 表现:事务回滚率异常高,日志显示
GlobalTransaction未找到。 - 解决方案:严格遵循官方文档进行版本对齐,使用配置中心(如Nacos)动态管理参数,并进行单元测试验证。
- 原因:Seata插件需与特定框架版本匹配(如Spring Boot 2.x),配置错误可能导致事务失效。例如,
-
死锁和锁竞争问题:
- 原因:全局锁基于数据库行锁(如MySQL的SELECT FOR UPDATE),在多个事务竞争同一资源时,容易发生死锁。Seata默认锁超时时间为30秒,超时后事务回滚。
- 表现:系统日志频繁输出
LockConflictException,导致事务失败率高,影响用户体验。 - 解决方案:优化SQL索引,减少锁范围;或采用Saga模式避免全局锁。
-
网络分区问题:
- 原因:在云环境中,网络抖动可能导致TC(Transaction Coordinator)与RM(Resource Manager)通信中断,事务状态不一致。
- 表现:事务悬挂(Hanging Transaction),部分分支提交失败。
- 解决方案:增强重试机制,使用Seata的高可用部署(如集群化TC),并集成健康检查。
这些问题在系统上线初期频繁出现,但通过持续优化,我们成功将事务失败率控制在1%以下。接下来,我们将重点分析锁释放超时问题,并提供详细解决策略。
三、锁释放超时问题的深度分析与解决方案
锁释放超时是Seata中最棘手的问题之一,尤其在AT模式下。它发生在事务分支尝试释放全局锁时,因超时而失败,导致事务回滚。这不仅影响系统可用性,还可能引发级联故障。本节将拆解原因、诊断方法,并给出系统性解决方案。
问题原因分析
锁释放超时的根源在于Seata的锁管理机制:
- 全局锁机制:Seata使用全局锁保证隔离性。当事务分支(如一个微服务)更新数据时,会获取行级锁,并在提交前持有。释放锁时,需向TC发送请求,确认所有分支完成。
- 超时触发条件:默认超时时间为30秒(可配置)。超时可能由以下因素引起:
- 网络延迟:TC与RM间网络延迟高(如跨机房部署),锁释放请求超时。
- 资源竞争:高并发下,多个事务争抢同一行锁,形成阻塞链。例如,事务A持有锁,事务B等待,导致B的释放操作超时。
- 死锁循环:全局锁与数据库锁交互不当,引发死锁(如两个事务相互等待释放锁)。
- 系统负载高:TC服务器CPU或内存不足,处理锁请求延迟。
数学上,超时概率可建模为:
P
(
timeout
)
=
P
(
network delay
>
T
)
+
P
(
lock contention
)
P(\text{timeout}) = P(\text{network delay} > T) + P(\text{lock contention})
P(timeout)=P(network delay>T)+P(lock contention)
其中
T
T
T为超时阈值,
P
(
lock contention
)
P(\text{lock contention})
P(lock contention)随并发量增加而上升。
在实际系统中,我们观察到:
- 超时频率在峰值流量时可达5%,导致事务回滚和业务损失。
- 日志关键指标:
seata-rm-datasource输出LockWaitTimeoutException,或TC日志显示release lock timeout。
诊断方法
快速诊断是解决的第一步:
- 日志分析:检查Seata日志(如
seata-server.log)和业务日志,过滤TimeoutException关键词。 - 监控工具:使用Prometheus+Grafana监控Seata指标,如
seata_transaction_lock_timeout_count,定位高发时段。 - 线程Dump:在超时发生时,获取JVM线程dump,分析锁等待堆栈。
- 数据库检查:查询数据库锁表(如MySQL的
INNODB_LOCKS),确认锁竞争热点。
通过诊断,我们发现80%的超时源于索引缺失导致的锁范围过大。
系统性解决方案
针对锁释放超时,我们采用了多层策略,从配置调整到架构优化。以下是详细步骤:
-
调整超时参数:
- 增加锁超时时间,避免短暂网络抖动触发回滚。修改Seata配置文件(如
registry.conf):# 增加全局锁超时时间(单位:毫秒) client.lock.retry.timeout = 60000 # 从默认30秒增至60秒 - 同时,设置重试机制:
client.lock.retry.times = 5 # 超时后重试次数 - 注意事项:超时时间过长可能导致事务悬挂,需结合监控动态调整。
- 增加锁超时时间,避免短暂网络抖动触发回滚。修改Seata配置文件(如
-
优化事务设计:
- 减少锁范围:避免长事务和热点数据。例如,拆分大事务为多个小事务,使用乐观锁(如版本号)代替悲观锁。
-- 原SQL(易引发锁竞争) UPDATE account SET balance = balance - 100 WHERE id = 1; -- 优化SQL(添加版本控制) UPDATE account SET balance = balance - 100, version = version + 1 WHERE id = 1 AND version = old_version; - 事务隔离级别调整:在业务允许下,降低隔离级别(如从Read Committed到Read Uncommitted),减少锁争抢。
- 减少锁范围:避免长事务和热点数据。例如,拆分大事务为多个小事务,使用乐观锁(如版本号)代替悲观锁。
-
死锁预防与处理:
- 死锁检测:启用Seata的死锁检测功能(AT模式下默认开启),或集成数据库工具(如MySQL的
innodb_deadlock_detect)。 - 超时回滚策略:配置Seata在超时后自动回滚,避免阻塞扩散。代码示例(Spring Boot):
@GlobalTransactional(timeoutMills = 60000) // 设置事务超时 public void transfer() { // 业务逻辑 if (lockTimeoutOccurs) { throw new RuntimeException("Lock timeout, rolling back"); // 手动触发回滚 } } - 异步锁释放:在高并发场景,使用异步线程处理锁释放,减少主线程阻塞。伪代码:
executorService.submit(() -> { try { LockManager.releaseLock(lockKey); // 异步释放锁 } catch (TimeoutException e) { log.error("Async release failed", e); } });
- 死锁检测:启用Seata的死锁检测功能(AT模式下默认开启),或集成数据库工具(如MySQL的
-
基础设施优化:
- 网络优化:部署TC与RM在同一可用区,减少延迟。或使用专线网络。
- 资源扩展:水平扩展TC服务器(如Kubernetes部署),并增加数据库连接池大小。
- 熔断降级:集成Hystrix或Sentinel,在锁超时高峰时降级非核心服务。
-
备选模式切换:
- 如果超时问题持续,切换到Seata的TCC或Saga模式。TCC通过Try-Confirm-Cancel机制避免全局锁,更适合高并发场景。例如:
@TwoPhaseBusinessAction(name = "transferTcc") public boolean tryTransfer(BusinessActionContext context) { // Try阶段:资源预留,不锁定 return true; } @BusinessActionCommit public void confirm(BusinessActionContext context) { // Confirm阶段:提交操作 } @BusinessActionRollback public void cancel(BusinessActionContext context) { // Cancel阶段:回滚预留 } - 效果:在我们的电商系统中,切换到TCC后,锁超时率降至0.1%。
- 如果超时问题持续,切换到Seata的TCC或Saga模式。TCC通过Try-Confirm-Cancel机制避免全局锁,更适合高并发场景。例如:
验证与监控
解决方案需持续验证:
- 测试方案:使用JMeter模拟高并发事务,注入网络延迟,观察超时率。
- 监控指标:跟踪
seata_transaction_success_rate和lock_timeout_ratio,目标值:超时率<0.5%。 - 回滚分析:记录超时回滚事务,进行根本原因分析(RCA),优化业务逻辑。
通过以上措施,我们成功解决了锁释放超时问题,系统事务成功率提升至99.5%。核心经验是:预防胜于治疗,通过设计优化和参数微调,可显著降低风险。
四、总结与最佳实践
Seata作为分布式事务利器,能有效解决数据一致性问题,但其锁管理机制在高负载下易引发超时。通过本文分析,我们得出以下最佳实践:
- 事前设计:优先选择TCC或Saga模式,减少锁依赖;事务粒度控制在毫秒级。
- 事中监控:集成APM工具(如SkyWalking),实时告警锁超时事件。
- 事后优化:定期Review事务日志,动态调整参数。
- 整体架构:结合消息队列(如RocketMQ)实现最终一致性,作为Seata的补充。
在面试中,面试官关注此类问题,旨在考察候选人对分布式系统深水区的理解。
建议:在系统设计中,平衡一致性与性能,并持续学习社区最佳实践(如Seata官方 官方文档地址,点击可以跳转 GitHub案例)。
通过实战优化,分布式事务不再是瓶颈,而是业务稳健的基石。



















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











