




2.1 小批量梯度下降
应用:深度学习处理大数据集的时候会选用小批量梯度下降算法
深度学习在大数据领域应用广泛,但是海量数据的训练又涉及速度问题,所以选择算法就尤其重要。
批量梯度下降:可以同时处理整个训练集(完整的训练集X,Y)
举例:把一个500w的训练集分成1000份,每份5000个训练集。

小批量梯度下降:
每次只处理一个mini batch,X{t},Y{t},而不是一次处理完整的训练集XY

2.2 理解小批量梯度下降

使用小批量梯度下降:必须要指定minibatch-size,它是一个超参数

minibatch大小的确认。如果训练集小于2000,可以直接用批量梯度下降。

minibatch size是一个超参数,不知道咋选的时候就在下面几个里头实验。找一个能让梯度下降最有效率的值。

2.3 指数加权平均
概念:这个公式就是指数加权平均
![]()

2.4 理解指数加权平均
每天得到的theta值 =β*(前一天的theta)+(1-β)*当天的Vtheta的值,
优势:只需要一行代码
缺点:如果保存所有最近的温度数据,和过去 10 天的总和,必须占用更多的内存,执行更加复杂

2.5 指数加权平均的偏差修正
后期β的影响几乎被消除,所以使用之前的指数加权平均公式即可。

2.6 动量梯度下降法
还有一种算法叫做 Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标
准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度
更新你的权重,
我们希望在垂直方向减慢速度。在水平方向所有导数指向右边,并且移动更快。(削减前往最小值的路径上的震荡)


所以你有两个超参数,学习率𝑎以及参数𝛽,𝛽控制着指数加权平均数。𝛽最常用的值是 0.9,
在实现动量梯度下降的时候不需要进行平均偏差修正
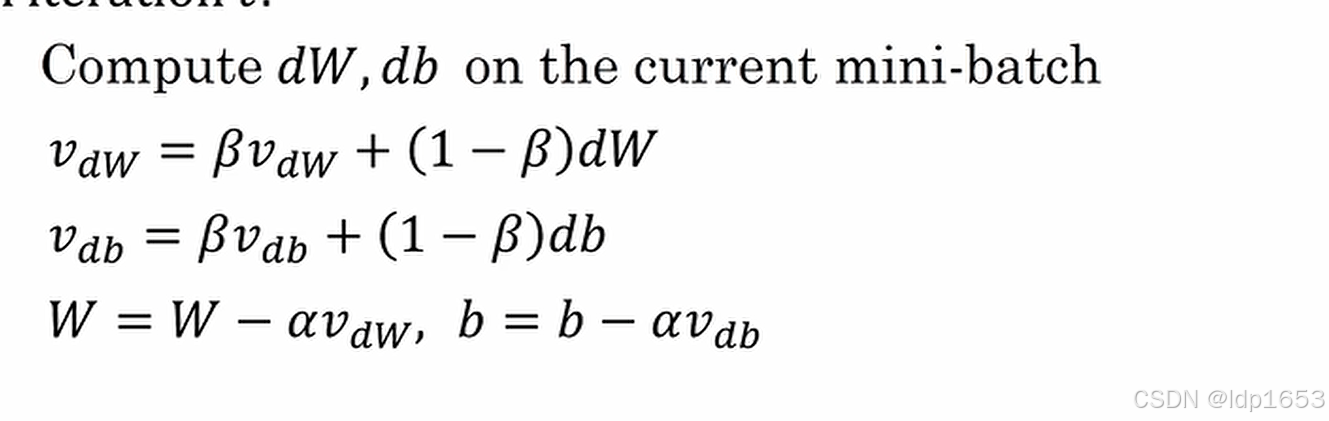
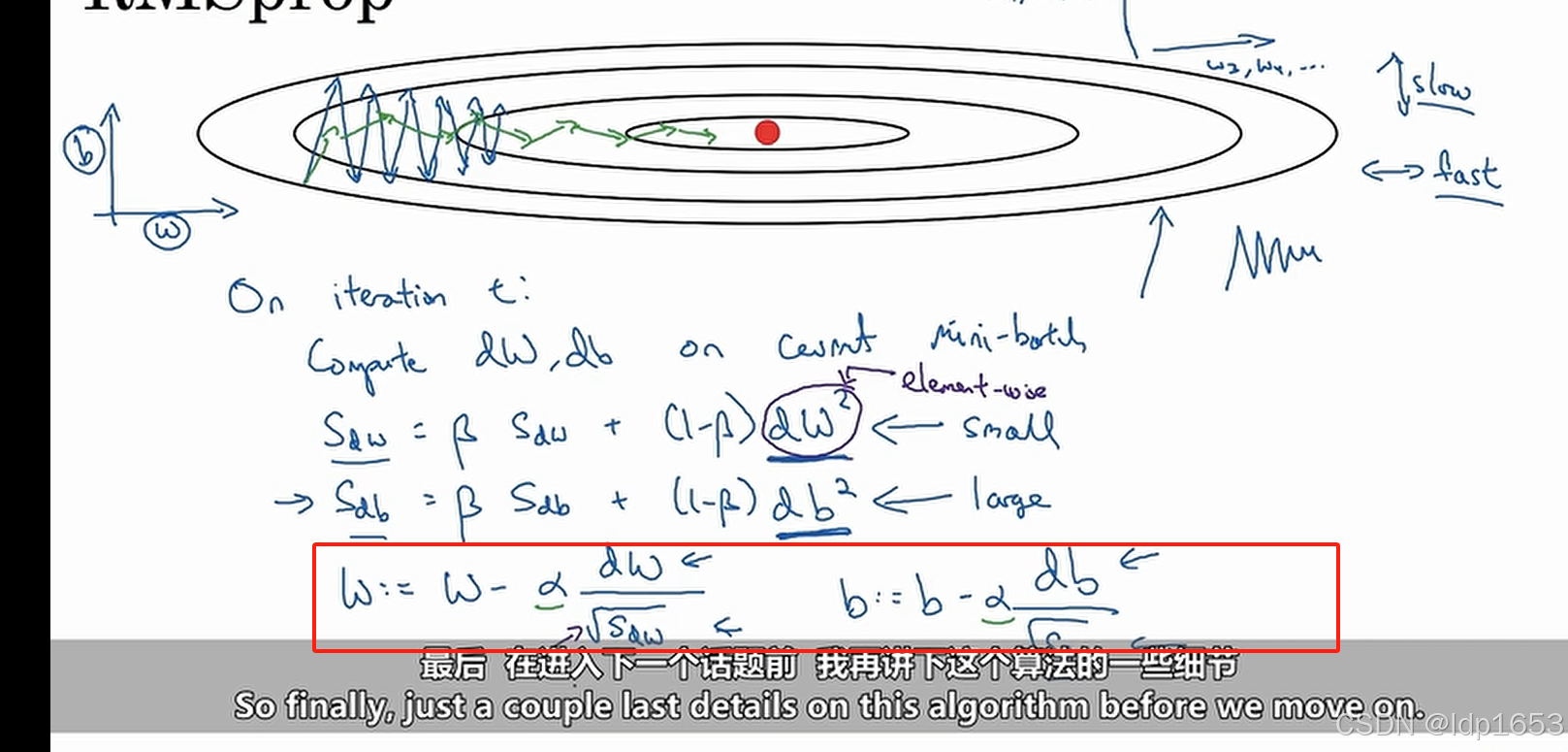
2.7 RMS prop(均方根传递)--实用性比较强的算法
用途:降低梯度下降和小批量梯度下降中的震荡,并允许你使用更大的α,从而提高算法学习速度。
2.8 Adam自适应矩估计优化算法--很强的算法,在很多神经网络都有效
adam优化算法中需要使用到偏差修正
红框里就是adam优化算法。
在分母上加上一个很小很小的𝜀,𝜀是多少没关系,10−8 次方是个不错的选择,这只是保证数值能稳定一些是为了防止分母趋近于0

涉及的超参数:

2.9学习速率衰减
控制学习率实际上是优化中比较靠后的一项。重点是先在一个固定的学习率上把模型优化好。
α减少会让步伐变小,参考绿色线在最小值附近的走势变化。

学习率衰减函数:

其他控制学习率的公式

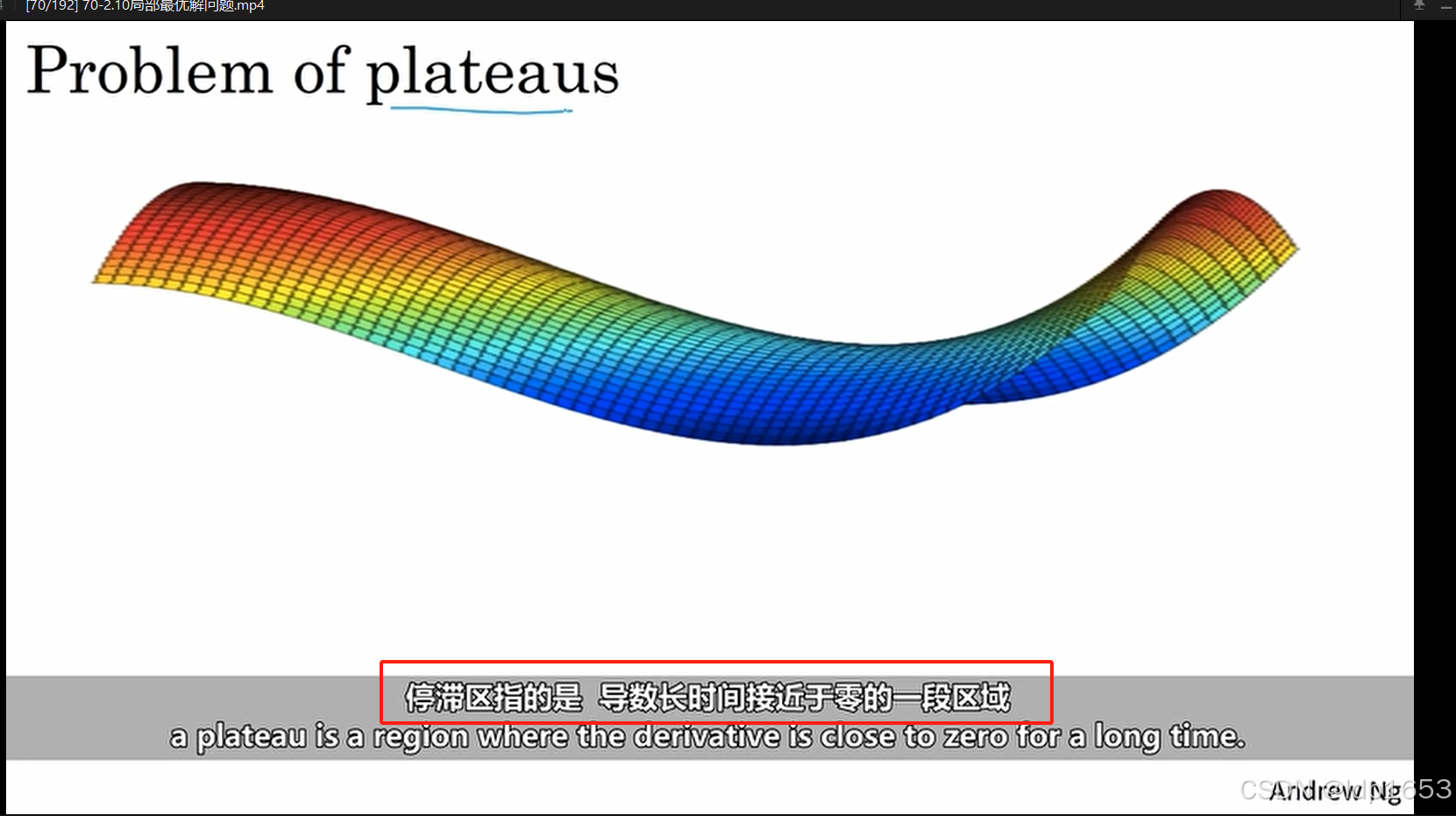
2.10 局部最优解问题
停滞区:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









