



架构
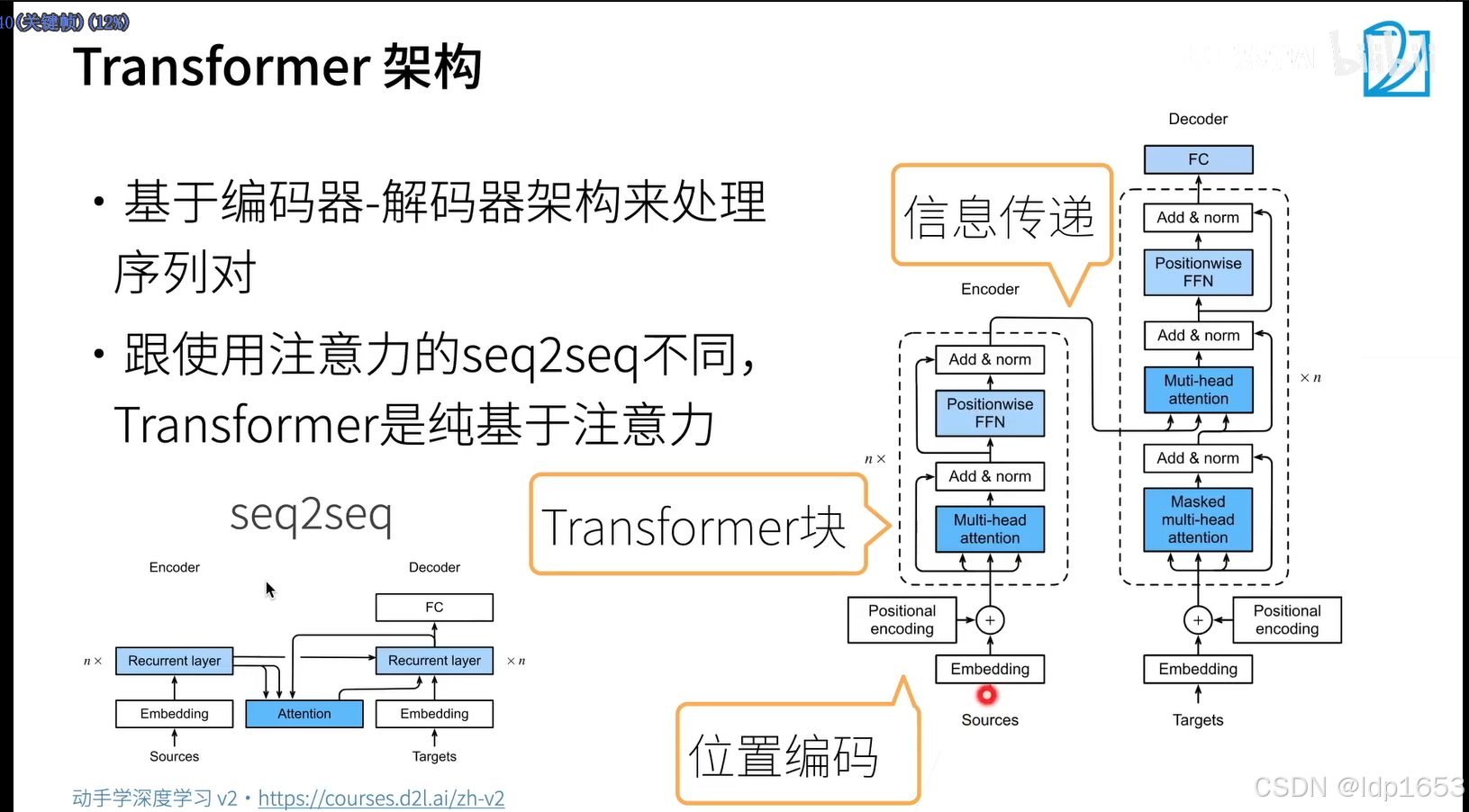
多头注意力
这里有两个头,输入 Q K V

掩码用来屏蔽后续元素对解码器的影响

b batchsize n序列长度 d demision
n会变。n是序列长度,所以不能吧n作为特征。所以就把b和n相乘。输出的时候再变回b,n,d

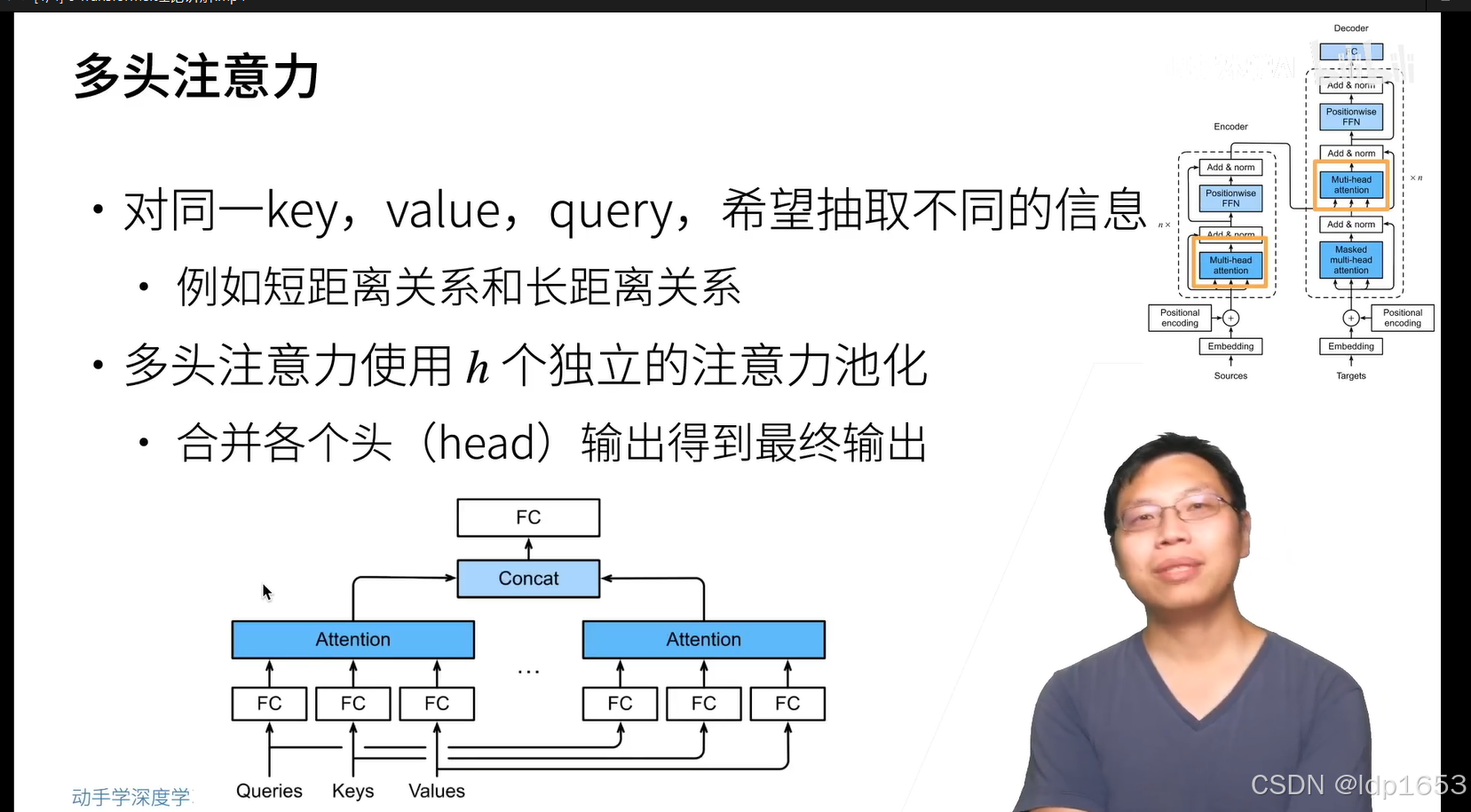
这里不能用batch normalization。只能用Layer Norm,
因为batch norm是对每一个特征向量进行归一化。
b:batch size
d:特征
len:序列长度
选择层归一化而非批归一化的原因主要有以下几点:
-
序列长度不固定:在自然语言处理任务中,输入序列的长度往往是变化的,而批归一化通常要求固定的输入尺寸,特别是在处理变长序列时较为不便。
-
独立于批量大小:层归一化不依赖于批量大小,因此对于不同大小的批次具有更好的适应性。这对于使用动态批量大小或在在线学习场景下尤为重要。
-
适用于RNN/LSTM/Transformer等结构:层归一化更适合循环神经网络(RNN)、长短期记忆网络(LSTM)以及Transformer等架构,因为它针对的是特征维度上的归一化,而不是批量维度,这有助于维护序列内部的相关性。
线表示信息传递

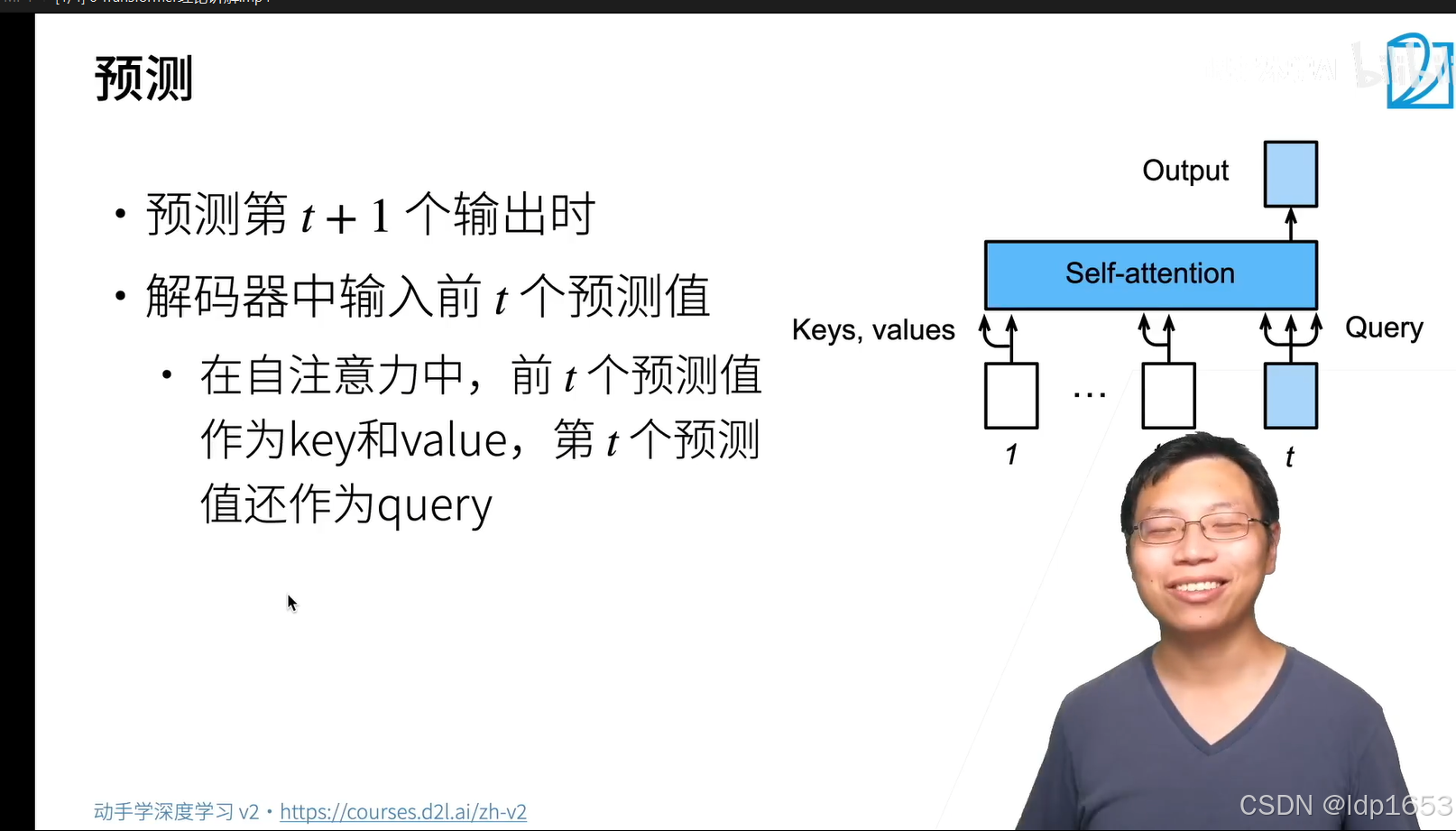
做预测的时候还是一个一个往前走这样预测,根据前面的值预测后面的值。
训练的时候是都扔进去,可以同时计算。

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









