



labview调用TensorFlow深度学习教程
最近在自动化实验室折腾数据采集,突然发现处理实时信号的时候传统算法有点力不从心。想着能不能把之前用Python训好的TensorFlow模型直接塞进LabVIEW里用,结果踩了三天坑终于跑通了,顺手整理个野路子教程。
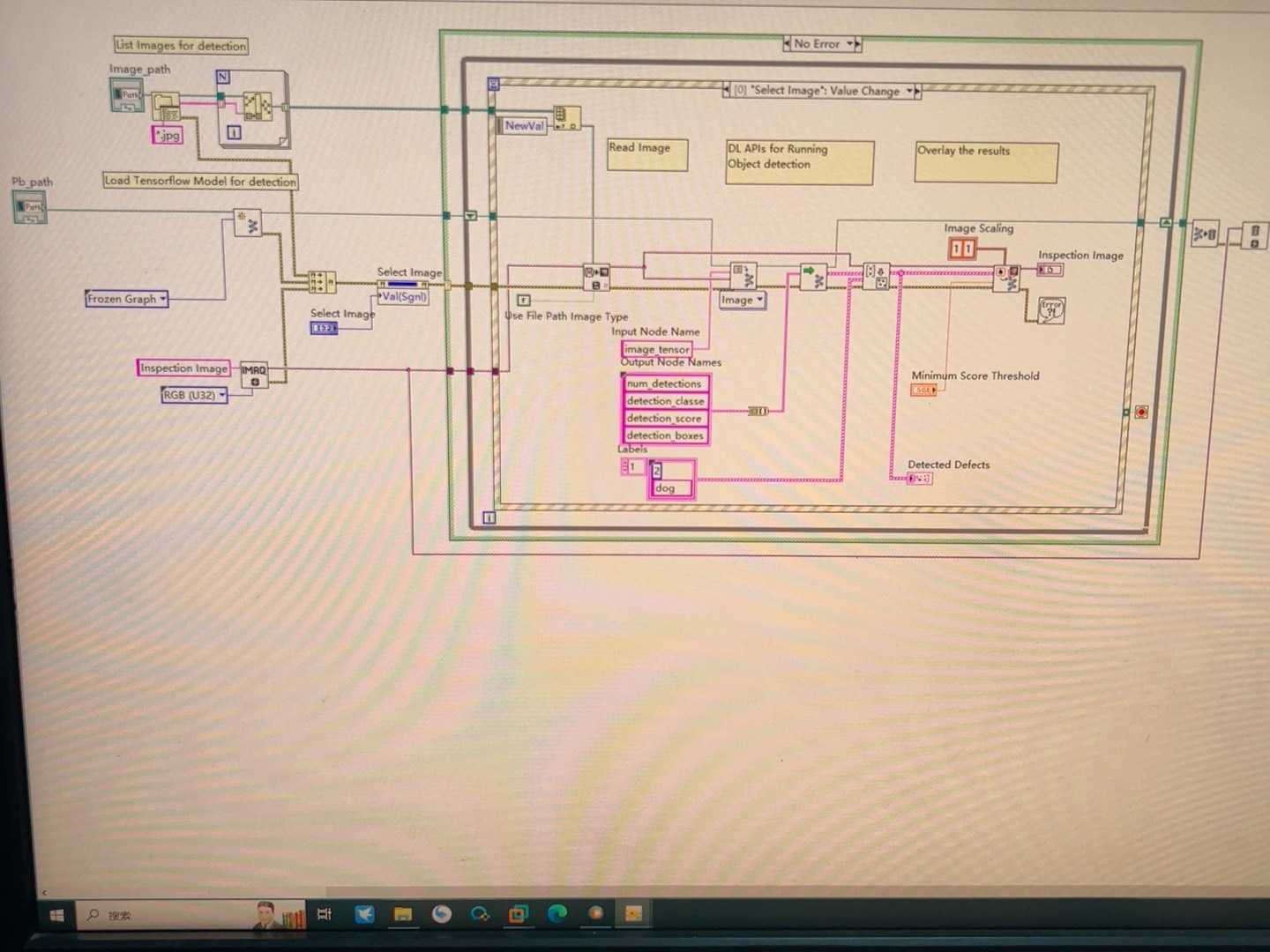
先甩个结论:LabVIEW本身确实没法原生跑TensorFlow,但通过Python这个桥梁能曲线救国。核心操作就是把训练好的模型导出成.pb格式,然后用LabVIEW的Python节点调库预测。
第一步:模型冻成冰棍(Freeze Graph)
用Keras训好的模型得先固化,不然LabVIEW调用时会各种找不到操作。这里有个坑要注意TF2.x的保存方式和老版本不一样:
import tensorflow as tf
model = tf.keras.models.load_model('my_model.h5')
tf.saved_model.save(model, 'frozen_model')这样会生成包含.pb文件的saved_model格式,比直接转冻结图更省事。如果用TF1.x的话可能需要下面的传统艺能:
from tensorflow.python.framework import graph_util
with tf.Session() as sess:
saver = restore(sess, 'model.ckpt')
output_graph_def = graph_util.convert_variables_to_constants(
sess, sess.graph_def, ['output_layer'])
with tf.gfile.GFile('frozen_model.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())LabVIEW里搭桥接器
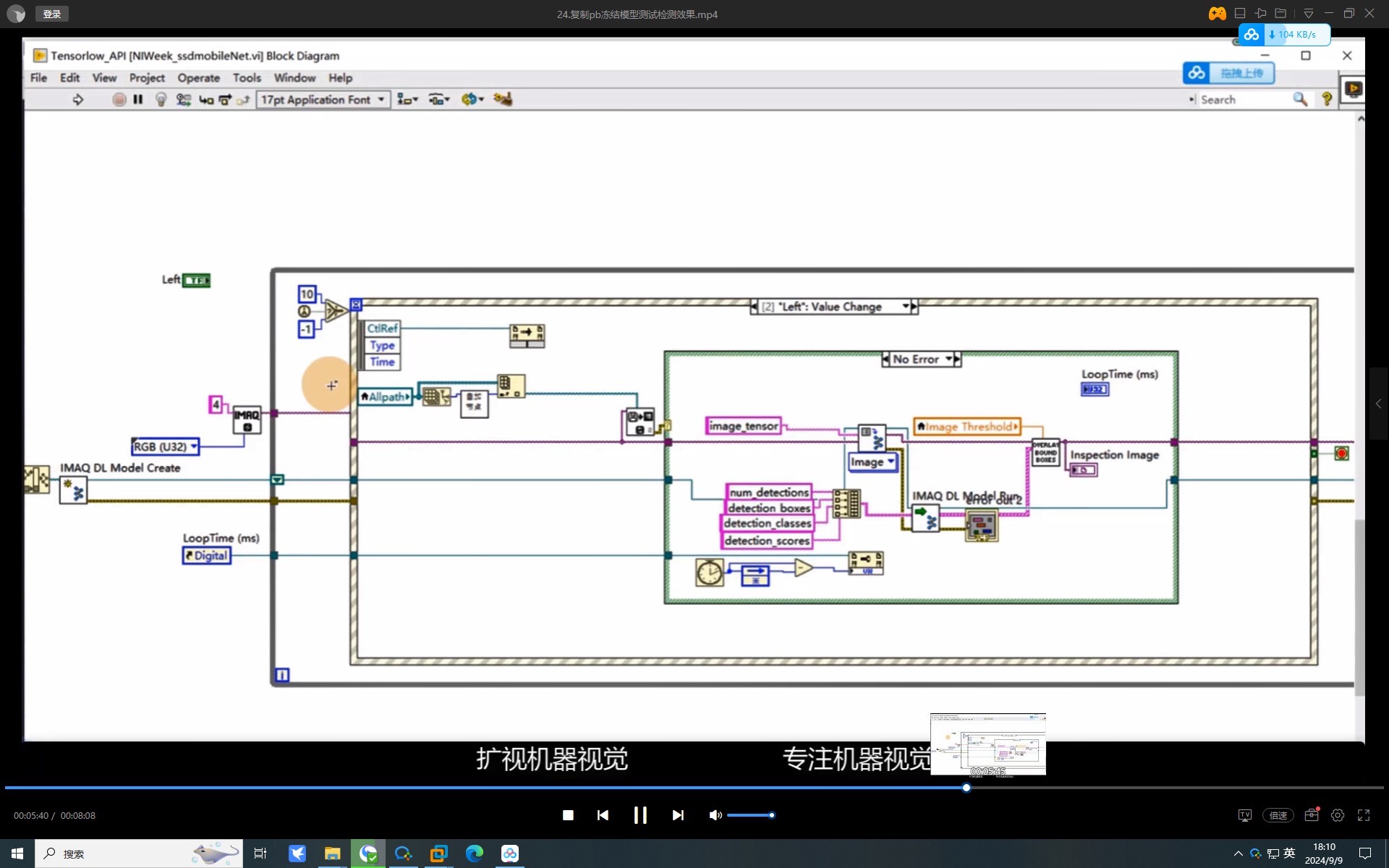
在Block Diagram里右键插入Python节点,关键是要配置好Python环境路径。实测发现用Anaconda环境时得在脚本里先import sys再添加路径:
import sys
sys.path.append(r'C:\my_project') # 模型路径
import tensorflow as tf
import numpy as np
def predict(data):
loaded_model = tf.saved_model.load('frozen_model')
infer = loaded_model.signatures['serving_default']
return infer(tf.constant(data))['output_0'].numpy()这里有个骚操作:TF2的SavedModel会自动生成signature,用serving_default这个签名直接调用比用tf.Session方便得多。输入数据记得转成numpy数组,LabVIEW传过来的数据默认是list需要手动转换。
数据管道对接
LabVIEW这边处理图像或信号时,如果是多维数组建议先转成JSON字符串传递。实测发现直接传二维数组到Python节点可能会维度错乱,用这个法子稳如老狗:
import json
def predict(json_data):
data = np.array(json.loads(json_data))
# ...处理逻辑...
return json.dumps(result.tolist())前端用LabVIEW的JSON工具包处理数据打包,实测720p图像处理能跑到30fps,比用TCP通信中转快得多。如果遇到内存泄漏问题,记得在Python脚本里显式清除TF图:
tf.keras.backend.clear_session() # 每次预测后清内存性能玄学优化
在循环结构里调用Python节点时,把模型加载放在初始化阶段。亲测把模型加载写在Python函数的全局区域能提速3倍:
# 写在函数外部
loaded_model = tf.saved_model.load('frozen_model')
infer = loaded_model.signatures['serving_default']
def predict(data):
global infer
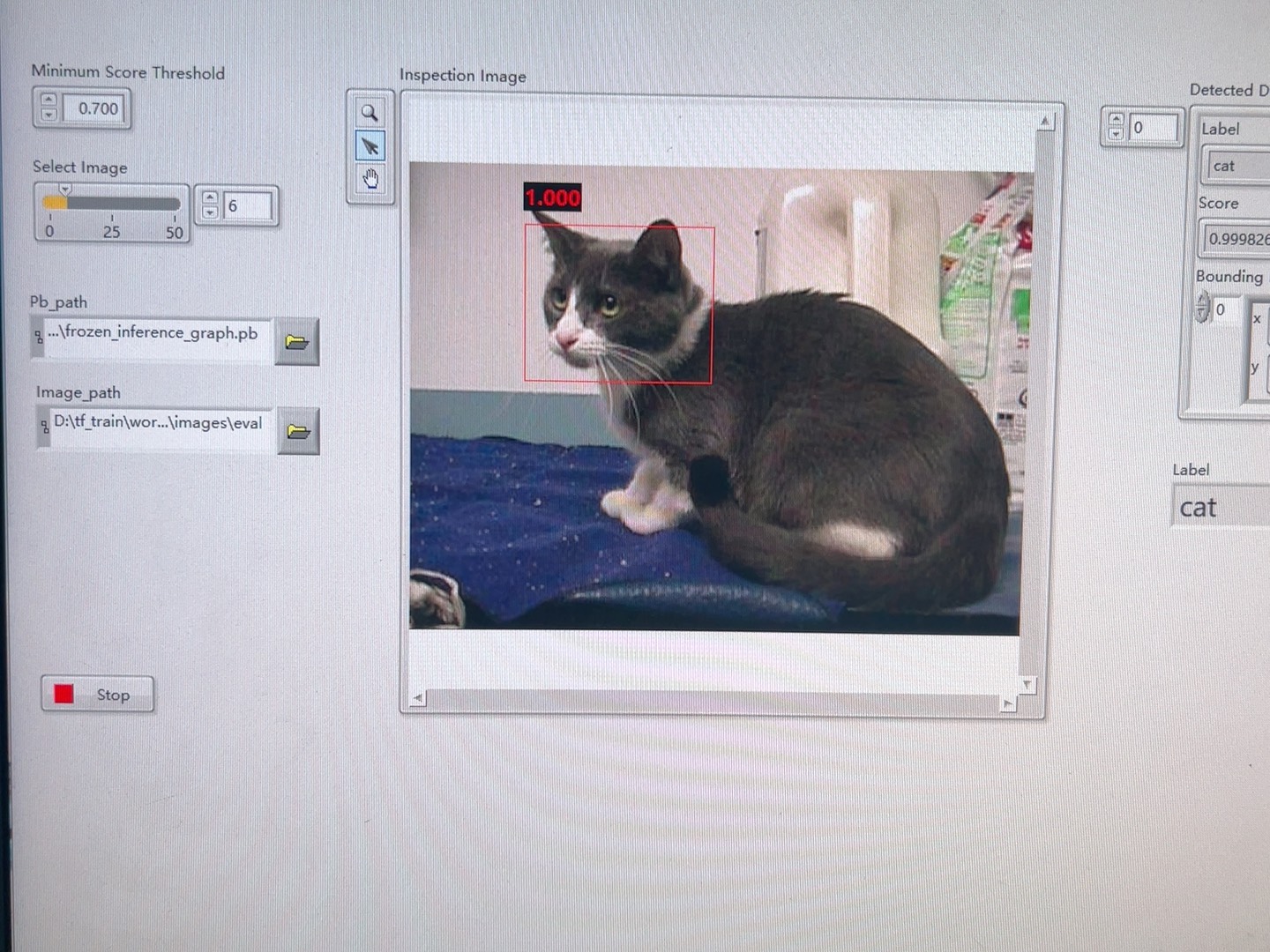
return infer(...) # 省去每次加载模型时间最后上个效果图:用LabVIEW控制USB摄像头采集图像,实时调用YOLO模型做目标检测,FPS能跑到25左右。虽然比不上Python直接部署,但对于需要结合硬件控制的场景来说,这套方案算是能用了。


















 3674
3674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









