 RAGFlow搭建大模型知识库指南
RAGFlow搭建大模型知识库指南




RAGFlow是融合数据检索与生成式模型的新型系统架构。本文详细介绍了其环境准备、系统搭建、模型配置和知识库创建的全过程,并通过实例展示了效果。文章指出文件解析、Embedding和LLM是提升RAG准确率的三大关键点,为开发者提供了实用的RAG知识库搭建指南。
一、RAGFlow概述
1、RAGFlow的定义
RAGFlow是一种融合了数据检索与生成式模型的新型系统架构,其核心思想在于将大规模检索系统与先进的生成式模型(如Transformer、GPT系列)相结合,从而在回答查询时既能利用海量数据的知识库,又能生成符合上下文语义的自然语言回复。该系统主要包含两个关键模块:数据检索模块和生成模块。数据检索模块负责在海量数据中快速定位相关信息,而生成模块则基于检索结果生成高质量的回答或文本内容。
在实际应用中,RAGFlow能够在客户服务、问答系统、智能搜索、内容推荐等领域发挥重要作用,通过检索与生成的双重保障,显著提升系统的响应速度和准确性。
2、特点
- 高效整合海量数据:借助先进的检索算法,系统能够在大数据中迅速找到相关信息,并将之用于生成回答。
- 增强生成质量:通过引入外部数据,生成模块能够克服模型记忆限制,提供更为丰富和准确的信息。
- 应用场景广泛:包括但不限于在线问答系统、智能客服、知识库问答、个性化推荐等。
3、RAGFlow应用场景
在在线客服系统中,RAGFlow能够利用用户的历史咨询记录、产品文档以及FAQ等数据,实时检索出最相关的信息,并通过生成模块整合成自然、连贯的回复,从而大幅提升客户满意度。
4、RAGFlow系统架构
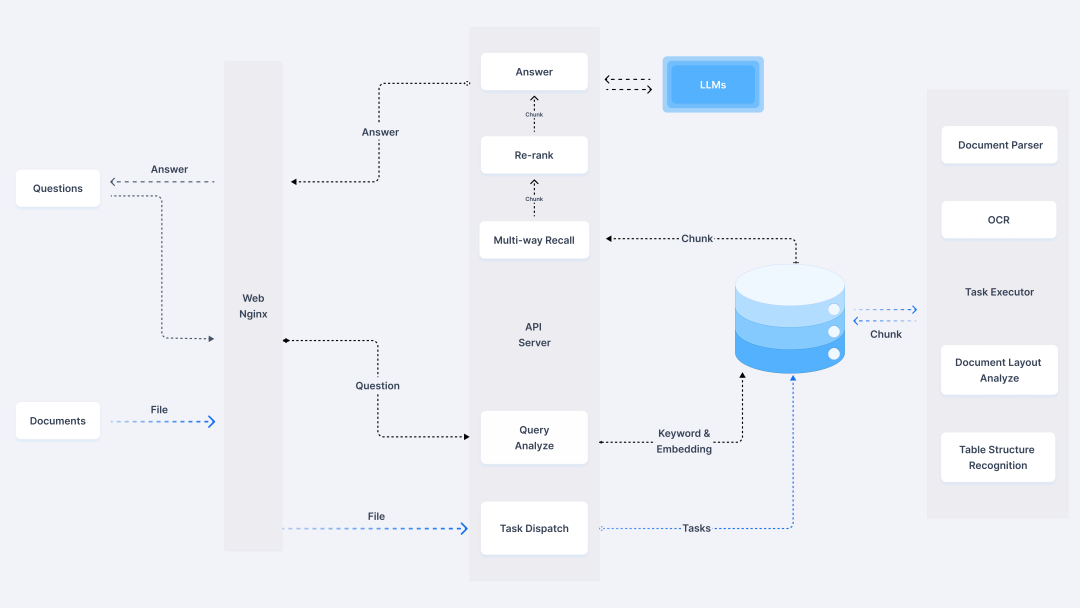
二、环境准备与系统搭建
1、环境需求
在搭建RAGFlow系统前,需要确保开发与运行环境满足以下要求:
- 硬件配置:建议采用多核CPU、充足内存(16GB及以上)以及支持高并发访问的存储设备;如需部署大规模检索服务,可考虑使用分布式存储集群。
- 操作系统:推荐使用Linux发行版(如CentOS、Ubuntu)以便于Shell脚本自动化管理;同时也支持Windows环境,但在部署自动化脚本时可能需要适当调整。
- 开发语言与工具:主要使用Java进行系统核心模块开发,同时结合Shell脚本实现自动化运维。
- 依赖环境:需要安装Java 8及以上版本,同时配置Maven或Gradle进行依赖管理;对于数据检索部分,可采用ElasticSearch、Apache Solr等开源检索引擎;生成模块则依赖于预训练模型,可以借助TensorFlow或PyTorch进行实现。
2、服务器配置
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
3、安装
修改 max_map_count
确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
$ sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置:
# 这里我们设为 262144:
$ sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
下载仓库代码
git clone https://github.com/infiniflow/ragflow.git
Docker拉取镜像
修改镜像为国内镜像并且选择embedding版本
修改文件docker/.env/
默认配置为:RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim
修改为国内镜像:RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.16.0
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|---|---|---|---|
| v0.16.0 | ≈9 | ✔️ | Stable release |
| v0.16.0-slim | ≈2 | ❌ | Stable release |
| nightly | ≈9 | ✔️ | Unstable nightly build |
| nightly-slim | ≈2 | ❌ | Unstable nightly build |
运行命令拉取镜像
docker compose -f docker/docker-compose.yml up -d
 查看日志
查看日志
docker logs -f ragflow-server
提示下面提示说明启动成功
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
访问IP,进入 RAGFlow,注意不是 9380 端口,Web是http://127.0.01默认为 80 端口
三、应用
1、注册账号
注册完直接登录
2、添加模型
本文用到的模型类型:Chat 和 Embedding。 Rerank 模型等后续在详细介绍。
点击右上角->模型提供商->添加模型
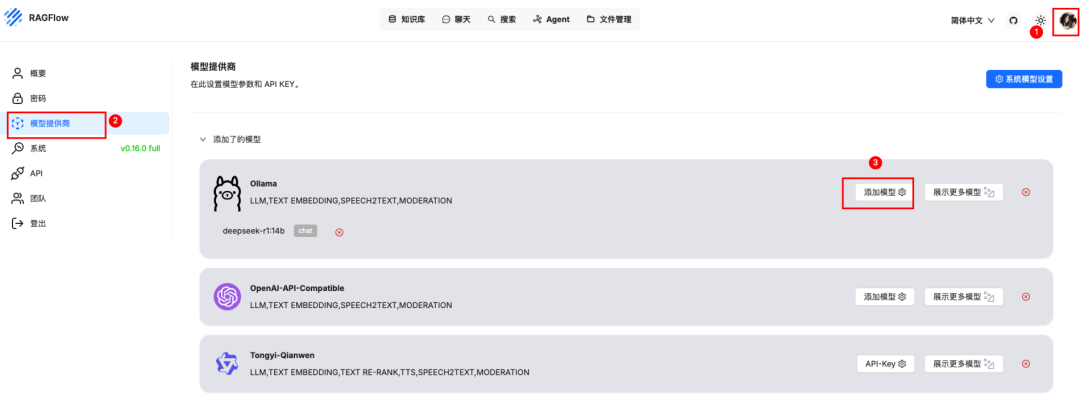
填写模型信息,模型类型选 chat
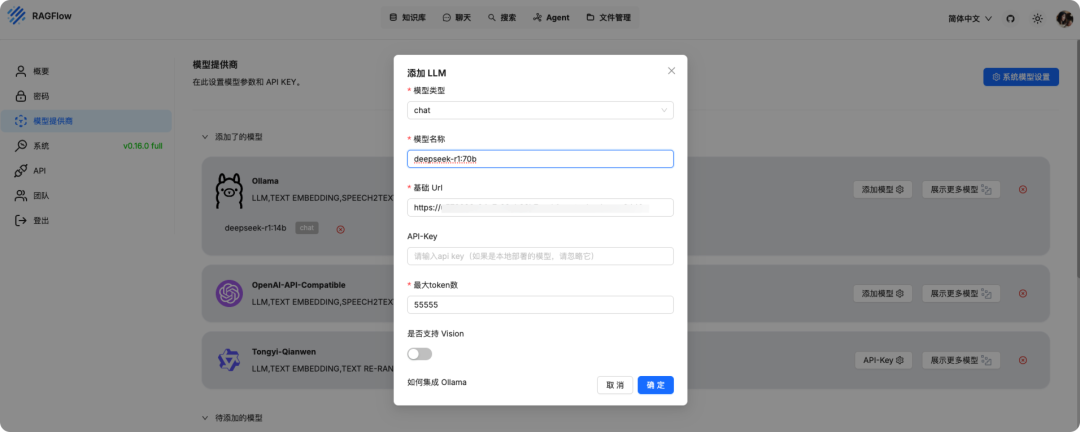
再添加一个 Embedding 模型用于知识库的向量转换(RAGFlow 默认也有 Embedding)
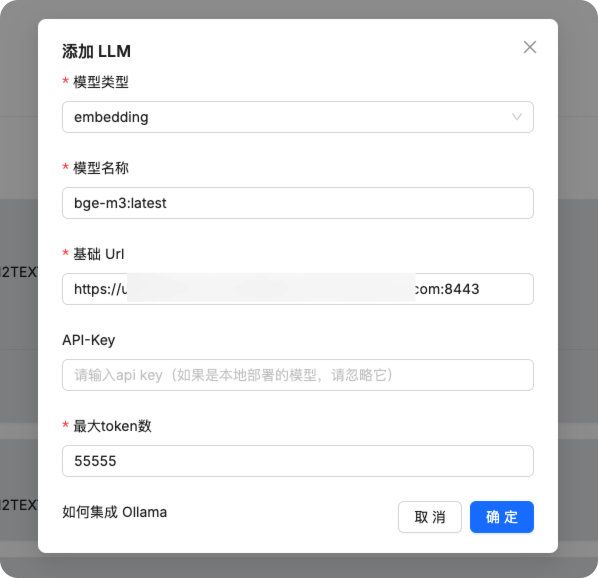
在系统模型设置中配置聊天模型和嵌入模型为我们刚刚添加的模型
3、创建知识库

填写相关配置
- 文档语言:中文
- 嵌入模型:选择我们自己运行的
bge-m3:latest,也可以用默认的。具体效果大家自行评估
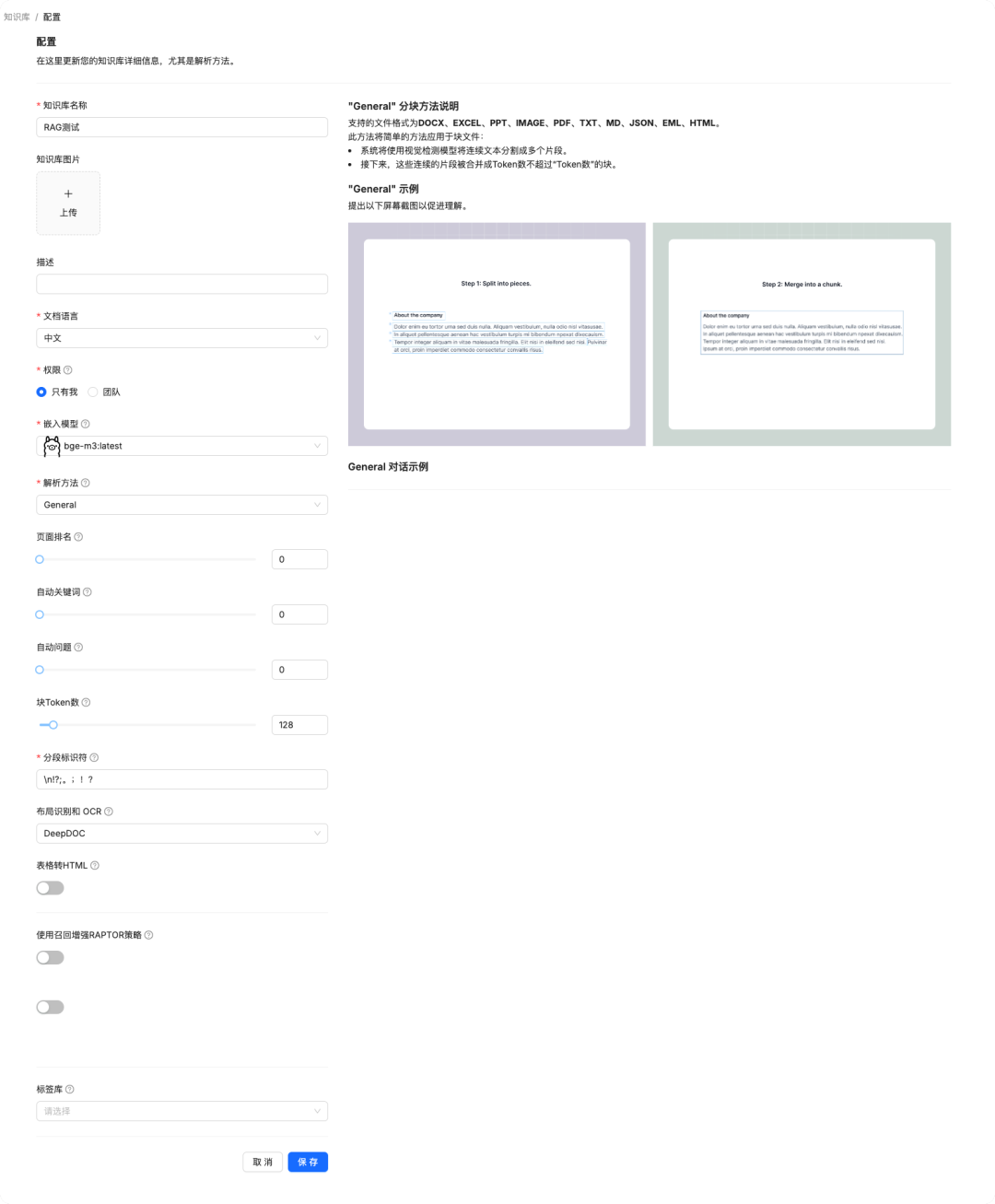
上传文件
这里我自己造了一个测试文档来验证知识库,内容是编的,介绍一个 ABCD 工具,文档在文末提供下载。
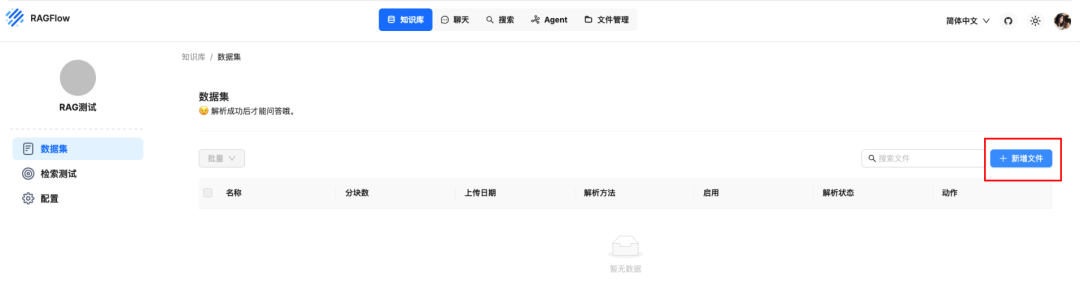
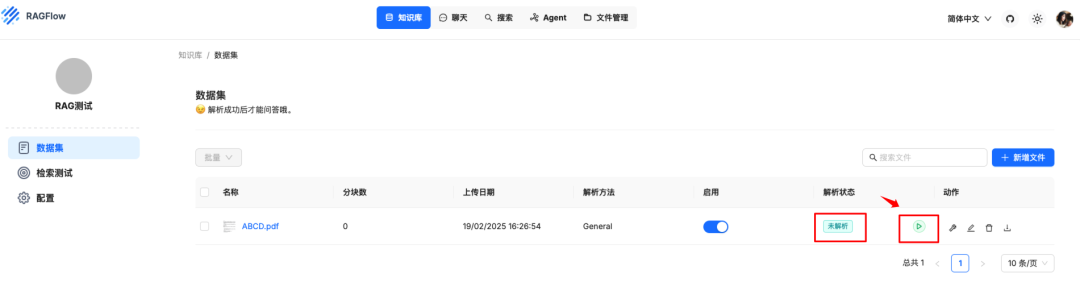
文件上传后是未解析状态,需要解析才可以使用,点击解析
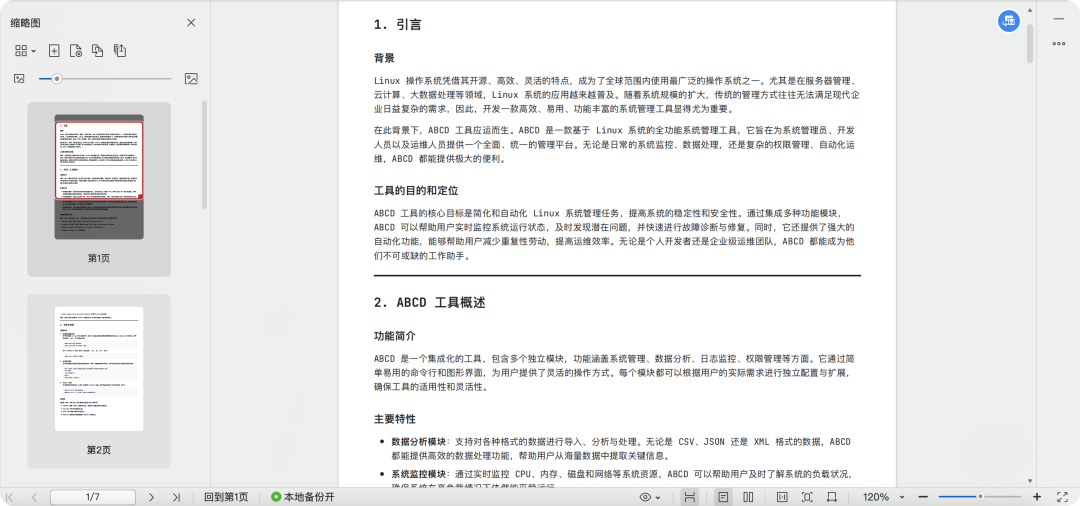
解析成功后点击文件可以看到解析效果
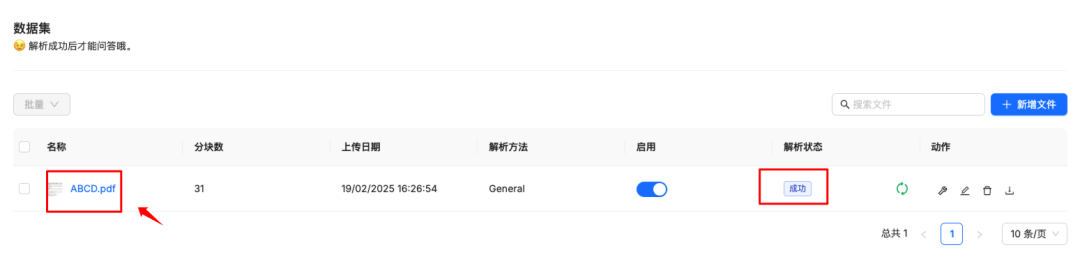
效果

4、创建聊天
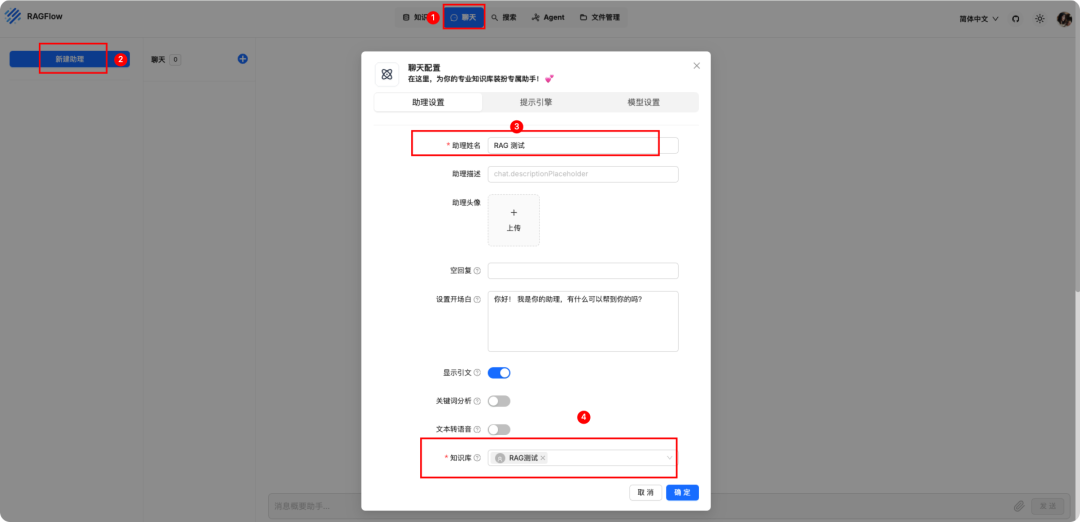
设置模型。token 调整大一些
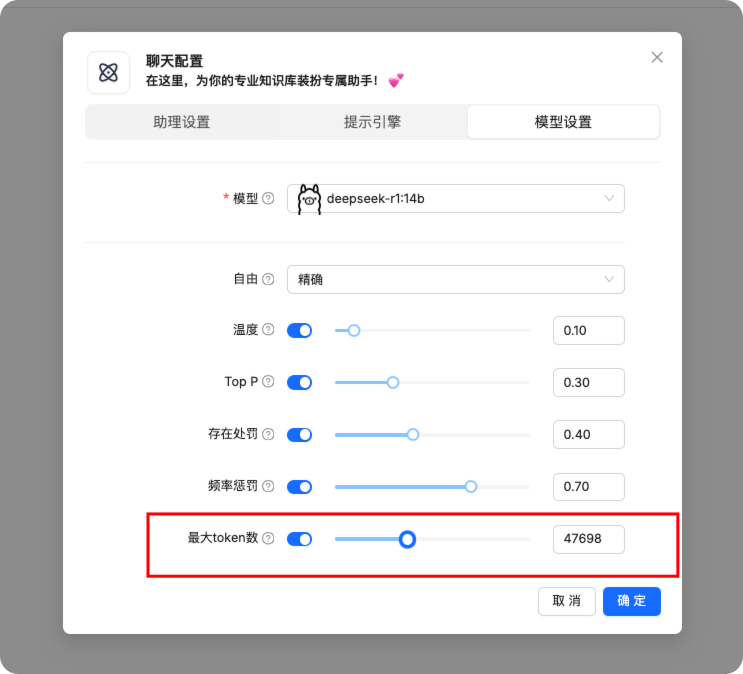
5、验证效果
问题一:直接发送 ABCD
知识库回答
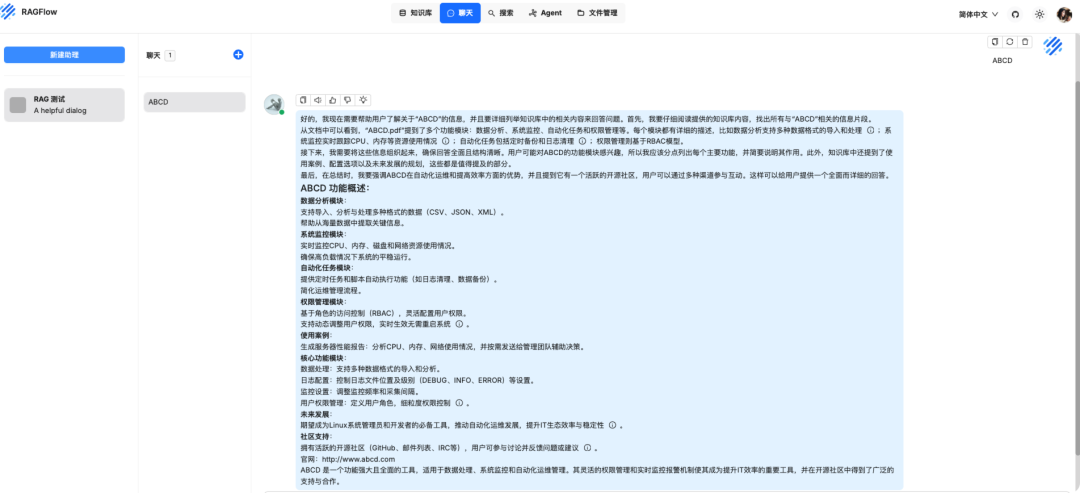
原文档

问题二:ABCD 错误代码有哪些
知识库回答
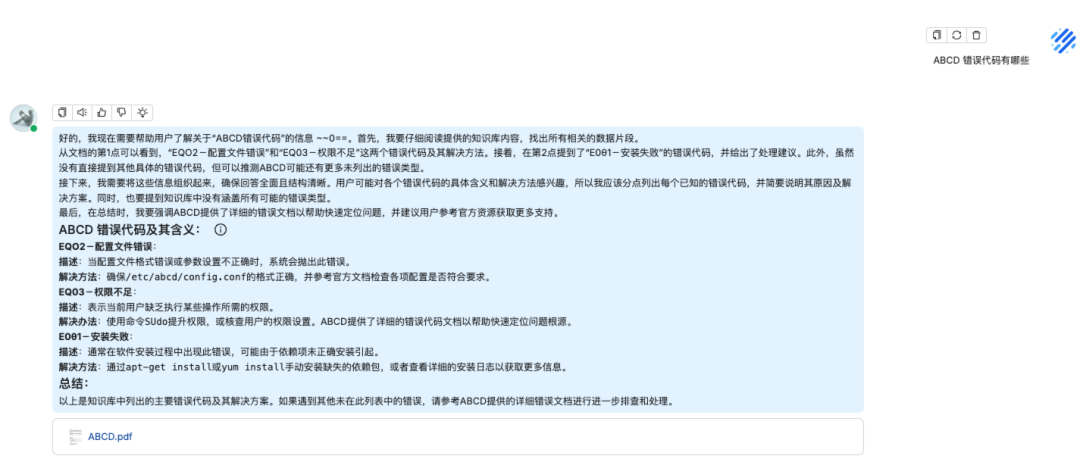
原文档

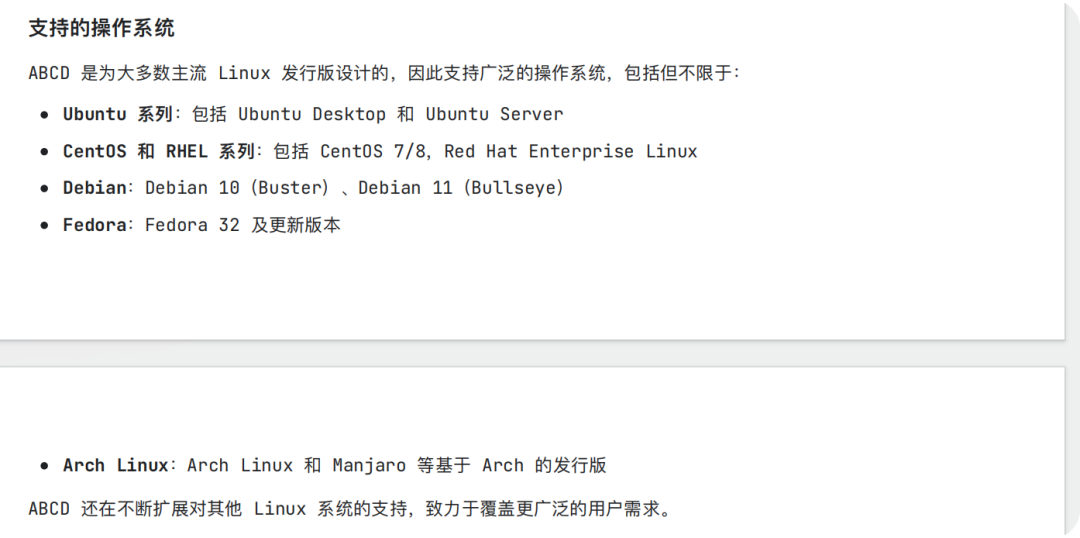
问题三:ABCD 支持哪些系统
知识库回答

原文档
问题四:ABCD 官网
知识库回答
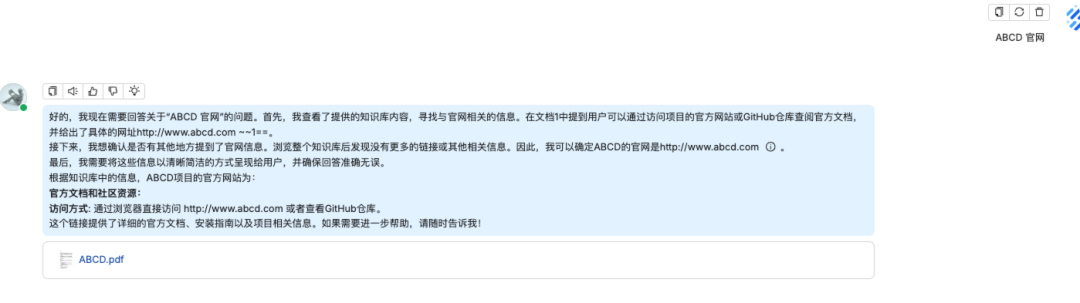
你也可以在回答的结果看到他引用的知识库
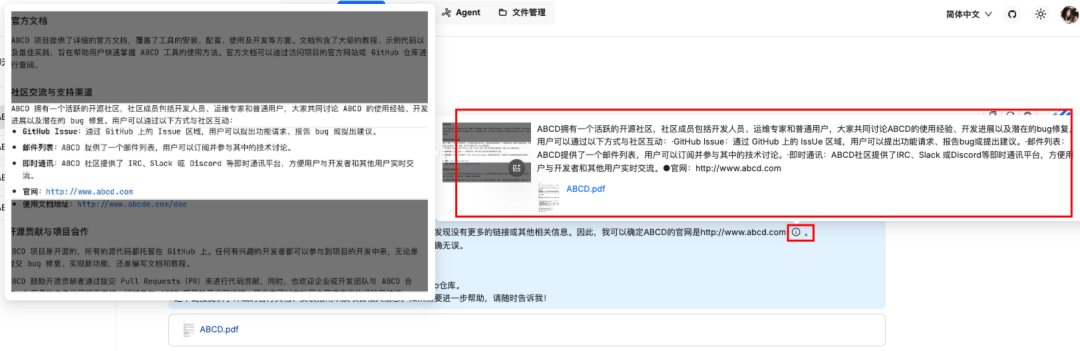
原文档

总结
本文介绍了 RAGFlow 的基础使用方法,从演示效果来看尚可。然而,在实际应用场景中,各类文件格式与结构各不相同,文件解析成为一大难题。一旦解析不准确,即便使用性能强劲的 Deepseek-R1 大模型(经亲测),也会出现分析错误的情况。因此,在 RAG 过程中,文件解析、Embedding 以及 LLM 是提升准确率的三大关键攻克点。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
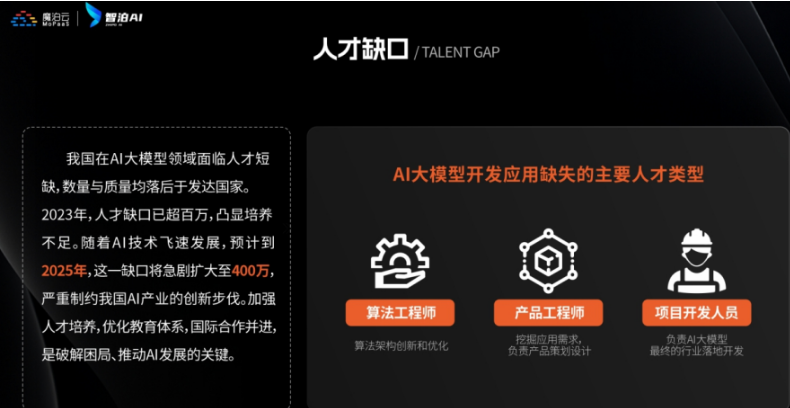
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









