







 本文通过scikit-learn库探讨机器学习,包括加载数据、选择模型和预测应用。以iris数据集为例,展示了机器学习的三个基本步骤:数据获取、模型训练和预测。强调了模型选择和预测效果对机器学习的重要性。
本文通过scikit-learn库探讨机器学习,包括加载数据、选择模型和预测应用。以iris数据集为例,展示了机器学习的三个基本步骤:数据获取、模型训练和预测。强调了模型选择和预测效果对机器学习的重要性。
1 什么是机器学习
什么是机器学习?
这个问题不同的人员会有不同的理解。我个人觉得,用大白话来描述机器学习,就是让计算机能够通过一定方式的学习和训练,选择合适的模型,在遇到新输入的数据时,可以找出有用的信息,并预测潜在的需求。最终反映的结果就是,好像计算机或者其他设备跟人类一样具有智能化的特征,能够快速识别和选择有用的信息。
机器学习通常可以分为三个大的步骤,即 输入、整合、输出,可以用下图来表示大致的意思:
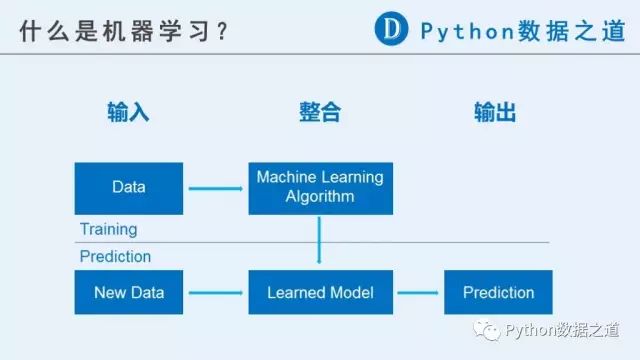
2 机器学习示例(scikit-learn)
在python语言中,scikit-learn是一个开源的机器学习库。下面以sklearn为例,来简单描述机器学习的过程。
2.1 加载数据
通常第一步是获取相关数据,并进行相应的处理,使之可以在后续过程中使用。
from sklearn import datasets
-
加载iris数据集并查看相关信息
# 加载数据集
iris = datasets.load_iris()
# print(iris)
print(type(iris))
print(iris.keys())
# 查看部分数据
print(iris.data[ :5, :])
# print(iris.data)
<class 'sklearn.datasets.base.Bunch'>
dict_keys(['DESCR', 'data', 'feature_names', 'target', 'target_names'])
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
# 查看数据维度大小
print(iris.data.shape)
# 数据属性
print(iris.feature_names)
# 特征名称
print(iris.target_names)
# 标签
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









