



(BO)Bayes-KELM回归(加交叉验证) 1-10折数可调,默认5折 Matlab代码 基于贝叶斯算法(BO/Bayes)优化核极限学习机(KELM)的数据回归预测(可以更换为单、多变量时序预测/分类,前选一),可直接运行,适合小白新手 程序已经调试好,无需更改代码替换数据集即可运行数据格式为excel KELM也可定制更换为其他模型例如:SVM,RF,RBF,LSSVM,DBN,XGBoost等 1、运行环境要求MATLAB版本为2018b及其以上 2、评价指标包括:R2、MAE、MSE、RPD、RMSE等,图很多,符合您的需要 3、代码中文注释清晰,质量极高 4、测试数据集,可以直接运行源程序 替换你的数据即可用 适合新手小白 5、 保证源程序运行,
最近在玩回归预测时发现了个有意思的套路——用贝叶斯优化给KELM模型调参,顺手撸了个Matlab版本。这玩意儿最大的优点就是不用手动调参,对刚入门的朋友特别友好。下面直接上干货,咱们边看代码边唠。
先看核心代码架构:
function BO_KELM_regression()
% 数据读取
data = xlsread('数据集.xlsx');
input = data(:,1:end-1); % 前N列为输入
output = data(:,end); % 最后一列为输出
% 贝叶斯优化设置
optVars = [optimizableVariable('C',[1e-3,1e3],'Transform','log') % 正则化系数
optimizableVariable('sigma',[1e-3,1e3],'Transform','log')]; % 核参数
% 启动优化
BayesObject = bayesopt(@(params)CV_loss(params,input,output), optVars,...
'MaxTime', 300, 'IsObjectiveDeterministic', true); % 最多跑5分钟
% 获取最优参数
bestParams = BayesObject.bestPoint;
% 完整训练
[~, model] = KELM_train(input, output, bestParams.C, bestParams.sigma);
% 预测与评估
pred = KELM_predict(input, model);
show_metrics(output, pred); % 输出R2等指标
end这段代码有意思的地方在于用贝叶斯优化替代了传统网格搜索。举个例子,核参数sigma的搜索范围是1e-3到1e3,但贝叶斯会自动聚焦到有效区域,避免了暴力搜索的耗时问题。
重点看交叉验证部分的实现:
function loss = CV_loss(params, input, output)
k = 5; % 默认5折,可改成1-10任意值
indices = crossvalind('Kfold', output, k);
tmp_loss = zeros(k,1);
for i = 1:k
% 划分训练集验证集
val_idx = (indices == i);
train_X = input(~val_idx,:); train_Y = output(~val_idx);
val_X = input(val_idx,:); val_Y = output(val_idx);
% 训练子模型
[~, sub_model] = KELM_train(train_X, train_Y, params.C, params.sigma);
% 验证预测
pred = KELM_predict(val_X, sub_model);
tmp_loss(i) = sqrt(mean((pred - val_Y).^2)); % RMSE作为损失
end
loss = mean(tmp_loss);
end这里有个新手容易踩的坑:交叉验证的索引生成一定要基于output而不是input,特别是时序数据要防止未来信息泄漏。比如做时间序列预测时,应该按时间顺序分折而不是随机划分。
模型训练的核心其实很简洁:
function [kernel, model] = KELM_train(X, Y, C, sigma)
% 核矩阵计算
kernel = kernel_matrix(X, X, sigma, 'RBF_kernel');
% 求解对偶问题
Omega = kernel + eye(size(kernel))/C;
model = Omega \ Y; % 核心求解公式
end这里用的是正则化最小二乘解法,注意当数据量过大时(比如超过1万样本),直接求逆可能会内存爆炸。不过对于新手日常使用的小数据集完全没问题。
替换数据集的操作巨简单:把Excel文件放在同一目录,确保最后一列是输出变量。比如你的数据是3输入1输出,excel排列应该是:
| 特征1 | 特征2 | 特征3 | 目标值 |
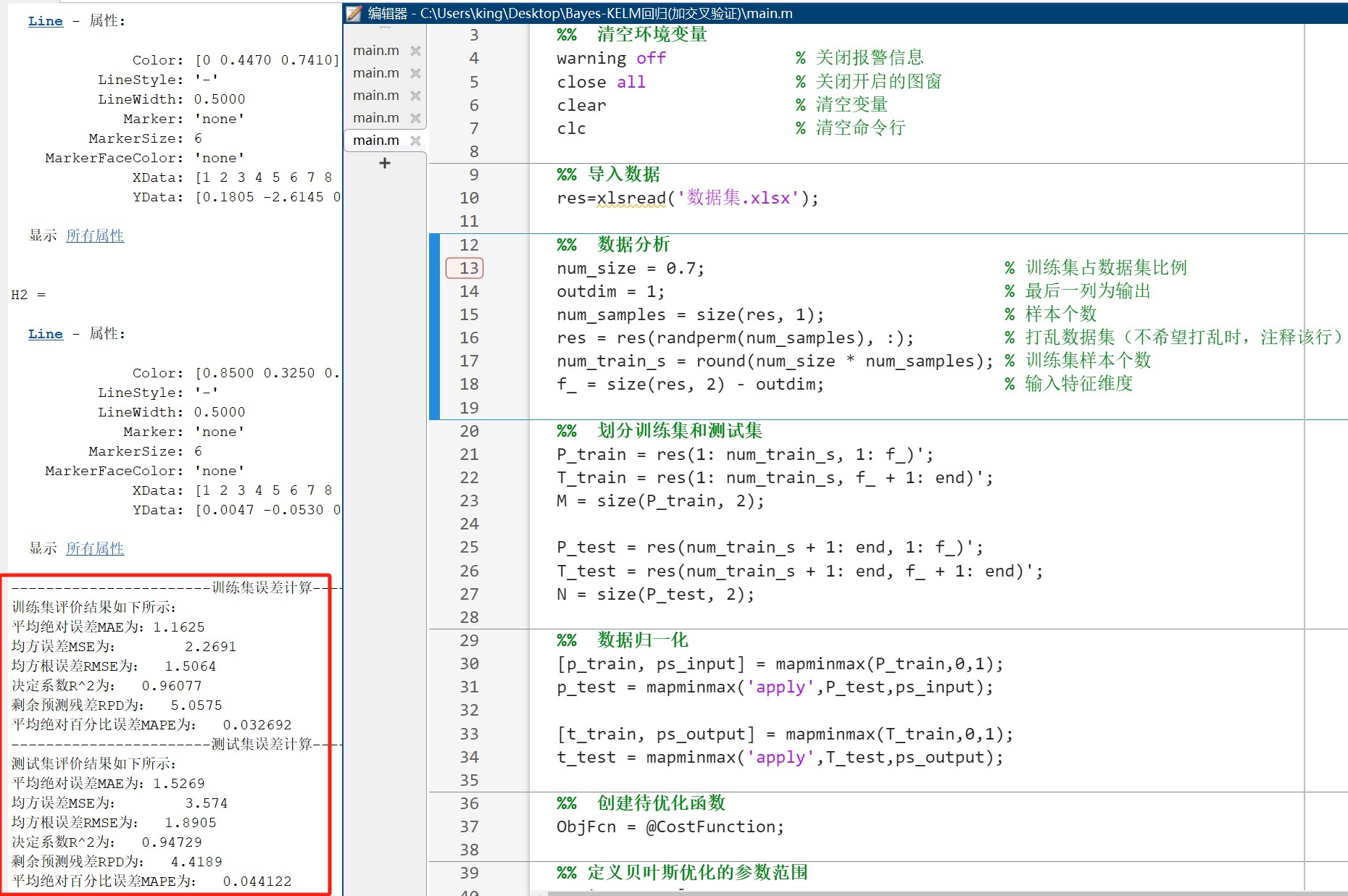
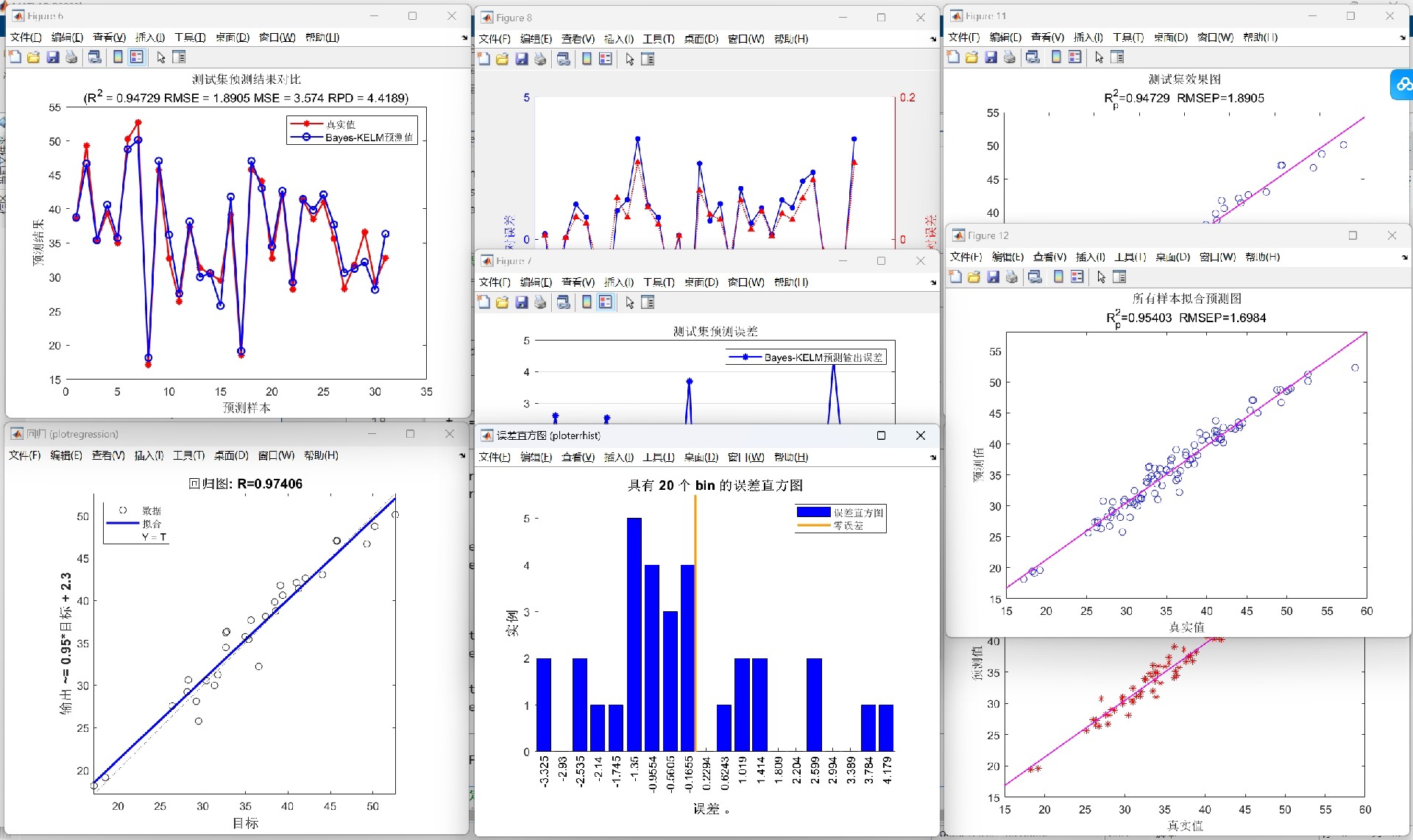
运行后会输出这样的结果:
R2: 0.928 MAE: 1.24
预测值与真实值对比图已生成
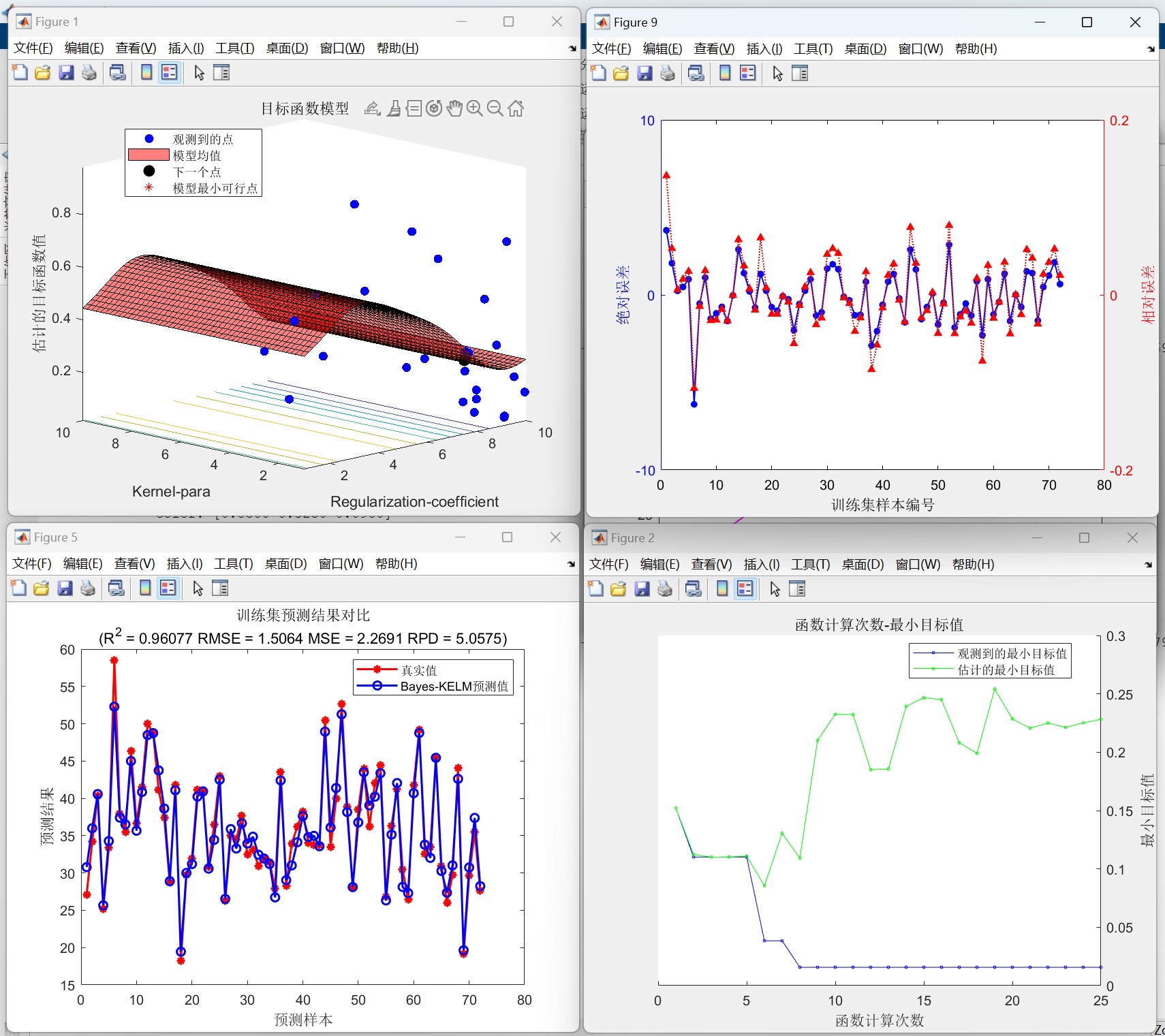
优化过程收敛曲线已保存如果想换模型,比如改成SVM,只需要修改两处:
- 把KELM_train换成libsvm的训练函数
- 调整贝叶斯优化的参数范围(比如SVM需要优化惩罚系数C和核宽sigma)
最后给个实用小技巧:如果发现优化时间太长,可以把bayesopt里的'MaxTime'参数调小,或者减少最大迭代次数。实测在i5处理器上跑千量级样本,5折交叉验证大概3分钟就能出结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









