




3.1 参数调整过程
第一点.选择超参调优顺序
调优顺序:
1.学习率α
2.β,minibatch size ,hiddenunit(隐藏单元数量)
3.layers网络层数,学习率衰减

第二点就是,超参要用随机值。

第三点.从粗到精

3.2 使用适当的标准来选择超参数
根据函数的值域来选择超参数的取值,有的时候均匀取值并不是最优解,
有时需要结合对数来对超参取值,这样才能使搜索资源平均分配
3.3 实践中的超参数调整
只训练一个模型,也叫熊猫模型

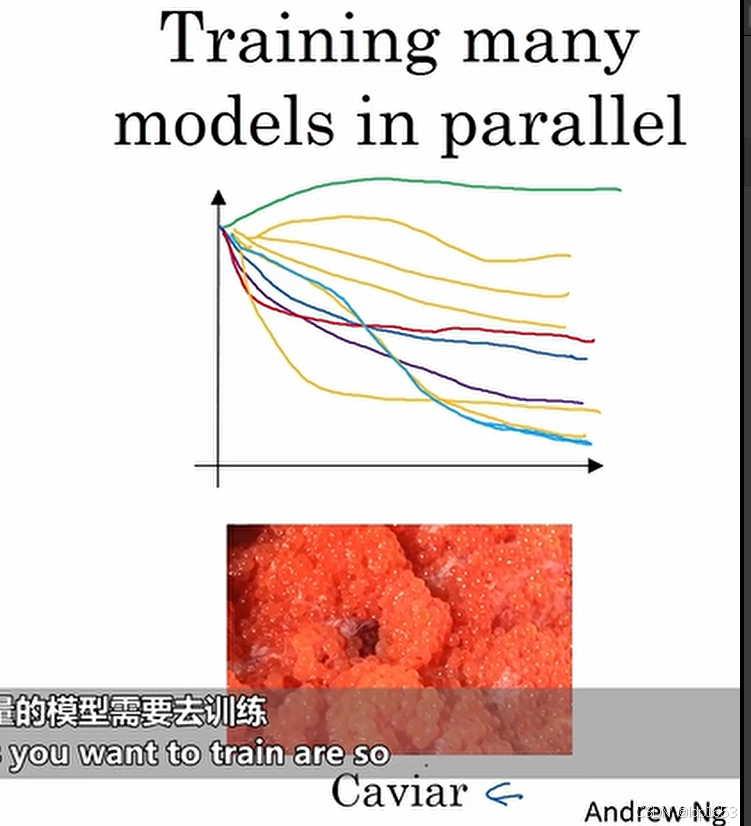
同时训练很多模型
期待某一个模型能ok就行,也叫鱼子酱模式。
3.4 归一化网络的激活函数(Batch Norm) (也叫BN算法)
批量归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会让你的训练更加容易,甚至是深层网络


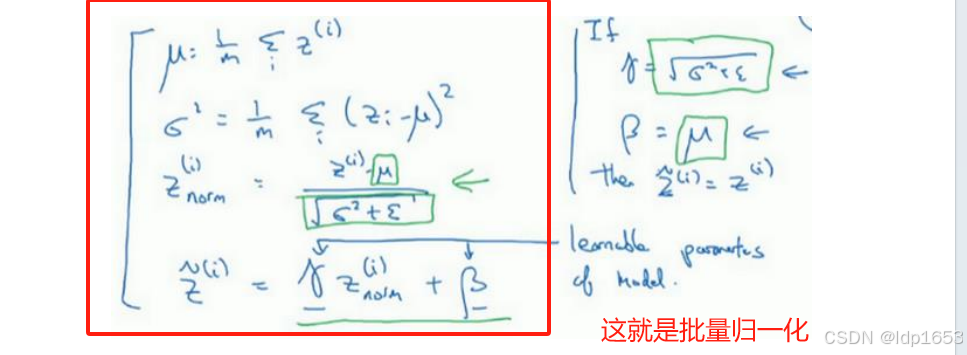 最终达到的效果就是通过 𝛾和β 来控制隐藏层的方差和标准差(自由控制 让z(i)是任何值)
最终达到的效果就是通过 𝛾和β 来控制隐藏层的方差和标准差(自由控制 让z(i)是任何值)3.5 把batch norm拟合到神经网络
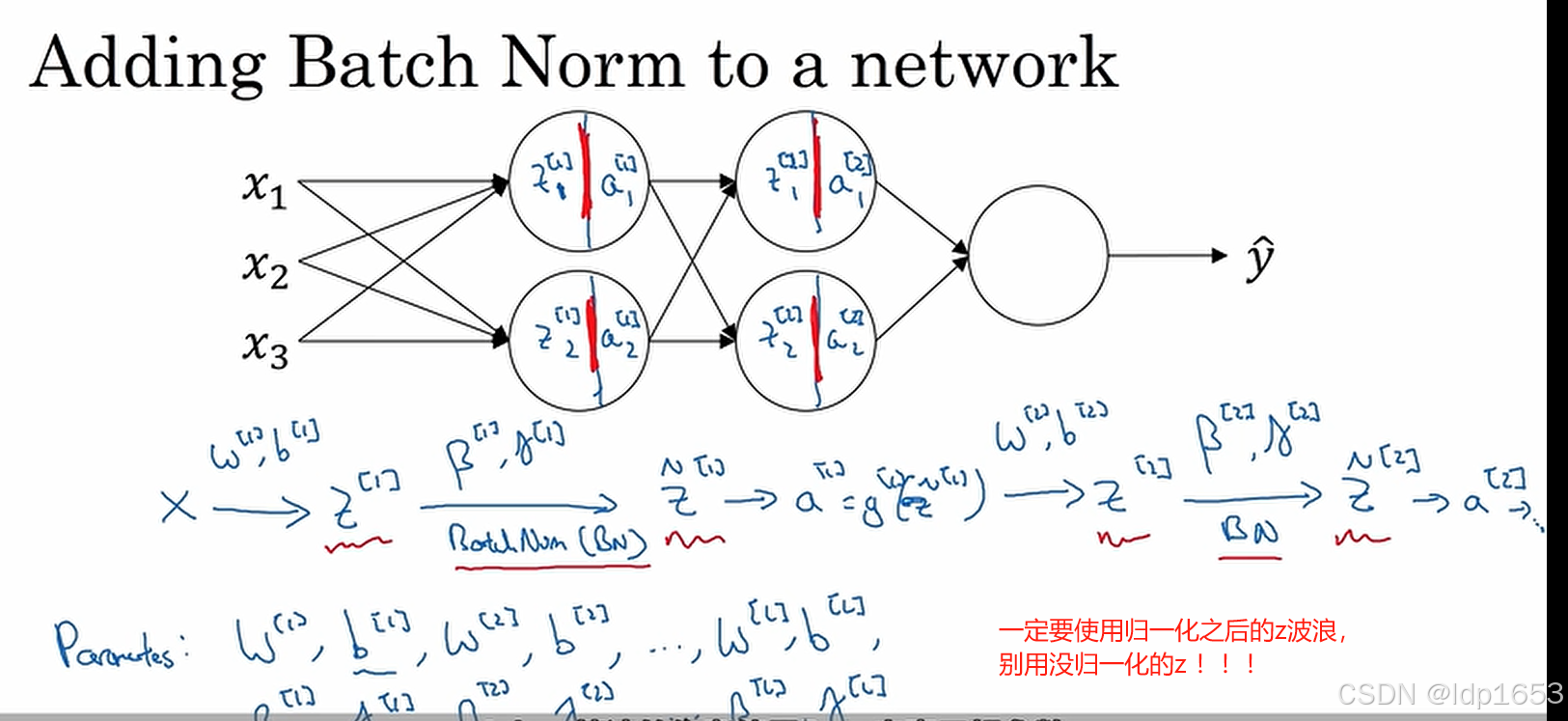 、
、
BN算法在深度学习框架里已经实现,可能就是一行代码。
实际上 BN算法一般用在mini-batch上面
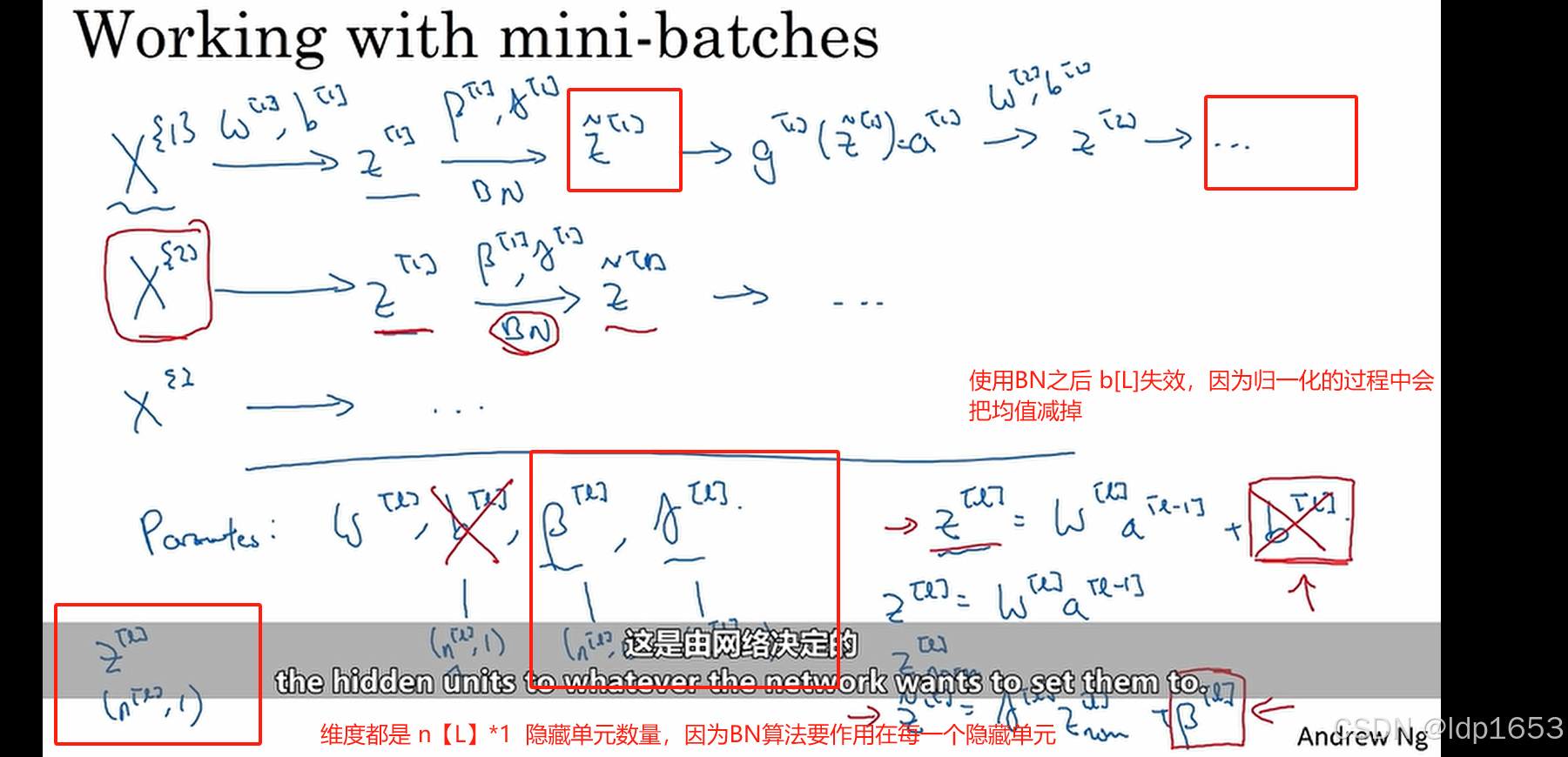

3.6 为什么BN有效
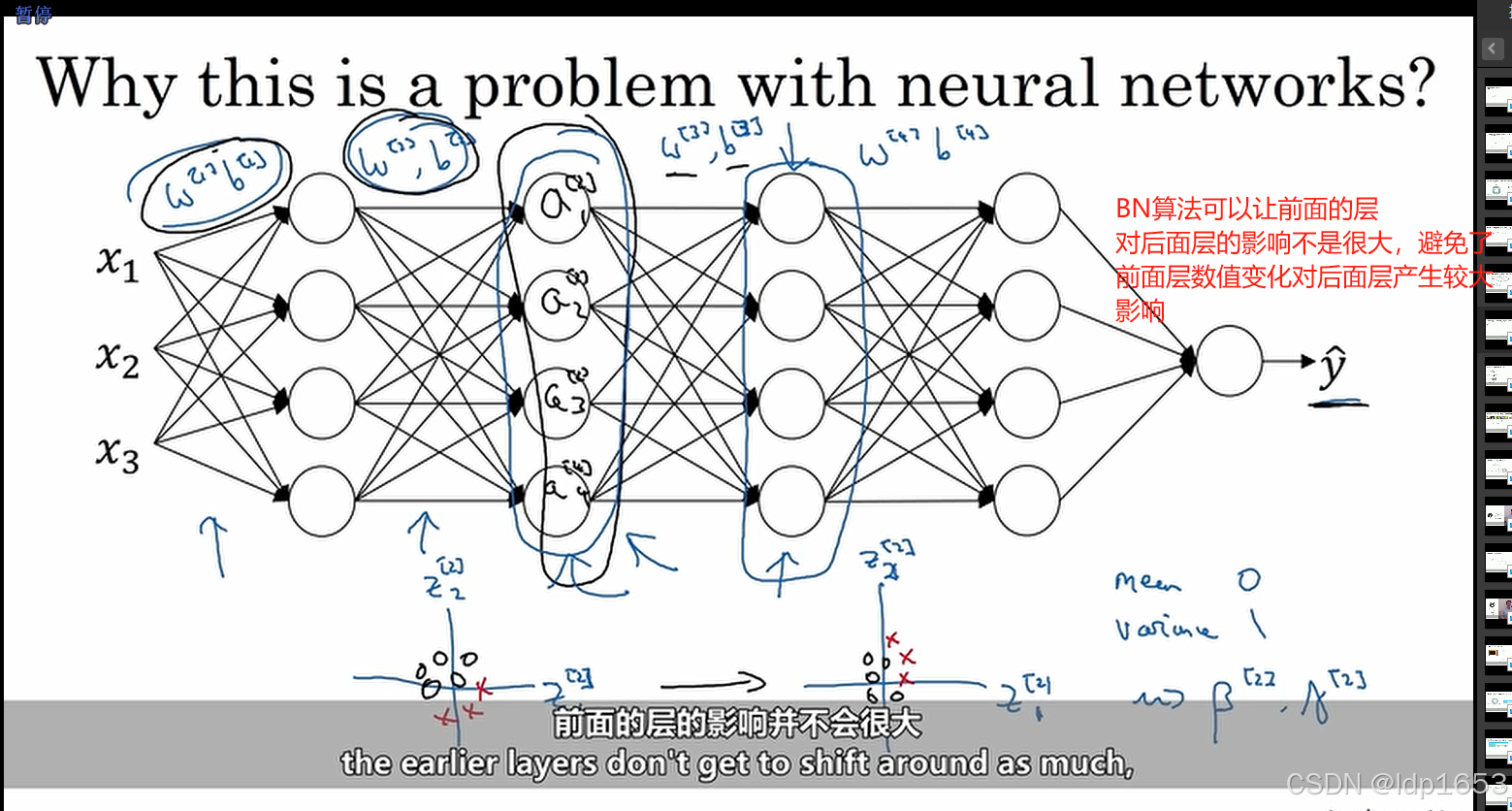
3.8 softmax分类
Softmax 回归,能让你在试图识别某一分类时做出预测,或者说是多种分类中的一个,不只是识别两个分类,
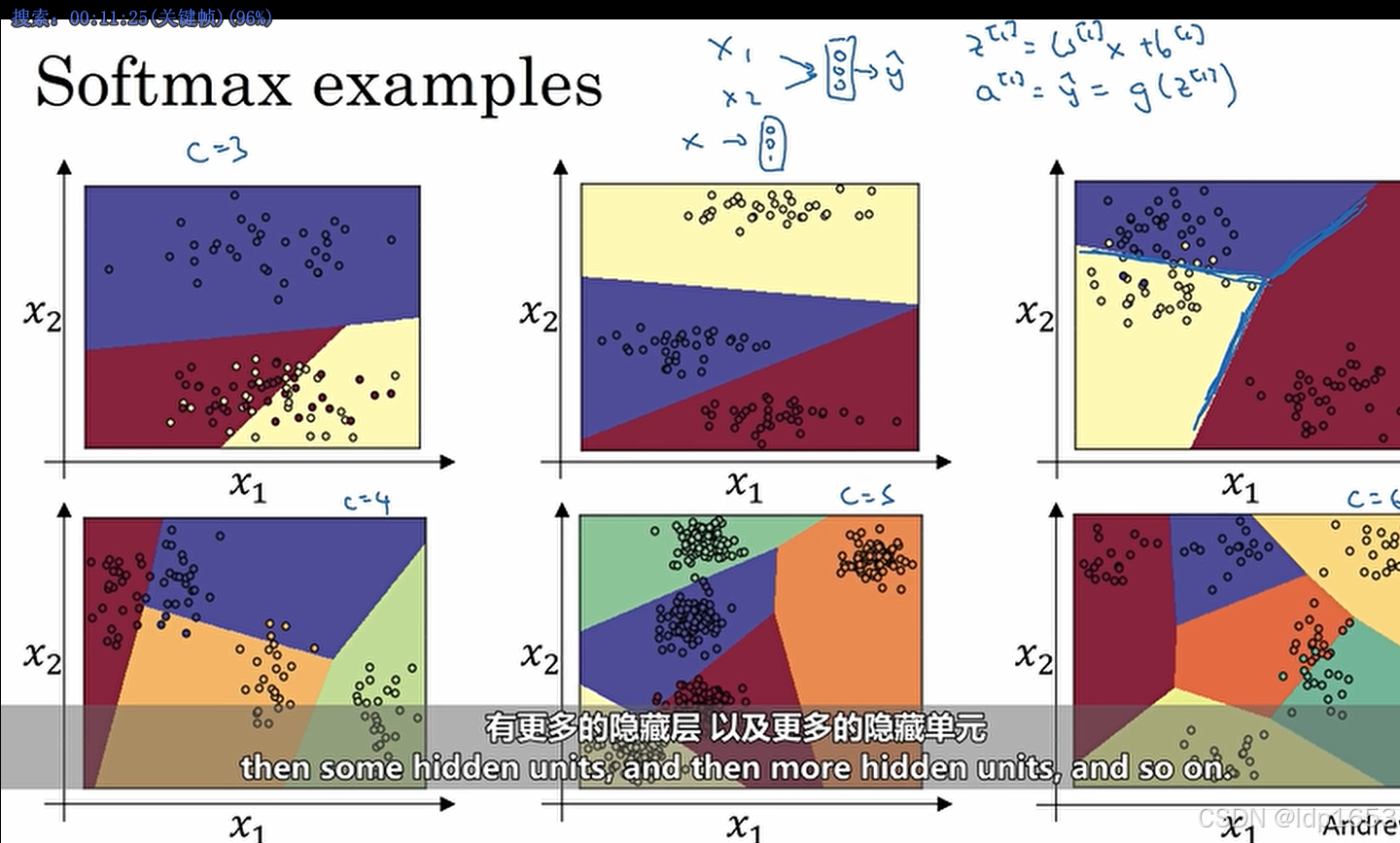
后续用到在回来补


















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









