







 本文介绍了多分类问题的三种常见拆分策略:一对一(OvO)、一对其余(OvR)和多对多(MvM),特别是详细阐述了ECOC(纠错输出码)的工作原理,包括编码、解码过程,并通过海明距离和欧式距离来确定最终分类结果。对比分析表明,不同策略在训练时间、存储开销和纠错能力上有各自优势。
本文介绍了多分类问题的三种常见拆分策略:一对一(OvO)、一对其余(OvR)和多对多(MvM),特别是详细阐述了ECOC(纠错输出码)的工作原理,包括编码、解码过程,并通过海明距离和欧式距离来确定最终分类结果。对比分析表明,不同策略在训练时间、存储开销和纠错能力上有各自优势。
多分类问题学习器拆分策略
对于 N N N个类别 C 1 , C 2 , … , C N C_1,C_2,\ldots,C_N C1,C2,…,CN,多分类学习的基本思路是拆解法,即将多分类任务拆分成若干个二分类任务求解,拆分策略如下所示:
一对一(One vs. One, OvO)
将 N N N个类别两两配对,产生 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2个二分类任务,每个任务使用一个二分类学习器进行学习;
多个二分类学习器预测得到结果中,最多的类别作为最终的分类结果。
一对其余(One vs. Rest, OvR)
每次将一个类别作为正例,其余其他类别样例均作为反例,产生 N N N个二分类任务;
若有多个二分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别作为分类结果。
多对多(Many vs. Many, MvM)
每次将若干个类作为正类,若干个其他类作为反类,MvM的正反类构造必须有特殊的设计,不能随意选取;
最常用的MvM技术是:纠错输出码(Error Correcting Output Codes, ECOC);
ECOC工作过程主要分为2步:
- 编码:对 N N N个类别做M次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生 M M M个训练集,可以训练出 M M M个分类器;
- 解码: M M M个分类器分别对测试样本进行预测,这些预测结果标记组成一个编码;将这些预测结果编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果;
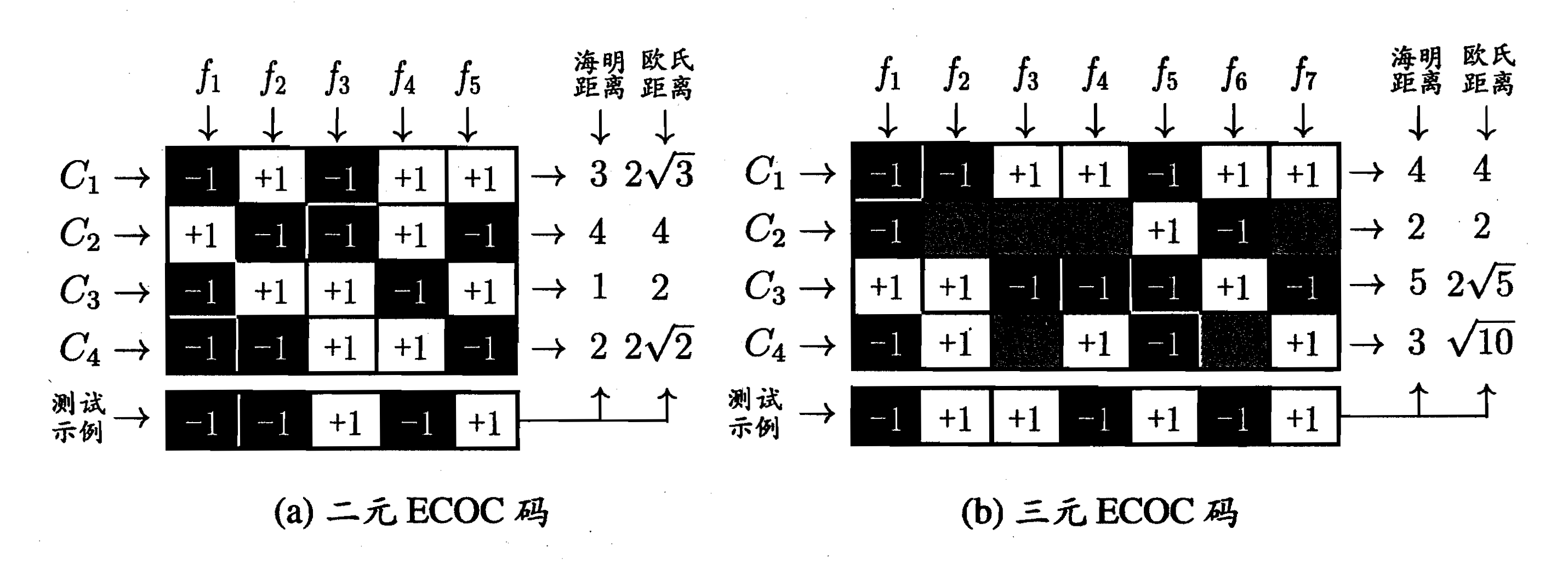
上图是ECOC编码示意图,其中, C i C_i Ci表示第 i i i个类别, f i f_i fi表示第 i i i个学习器,“+1”和“-1”分别表示学习器 f i f_i fi将该类样本作为正、反例,“0”(三元码中, C 2 C_2 C2行 f 2 , f 3 , f 4 , f 7 f_2,f_3,f_4,f_7 f2,f3,f4,f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









