 RAG技术实践
RAG技术实践




想起之前听过高原老师的一场分享,结合最近项目的实践,对RAG落地的一些经验进行梳理,希望能对各位读者有些帮助。
什么是 RAG
- RAG 是 Retrival Augment Generation 的缩写,直译过来就是【检索增强生成】
- 将大模型比喻成一个高中生,学会了基础学科的知识,有基础的逻辑和理解能力,RAG 就是给这个大学生一个搜索引擎
- 没有搜索引擎之前,问一个高中生什么是数据库死锁,他无法回答,但是有了搜索引擎,通过搜索相关的知识,这个高中生就能回答这个问题
- 大模型配合 RAG 的时候通常使用 Embedding 技术来进行文本内容之间的相似度匹配
- Embedding 技术是通过算法将文本转换成数字向量,然后通过转换后的数字向量之间的距离来判断文本之间的相似程度,进而通过这样的方式来搜索找到相关的文本内容
需求描述
- 希望搭建一个专家级营养师的IP形象,对外提供自动化的咨询问答服务
- 建立AI知识库,训练AI智能对话的某类型知识来源范围需限制在知识库内
- 设定某些对话(如激烈的情绪反应、产品活动价格等咨询)自动转人工客服
- 遇到无法回答的问题自动转人工客服
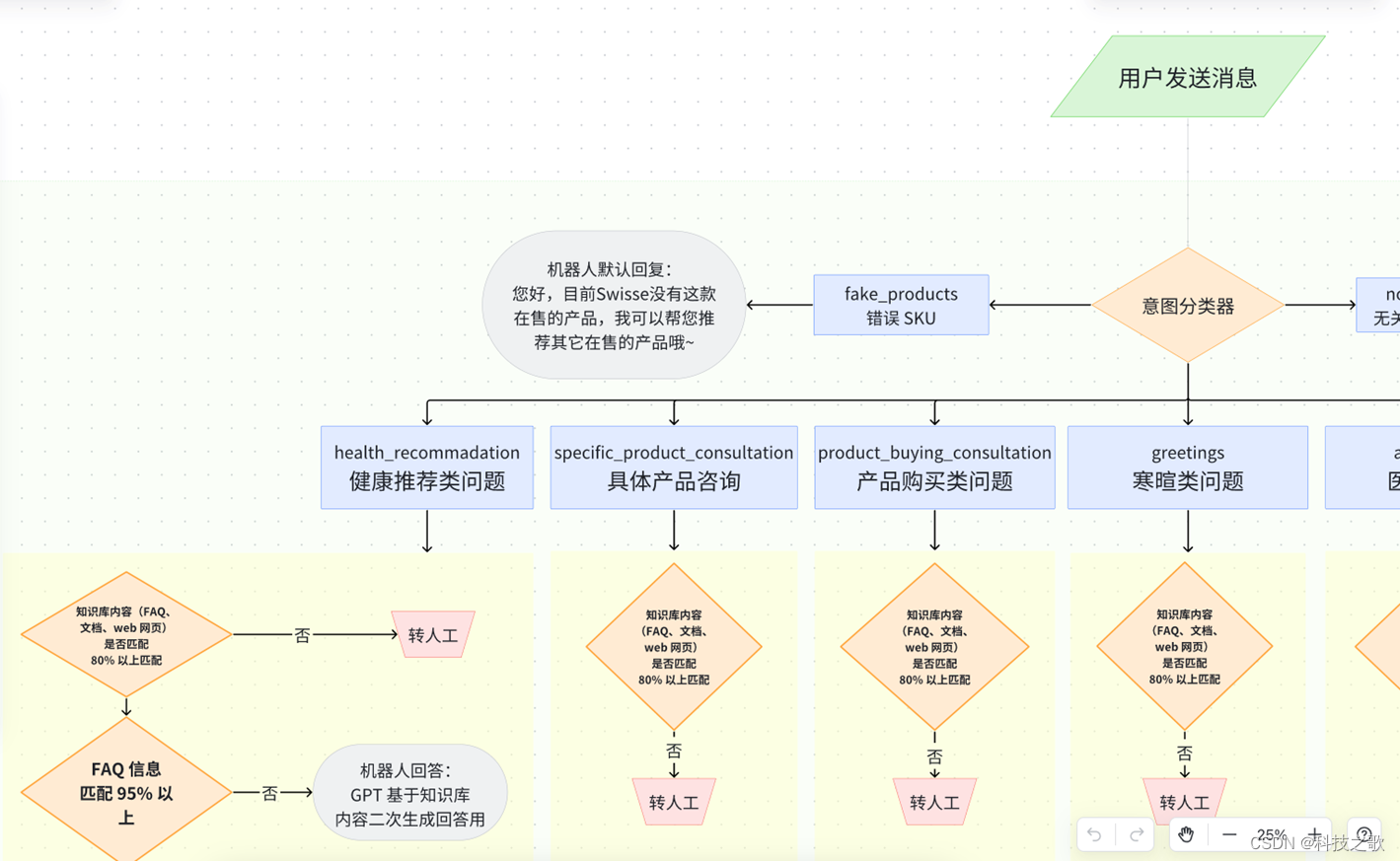
结合用户需求,初步考虑的设计方案是通过一个意图分类器,把产品类别区分开来,然后再进行相关的RAG检索。
坑类回顾
踩坑一:表格数据如何RAG
•用户希望能够基于产品信息进行回复和推荐
•但产品信息是一个 SKU 表格
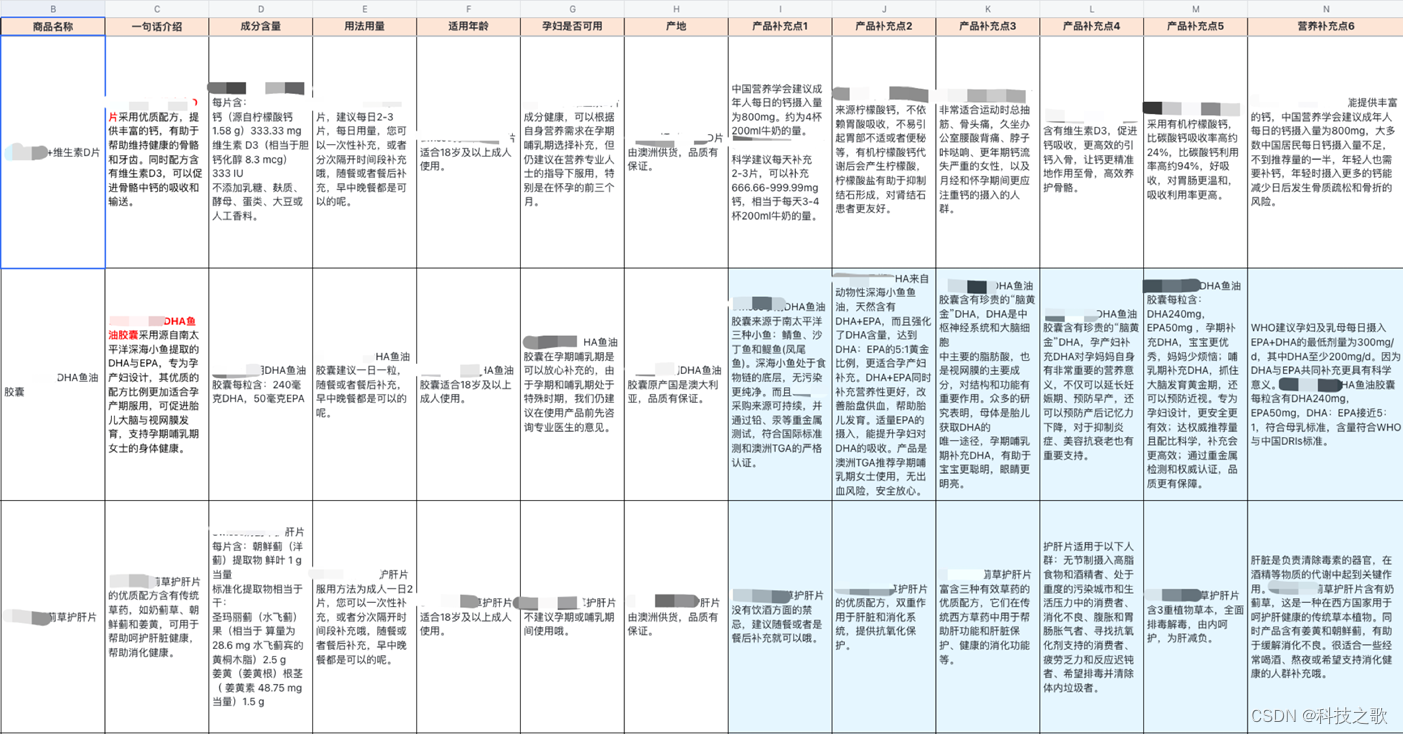
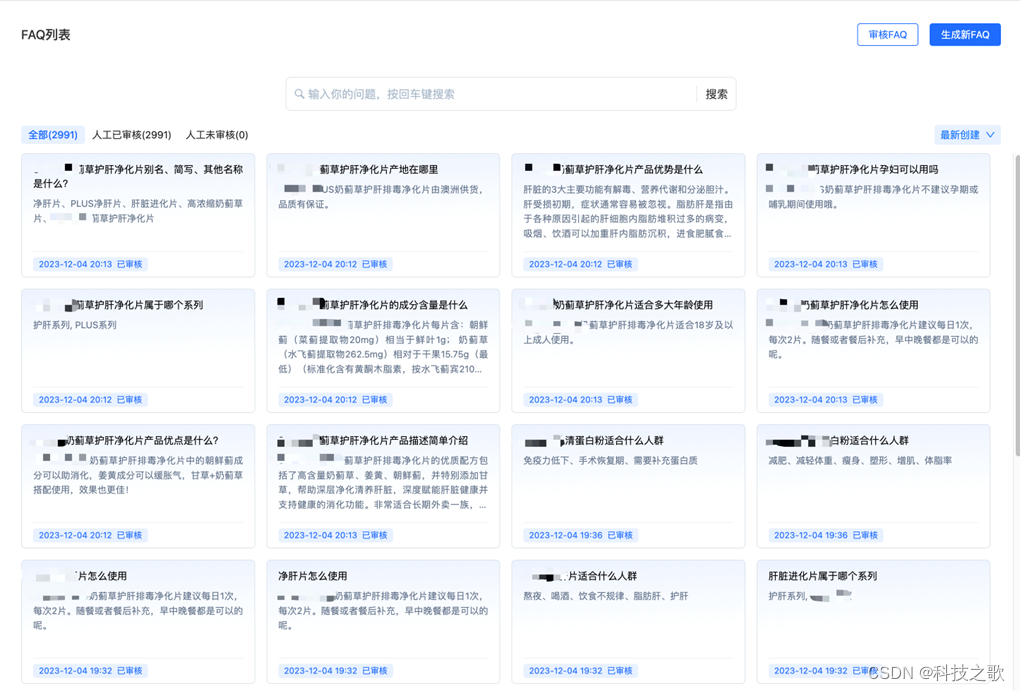
解决方法:
根据行和列组合成FAQ,将表格内容转换成问答数据,以FAQ的形式检索和存储。通过文本相似度可以匹配相关内容,问题相似度高则直接回答
踩坑二:问答效果始终不满意
问题描述:
- 无法投产,不敢用
- 推荐的不准,老转人工
- AI推荐速度比较慢
- 智能推荐每次都要点击
- 智能推荐每次都要修改
解决方法:
1.确定可衡量的交付标准,有签字画押,避免持续需求变更,举例来说
- 客户组织一个业务测试团队(若干人),每次交付一个版本之后,进行批量测试,并对测试结果进行主观打分(10分满分)
- 针对所有测试人员的测试结果,对分数取平均值,当超过8分的时候,即为达到验收标准
2.调低用户预期,每一轮的验收内部先多轮测试验证,确认超过了上一轮的预期再给到客户
踩坑三:Embedding相似度不准
问题描述:
•embedding是一种基于文本字符的向量算法,无法理解语意•匹配出来的结果,有时候预期中最希望命中的,往往不是相似度最高的那个•LLM 生成的时候,都有token上限•为了不超过上限,需要对匹配结果按照相似度选前 k 个匹配结果•最终希望命中的那一个,没有成功进入到 LLM prompt 里•真实相关的知识并没有被以最高相似度而匹配出来•token长度限制,没有排在前面的知识就没有被选中并放入到prompt里面
解决方法:
- 首先想到的是增加相似问、更换embedding算法
- 其次是改写用户输入query,使用完整的问题再进行相关问题查询
- 进一步拆分意图分类,增加被搜索知识整体集合与问题匹配度
- 更有效地方式是如何把相关知识内容放到prompt中
-
调整 token 分配比例!聊天历史也没那么重要,不需要太长大力出奇迹!换更长上下文的模型!4K不够16K,反正现在LLM都挺能装
踩坑四:自行编造产品问题
问题描述:
•大模型存在幻觉,无法避免
•永远顺着问题去回答,问着问着,就逐渐离谱
解决方法:
让大模型自己检查结果(即幻觉*幻觉,概率变得趋向于0),抽取其中产品名称,再去和配置的白名单对比,不在名单里则拦截回复内容,在名单里则放行
踩坑五:多次回复稳定性不好
问题描述:
•大模型分类当前会话类型
•大模型根据上下文重写问题
•大模型生成回答
•大模型从回答中抽取提及的产品名
解决方法:
•确保每一步的大模型调用都能得到预期结果,串联起来确保多次串联调用大模型,都能得到稳定结果•大力出奇迹,日久见人心,重复多次测试,根据结果迭代调整,再反复多次测试,最终得到结果,这里没有捷径•如果捷径一定说要有,那就是提前准备好测试工具


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











