






前言
具身智能小白从零开始复现OpenVLA,留作记录
环境准备 根据自己的实际情况选择,但是不能低于官方推荐的配置,我用的配置是:
显存: 15.7GB(3090)
操作系统:ubuntu22.04
Cuda版本:12.4
Python版本:3.11
Pytorch:2.7
注意事项:建议不用使用service版的服务器,因为可能出现图形化服务初始化错误的情况,到时候进行仿真实验的时候会出现超多问题
安装OpenVLA环境
我就直接在base里面安装了,如果有需要创建虚拟环境可以看下面:
直接安装版:
git clone https://github.com/openvla/openvla.git
cd openvla
pip install -e .这一步要下载的东西很多会耗时很久,一定要使用科学上网工具
pip install packaging ninja
ninja --version; echo $?
pip install "flash-attn==2.5.5" --no-build-isolation
#no-build-isolation⾮常关键,它让flash-attn
构建时可以识别到当前环境已安装的torch。如果没有这个参数会出现找不到torch包的错误创建虚拟环境版本:
#官方使用的是cuda12.1,python3.10
conda create -n openvla python=3.10 -y
conda activate openvla
conda install pytorch torchvision torchaudio pytorch-cuda= 12.1 -c pytorch -c nvidia -y
cd /home/gpu/github
git clone https://github.com/openvla/openvla.git
cd openvla
pip install -e .
pip install packaging ninja
ninja --version; echo $?
pip install "flash-attn==2.5.5" --no-build-isolation以上安装步骤可能会出现以下问题:
1、如果flash-attn安装失败,可以跳过,但是要注释掉后⾯代码中的“attn_implementation="flash_attention_2"”
2. 如果有错误:“fatal:unabletoaccess'https://github.com/openvla/openvla.git/': Failed to connect to github.com port 443after 37 ms:Connectionrefused”,那么应该科学上网
3. 如果有错误:“OSError:CUDA_HOMEenvironmentvariableisnotset.Pleasesetittoyour CUDAinstall root.”。执⾏:
sudoaptinstallnvidia-cuda-toolkit4. 如果有错误“Ifyouareusingpip,youcantry`pipinstall--use-pep517`.”执⾏:“pip install "flash-attn==2.5.5"--no-build-isolation--use-pep517” 5. 如果有错误“error:”,科学上网。
6. 如果有错误:"ModuleNotFoundError:Nomodulenamed'torch'",处理⽅法:flash-attn必须在pytorch之后安装,因为有依赖关系。
下载模型
方案一:从modelscope下载
pip install modelscope
modelscope download--modelzixiaoBios/openvla-7b
#下载后的路径为:~/.cache/modelscope/hub/models/zixiaoBios/openvla-7b
#可以使用mv将模型文件移到home目录方案二:从hugging face上下载(需要科学上网)
方案三:从hf-mirror.com下载
git clone https://hf-mirror.com/openvla/openvla-7b
#如果下载的内容很⼩,只有⼏⼗MB,说明只下载了配置⽂件,但没下载模型如果git下载太慢的话也可以直接在hf-mirror.com找到模型,点击Files and versions用鼠标点击下载所有文件,最后将下载的文件放到一个文件夹里面
模型加载测试
#导入必要的库
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import torch
# 设置模型和图片存放路径
path = '/home/gpu/openvla-7b'
image_path = r'/home/gpu/Pictures/1.jpg'
# 加载预训练模型和处理器
processor = AutoProcessor.from_pretrained(path, trust_remote_code=True)
vla = AutoModelForVision2Seq.from_pretrained(path, attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True).to("cuda:0")
#打开图片并定义一个提示字符串
image = Image.open(image_path)
prompt = "In: What action should the robot take to {<INSTRUCTION>}?\nOut:"
# 处理输入并预测动作
inputs = processor(prompt, image).to("cuda:0", dtype=torch.bfloat16)
action = vla.predict_action(**inputs, unnorm_key="bridge_orig", do_sample=False)
#打印结果
print(action)正常的运⾏结果:
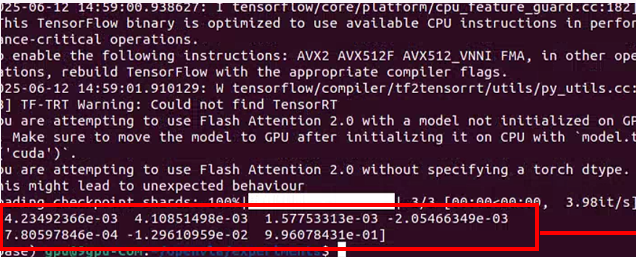
输出的末端控制信号Action是一个1*7的向量
如果上⾯出现显存不⾜的错误,那么通过修改“ torch_dtype=torch.bfloat16,”可以使⽤更少显存。 但是这会使得最终的实验数据和我提供的不同。具体的修改⽅法如下:
Libero实验
安装libero(在哪个环境安装OpenVLA就在哪个环境安装libero)
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
cd LIBERO
pip install -e .
cd openvla
# openvla的代码仓库⽬录
pip install -r experiments/robot/libero/libero_requirements.txtlibero环境下复现 包含4个套件,每个套件10个任务,每个任务50轮推理,推理结束后⾃动开始下⼀个任务的推理。
这里复现的是现libero-spatial套件中的效果
下载libero环境下微调后的模型(可选,可以依然⽤上⾯已经下好的未微调的模型,由于不同仿真平 台下相同模型的效果差异⼤,因此既然作者提供了libero仿真平台下微调过的模型,我这也⽤该微调 过的模型。)
# ⽅式⼀:国内镜像⽹址下
git clone https://hf-mirror.com/openvla/openvla-7b-finetuned-libero-spatial
# ⽅式⼆:科学上网
git clone https://huggingface.co/openvla/openvla-7b-finetuned-libero-spatial
# ⽅式三:
modelscope download --model zixiaoBios/openvla-7b-finetuned-libero-spatial启动:
python experiments/robot/libero/run_libero_eval.py \--model_family openvla \--pretrained_checkpoint /home/gpu/models/openvla-7b-finetuned
libero-spatial \--task_suite_name libero_spatial \--center_crop True
#要正确写入模型存放的地址正常运行结果:
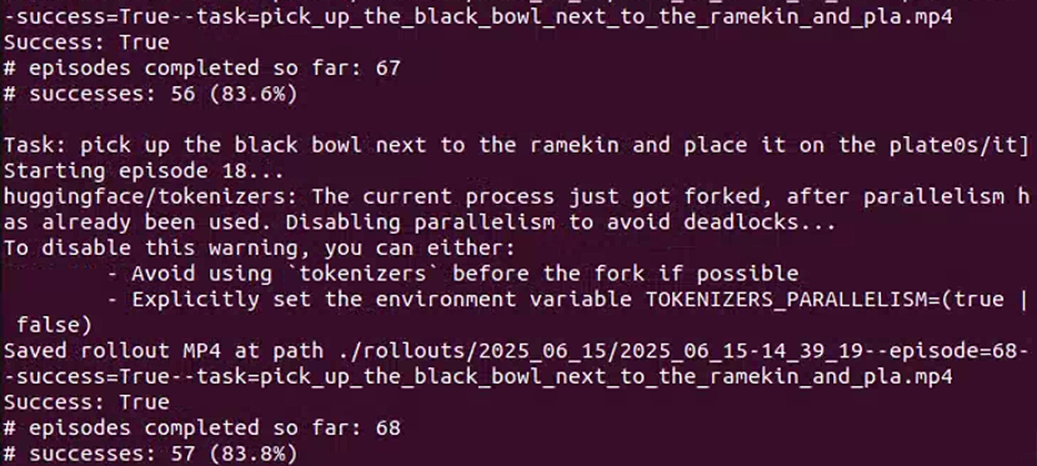
⽣成的实验数据如下(存放在openvla文件夹中的rollouts中):

生成的第一个文件名称:2025_06_15-16_12_45--episode=1--success=True--task=pick_up_the_black_bowl_between_the_plate_and_the_repisode=1,表示第一次推理的结果
success=True,表示成果
task=pick_up_the_black_bowl_between_the_plate_and_the_r,任务名
其他libero实验可以在hugging face上进行下载:
- openvla/openvla-7b-finetuned-libero-object
- openvla/openvla-7b-finetuned-libero-goal
- openvla/openvla-7b-finetuned-libero-10
遇到的错误
1、
Traceback (most recent call last):
File "/miniconda3/lib/python3.11/site-packages/requests/adapters.py", line 589, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "/miniconda3/lib/python3.11/site-packages/urllib3/connectionpool.py", line 843, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "/miniconda3/lib/python3.11/site-packages/urllib3/util/retry.py", line 519, in increment
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /openvla/openvla-7b/resolve/main/processing_prismatic.py (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1006)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/gpu/openvla/experiments/robot/libero/run_libero_eval.py", line 286, in <module>
eval_libero()
File "/home/gpu/.local/lib/python3.11/site-packages/draccus/argparsing.py", line 203, in wrapper_inner
response = fn(cfg, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/openvla/experiments/robot/libero/run_libero_eval.py", line 117, in eval_libero
processor = get_processor(cfg)
^^^^^^^^^^^^^^^^^^
File "/home/gpu/openvla/experiments/robot/openvla_utils.py", line 77, in get_processor
processor = AutoProcessor.from_pretrained(cfg.pretrained_checkpoint, trust_remote_code=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/models/auto/processing_auto.py", line 310, in from_pretrained
return processor_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/processing_utils.py", line 465, in from_pretrained
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/processing_utils.py", line 511, in _get_arguments_from_pretrained
args.append(attribute_class.from_pretrained(pretrained_model_name_or_path, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/models/auto/image_processing_auto.py", line 407, in from_pretrained
image_processor_class = get_class_from_dynamic_module(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/dynamic_module_utils.py", line 489, in get_class_from_dynamic_module
final_module = get_cached_module_file(
^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/dynamic_module_utils.py", line 294, in get_cached_module_file
resolved_module_file = cached_file(
^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/transformers/utils/hub.py", line 398, in cached_file
resolved_file = hf_hub_download(
^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1008, in hf_hub_download
return _hf_hub_download_to_cache_dir(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1071, in _hf_hub_download_to_cache_dir
(url_to_download, etag, commit_hash, expected_size, xet_file_data, head_call_error) = _get_metadata_or_catch_error(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1533, in _get_metadata_or_catch_error
metadata = get_hf_file_metadata(
^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1450, in get_hf_file_metadata
r = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 286, in _request_wrapper
response = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 309, in _request_wrapper
response = http_backoff(method=method, url=url, **params, retry_on_exceptions=(), retry_on_status_codes=(429,))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 310, in http_backoff
response = session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/miniconda3/lib/python3.11/site-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/miniconda3/lib/python3.11/site-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/gpu/.local/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 96, in send
return super().send(request, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/miniconda3/lib/python3.11/site-packages/requests/adapters.py", line 620, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /openvla/openvla-7b/resolve/main/processing_prismatic.py (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1006)')))"), '(Request ID: 9e582d95-2415-4326-bdcd-f1da69eed331)')解决方法:模型没下载全,重新下载
2、AttributeError: 'NoneType' object has no attribute 'glGetError'
解决方法:
apt-get install python3-opengl
pip install --upgrade pyrender3、flash_attn_2_cuda.cpython-310-x86_64-linux-gnu.so: undefined symbol: _ZN3c104cuda9SetDeviceEi
解决方法:该错误由flash_attn版本与torch版本不兼容导致。用下面的命令验证核心库
python --version
python -c "import torch; print(torch.__version__)"
python -c "import transformers; print(transformers.__version__)"
python -c "import flash_attn; print(flash_attn.__version__)"如果输出的版本与官方不同,建议使用官方版本
总结
1、openvla每次的输入是image和prompt ,输出是action,其中action为1*7的向量,第1-3个向量表示机器人动作中的平移部分,控制机器人的 xyz 方向。第4-6个向量表示机器人旋转部分,使用轴角表示法(axis-angle representation)。最后一个向量表示机器人手爪的控制(开/关)。
2.openvla与仿真环境的交互过程是仿真环境告诉openvla当前摄像头拍摄到的image(本案例中摄像头是固定角度的),openvla根据image和prompt生成下个action,仿真环境根据action移动机械臂,并根据机械臂与环境的互动调整可乐罐的位置,然后生成新的image给模型。这个过程经过循环后会得到一系列的image,这些image组成了最终的操作视频。
3.openvla可以与仿真环境分开部署,然后openvla只暴露api给仿真环境调用, 这种大模型独立部署的方式非常常用。优点是只要部署一次openvla就能供多人使用,显存消耗只算单个人的量。

















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









