






1. Focus层原理
Focus层原理和PassThrough层很类似。它采用切片操作把高分辨率的图片 (特征图)拆分成多个低分辨率的图片/特征图,即隔列采样+拼接。原理图如 下:
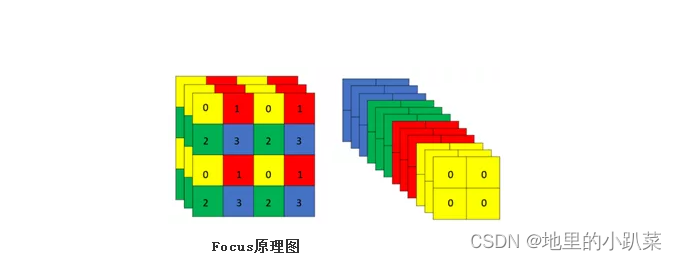
原始的640 × 640 × 3的图像输入Focus结构,采用切片(slice)操作,先 变成320 × 320 × 12的特征图,拼接(Concat)后,再经过一次卷积(CBL(后 期改为SiLU,即为CBS))操作,最终变成320 × 320 × 64的特征图。
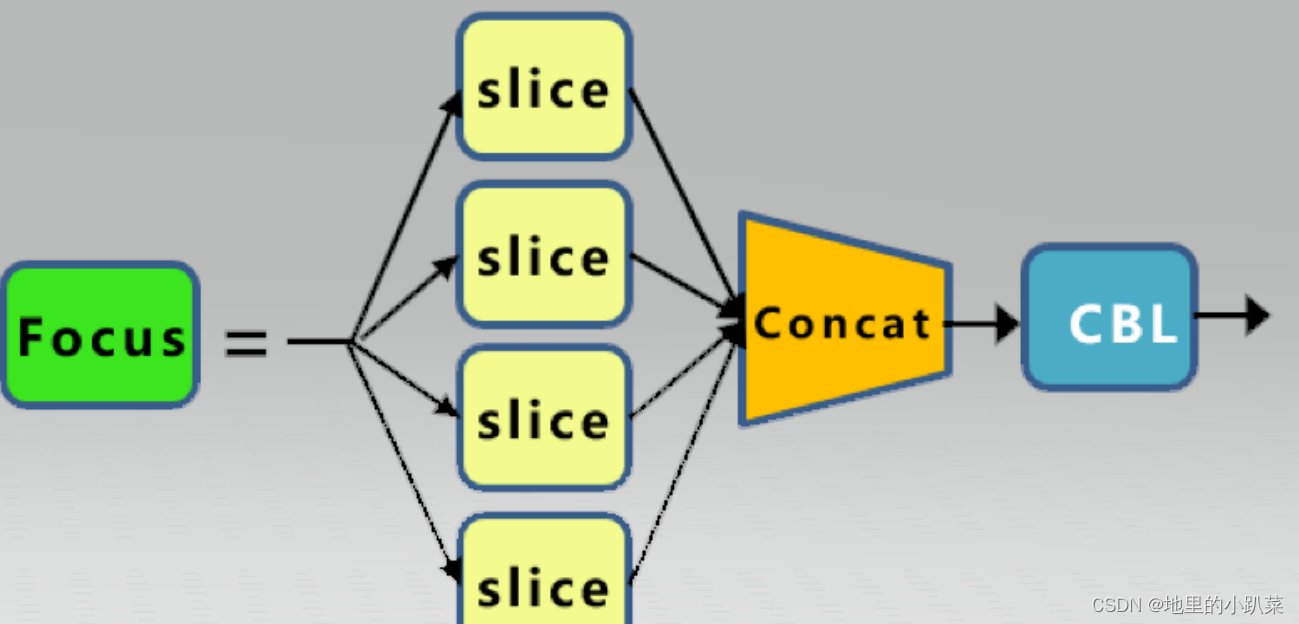
Focus层将w-h平面上的信息转换到通道维度,再通过3*3卷积的方式提取 不同特征。采用这种方式可以减少下采样带来的信息损失 。
2.代码分析
Focus层及其相关代码如下(models/common.py)
YOLOv5源码:https://github.com/ultralytics/yolov5
def autopad(k, p=None): # kernel, padding自动填充的设计,更加灵
活多变
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x
in k]
# auto-pad自动填充,通过自动设置填充数p
#如果k是整数,p为k与2整除后向下取整;如果k是列表等,p对应的是
列表中每个元素整除2。
return p
class Conv(nn.Module):
# 这里对应结构图部分的CBL,CBL = conv+BN+Leaky ReLU
def __init__(self, c1, c2, k=1, s=1, p=None, g=1,
act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p),
groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
#将其变为均值为0,方差为1的正态分布,通道数为c2先采取切片操作(x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]
)把图片分成1,2,3,4共4块(如上面的原理图)
然后进行一个连接
然后再来一次卷积,这里的卷积是自定义卷积:先进行一次卷积,然后变
化成正态分布,最后来个SiLU激活,完成。
第四节: YOLOv5中 backbone讲解
3, Focus的作用
参数数量(params):关系到模型大小,单位通常是M,通常参数用
float32表示,所以模型大小是参数数量的4倍。
self.act = nn.SiLU() if act is True else (act if
isinstance(act, nn.Module) else nn.Identity())
#其中nn.Identity()是网络中的占位符,并没有实际操作,在增减网络过程
中,可以使得整个网络层数据不变,便于迁移权重数据;nn.SiLU()一种激活函
数(S形加权线性单元)。
def forward(self, x):#正态分布型的前向传播
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):#普通前向传播
return self.act(self.conv(x))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1,
act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[...,
1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
#图片被分为4块。x[..., ::2, ::2]指图片的左上角那一块,
x[..., 1::2, ::2]指右上角那一块,x[..., ::2, 1::2]指左下角那一块,
x[..., 1::2, 1::2]指右下角那一块。都是每隔一个采样(采奇数列)。用
cat连接这些采样图,生成通道数为12的特征图
# return self.conv(self.contract(x))先采取切片操作(x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2] )把图片分成1,2,3,4共4块(如上面的原理图) 然后进行一个连接 然后再来一次卷积,这里的卷积是自定义卷积:先进行一次卷积,然后变 化成正态分布,最后来个SiLU激活,完成。
3, Focus的作用
参数数量(params):关系到模型大小,单位通常是M,通常参数用 float32表示,所以模型大小是参数数量的4倍。
计算量(FLOPs):即浮点运算数,可以用来衡量算法/模型的复杂度,这 关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘 加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU 等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和 shoutcut残差加等,目前技术有BN和CNN可以不加bias。
params计算公式: Kh × Kw × Cin × Cout FLOPs
计算公式:
Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map) = params × H × W
总所周知,图片在经过Focus模块后,最直观的是起到了下采样的作用,但 是和常用的卷积下采样有些不一样,可以对Focus的计算量和普通卷积的下采样 计算量进行做个对比:
在yolov5s的网络结构中,可以看到,Focus模块的卷积核是3 × 3,输出通 道是32:
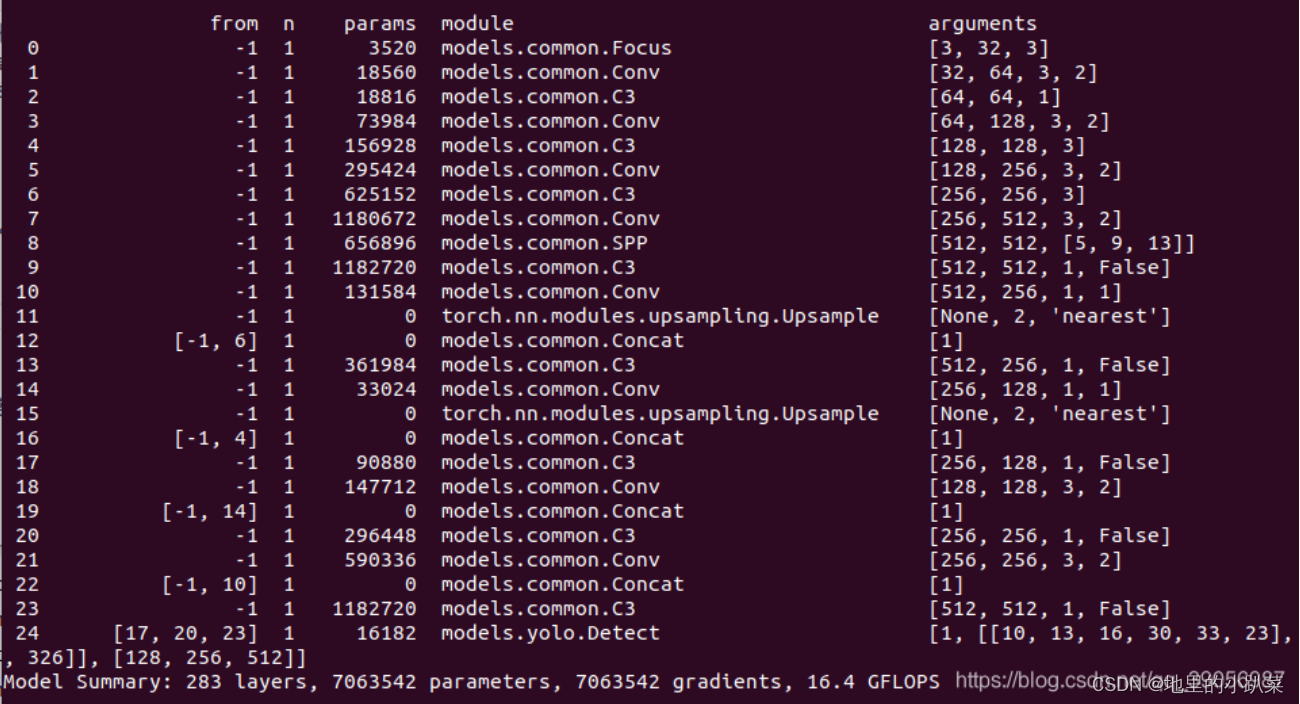
那么做个对比:
普通下采样:即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为 2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样 理论的计算量为:
FLOPs(conv) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600(不考虑bias情 况下)
params参数量(conv) = 3 × 3 × 3 × 32 +32 +32 = 928 (后面两个32分别为 bias和BN层参数)
Focus:将640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成 320 × 320 × 12的特征图,再经过3 × 3的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,那么Focus理论的计算量为:
FLOPs(Focus) = 3 × 3 × 12 × 32 × 320 × 320 = 353894400(不考虑 bias情况下) params参数量(Focus)= 3 × 3 × 12 × 32 +32 +32 =3520 (为了呼应上图输 出的参数量,将后面两个32分别为bias和BN层的参数考虑进去,通常这两个占 比比较小可以忽略) 可以明显的看到,Focus的计算量和参数量要比普通卷积要多一些,是普通卷积 的4倍,但是下采样时没有信息的丢失。
2021-07-01更新:作者有在issues中提到Focus是为了提速,和mAP无 关,但是也没有说是什么原理,我也是一知半解,本文也仅从计算量和参数量 去分析该模块,如果有看懂作者这样作法的同学望评论区告知。
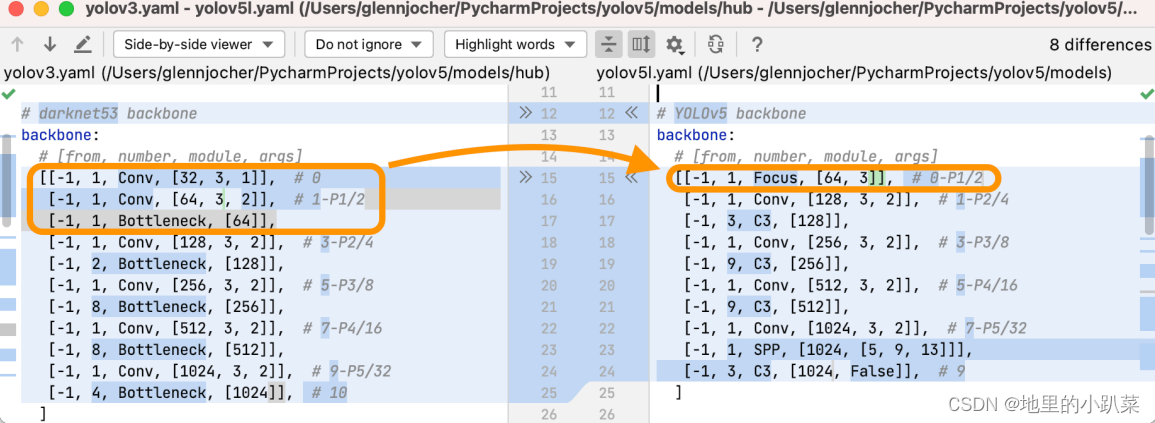
2021-08-16更新:作者终于在issues上做了具体的解答,和之前分析的思 路一样,都是从计算量和参数量出发,不同的是,在作者解答之前我们并不知 道作者改进的出发点是什么,也就是不清楚他在何结构上进行的改进,文中我 理解为只是对一层普通下采样卷积做的改进,实际上有三层,所以经过改进后 参数量其实还是变少了的,也确实达到了提速的效果,具体内容可以结合本文 分析过程和作者给的issues结合起来看。

















 4552
4552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









