




引言
在人工智能的浪潮中,大型语言模型(LLMs)不断推动着技术边界的扩展。Meta 最新推出的 Llama 3.1 模型系列,以其卓越的性能和广泛的应用前景,引起了业界的广泛关注。现在,激动人心的消息来了——Llama3.1 已经在 Amazon Bedrock 上线,让开发者和研究人员能够即刻体验这一革命性技术。本文将带您一探究竟,了解如何在 Amazon Bedrock 上体验 Llama3.1 的强大功能。

Llama 3.1:LLM新高度
Llama 3是一个语言模型系列,原生支持多语言性、编码、推理和工具使用,在理解力、生成力和多语言处理能力上实现了质的飞跃。最大的模型是一个密集型的Transformer架构,拥有4050亿个参数,能够处理高达128K tokens的上下文窗口。Meta公开发布了Llama 3,包括405B参数语言模型的预训练和后训练版本,以及用于输入和输出安全的Llama Guard 3模型。这一模型系列包括不同规模的版本,从 8B(80 亿参数)到 405B(4000 亿参数),为不同需求的用户提供灵活的选择。
主要特点
- 多语言支持:Llama 3.1 原生支持多语言,能够理解和生成多种语言的文本,极大地扩展了其应用范围。
- 上下文理解:通过高达 128k 的上下文窗口,Llama 3.1 能够处理更长、更复杂的文本序列,提供更深入的内容理解。
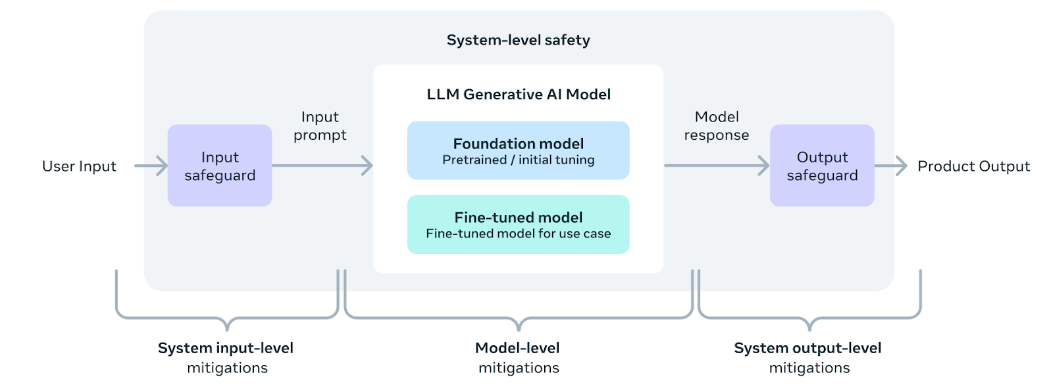
- 简洁架构:选择 Transformer 架构而非 MoE(混合专家模型),Llama 3.1 在保持高性能的同时,简化了模型的复杂性,便于部署和维护。
模型架构
Llama 3使用标准的密集Transformer架构,进行了一些小的修改,如分组查询注意力(GQA)和8个键值头,以及注意力掩码。模型使用了一个包含128K个标记的词汇表,并增加了RoPE基础频率超参数到500,000。
Llama 3的成功归功于三大核心要素:
- 高质量数据:15T tokens的高质量多语言数据。
- 规模性:通过大模型提升小模型的质量,实现同类最佳效果。
- 简洁性:选择Transformer架构,采用简单的后训练程序。
开发历程
Llama 3的开发分为两个主要阶段:
- 预训练:预训练包括大规模训练语料的整理和筛选、模型结构的开发、规模定律实验、基础设施、扩展性和效率的开发,以及预训
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











