



当然我这个标题扣的很多同学会不同意
也能理解
比如有些人说我用while 也能实现只要最终给出一个差不多样子的markdown文件就行
这话也对
也不对
对的是似乎从产出物来讲,是那么回事,但是实际上你的东西不一定是deep research,有可能是deep hallucination,或者是deep fake
原因其实和最早玩autoGPT之类的agent没什么区别
multistep解决问题是提升精确率的一个重要因素,但是不是只靠它就可以
内生COT或者叫隐式COT的的道理也是一样的
归根到底是单一的链式结构,链式结构中间的一个step的判断错误或者偏离了问题的本质,导致最终的输出会长且错(当然这里也会通过经过self-correct等训练方式来补救)
另外research和你普通的agent 带search tool的最大一个区别就是单一问题驱动的查询和可能跨多文档,甚至多学科文档的查询,这也涉及到context的处理能力,long -context情况下注意力减退问题等等
所以直接扔一顿文档或者网页来揉出一个markdown不是不行(也可能是纯废纸),但是没那么优雅,或者没那么有效
在LLM刚问世的时候,rag就作为解决幻觉的方案到现在也都在用,但是rag一般都是一跳,也就是问完了就拉倒
除非你的问题特别清晰,一跳能解决,那这种问题也不属于deep research的范围,然后我们以前也讨论过agentic-rag,
https://mp.weixin.qq.com/s/Jxm4YrSnXcHz784qRC8t1w?token=195447011&lang=zh_CN
agentic或者类似的解决方案是有能力通过多个模型,或者本模型自己的回归方式来实现多步分解问题进而拆解,进而逐步解决
但是回到文章中开始我们提到的,它还是解决不了错了一步就废了的情况
所以总结一下
传统的「检索增强生成」(RAG, Retrieval-Augmented Generation)方法,一般是:
- 先检索
根据问题从外部知识库或语料中检索到一批相关文档。
- 再生成
将检索到的文档和原问题一并送给一个大语言模型(LLM),让它基于这些文档去写答案。
然而,RAG 在一些复杂场景下会遇到检索失败或推理不充分的问题。尤其是当问题需要多步推理,或在检索到的文档里没有一次就能找到所有关键信息时,单轮检索+单轮生成容易卡壳。
co-rag就诞生了出来
CO-rag字面的意思是
Chain-of-Retrieval Augmented Generation
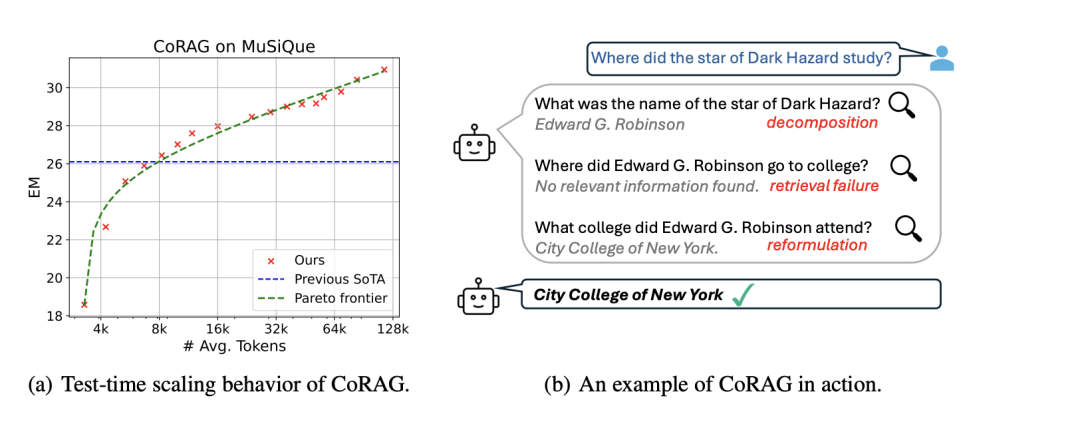
比如像图片中的问题
Where did the star of Dark Hazard study?
这个你直接去文档里查是查不到的,rag查是查不到的,然后就只能丢一堆文档进去,祈祷long-context的能给你attention对了,那就能查出来
我们这里拿模型拆解,先拆出来这个黑星是谁演的,然后查出来这人叫Edward G Robinson,然后根据第一个子查询的关键字(chain1)来找第二个子查询 它啥时候上的大学,得到的答案就是No relevant infromation found(这个相当重要一会讲),然后直接查这个Edward在哪上的大学就可以了,就找了纽约
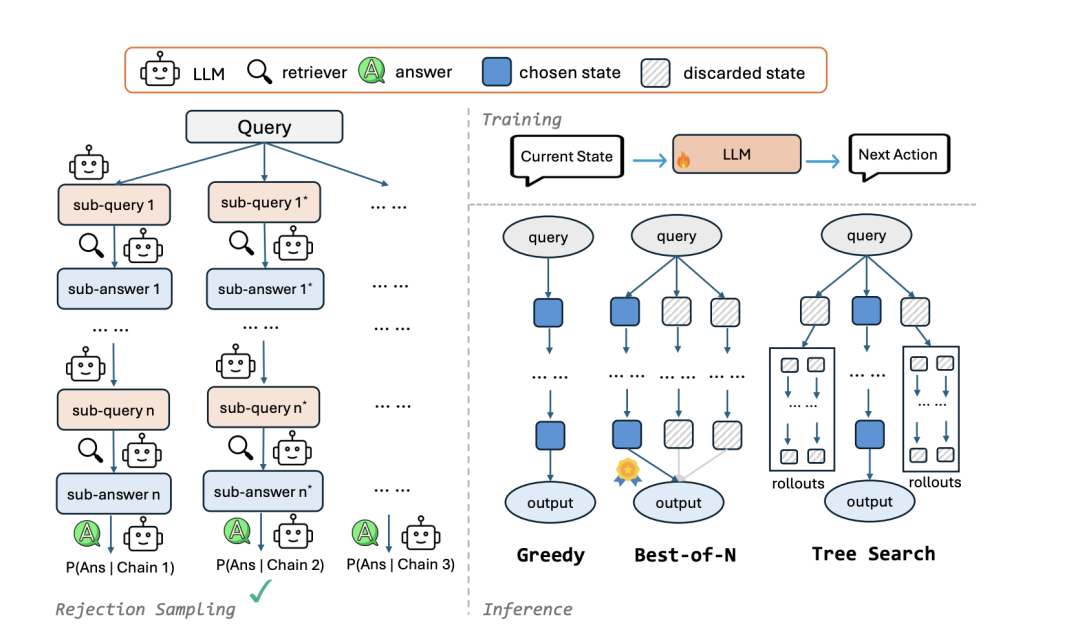
CoRAG 提出的核心思路是(如上面左图):
-
让大语言模型分步骤地提出子查询(sub-query),去检索更细粒度的信息,得到子答案(sub-answer),再根据这些子答案来更新思路、继续提出新的查询。
-
如果某一步的子答案不理想,就通过拒绝采样(rejection sampling)的方式,丢弃这条检索链,重新来一条新的检索链。
-
最终模型会在多条可能的“查询→检索→子答案→再查询”的链条里,选出最优或较优的一条来输出结果。
如果对RS,拒绝采样有问题的同学,我在这里在展开讲一下
拒绝采样(Rejection Sampling)是一种常用的概率抽样方法,用于从复杂分布中生成样本。它的核心思想是:通过引入一个辅助分布来生成候选样本,然后利用某种标准筛选出符合目标分布的样本,把不符合的样本丢弃(即“拒绝”掉)。简单来说,它是一种“生成候选样本→筛选有效样本”的过程。
数学解释
假设我们想从一个复杂的目标分布 p(x)中采样,但直接采样难度很高。我们引入一个辅助分布 q(x),它满足:
- 易采样性
我们可以轻松从 q(x)中生成样本。
- 包络条件
存在一个常数 M
使得对任意 x
目标分布满足 p(x)≤Mq(x)
步骤:
-
从 q(x)中生成一个候选样本 x^*。
-
计算样本的接受概率:Paccept(x^∗)=p(x^∗)/Mq(x^∗)
-
生成一个随机数 u∼U(0,1)u (从均匀分布中采样)。
-
如果 u≤Paccept(x^∗)u,接受这个样本;否则拒绝并重新采样。
说人话,就是让你上砂子里找金子,你找不到,但是你知道金沙大概啥样,找一批金沙,然后你在金沙里面抽样就好抽了,反正抽到u≤Paccept(x^∗)u 就留下,其他的就扔了
换句话说,拒绝采样是“广撒网再精筛选”的策略,先从容易采样的分布中获得候选样本,再根据目标分布的标准过滤有效样本
在 CoRAG 中,拒绝采样的场景和机制稍微抽象一些,但核心思想一致。具体可以这么理解:
-
候选链生成
CoRAG 会同时生成多个「查询-子答案链条」(检索链),每个链条是一个候选样本。 -
计算接受概率(评估链条质量)
根据当前链条的子答案质量、预测得分(模型给出的概率)等指标,模型可以评估某条链条是否可能通向正确答案。 -
筛选有效链条(拒绝不好的链条)
如果某条链的得分很低,或者生成的子答案不合理(比如与目标问题无关),模型会直接丢弃这条链,重新探索新的链条。 -
选最优答案
通过拒绝那些“不可能得出正确答案”的链条,模型最终能保留较优解,避免浪费计算资源。
因为玩拒绝采样吗,所以你一下子就输出了好几个sub-query。也自然有若干个sub答案,这些sub-query-sub-answer就会形成多条COT链
文章开头我们说过,如果只是COT,错了一个基本就容易整个全废(self-correct也有概率给救回来)
但是因为你才去拒绝采样的方式,生成了一堆,那在里面挑最好的链,容错率就高很多
这个最好的链是怎么选的呢?
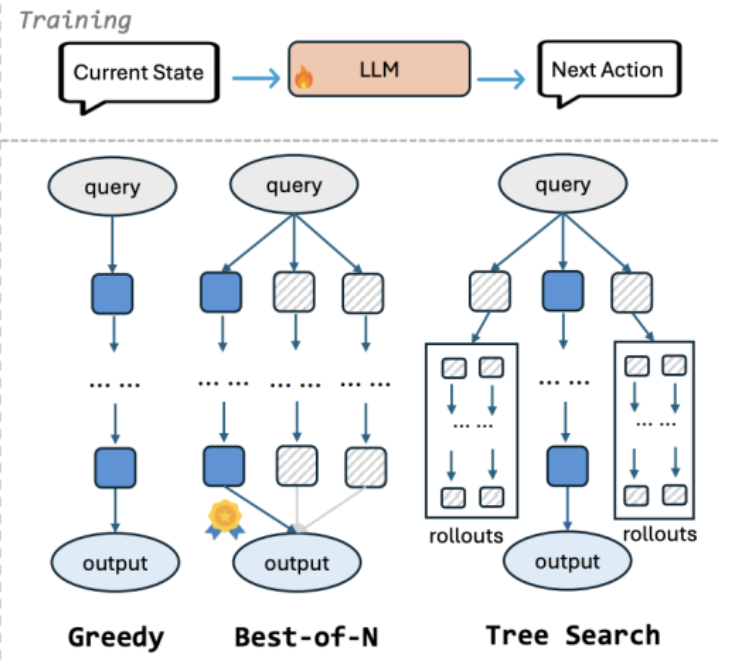
需要你对模型LLM进行训练,不是原生就能实现的,google的那个用的就是微调版本的gemini1.5pro,OpenAI这边就是o3了(所以你们用开源的那些repo玩一玩概念是可以的,可是如果要是达到像他们的产品精度是要train的),OAI也没藏着掖着,也给了说明

当然如果你不是用OAI的,你自己玩,你可以选多种方式,比如就是贪心算法,那就一条链,找最可能的概率,其实就是标准COT的方式
另外可以用BON和Tree search
这两种都是多条路径,在训练的时候:
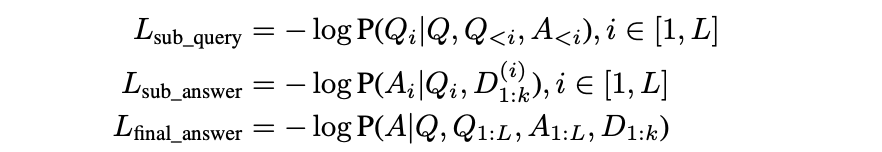
要同时优化3个函数
1- 子查询
含义:
- 目标
优化子查询生成模型,使得模型能够基于上下文生成合适的下一步子查询 Qi
- 公式拆解
P(Qi∣Q,Q<i,A<i)- Q原始问题。
- Q<i之前生成的所有子查询
-
A<i之前生成的所有子答案。
-
- 负对数似然
:用于最大化子查询的生成概率。
2- 子回答
含义:
- 目标:优化子答案生成模型,使其能够根据子查询 Qi和检索到的文档 D^(i) 生成合适的子答案 Ai
- 公式拆解:P(Ai∣Qi,D^(i))表示在给定子查询和文档的条件下生成子答案的概率
- D^(i):是通过检索器从知识库中获取的相关文档
3- 最终回答这3个函数可以理解成3个子任务
第一个第二个是为了让它有更好的链式思考,第3个就是推理的时候决胜负了
对多条链的输出接口打分是怎么实现的?

又回来看这个,这个就是“没有找到相关信息”
CoRAG框架在评估检索链(推理)时,并非只评估每一步骤是否找到答案的可能性,而是评估整个链条最终导致模型输出“没有找到相关信息”的可能性。具体来说,其评估方式如下:
- “没有找到相关信息”的对数似然值:
-
CoRAG 通过计算整个检索链在“假设答案是‘没有找到相关信息’”的条件下的对数似然值来评估该链的质量。
- 这个对数似然值是针对整个链条的,而不是针对链条中的某一步
这意味着模型推理时只会考虑整个检索过程,看最终结果是否导致它输出 “没有找到相关信息”。
- 对数似然值越高,意味着模型认为在该检索链下,最终答案是 “没有找到相关信息” 的可能性越高
-
- 惩罚分数:
- “没有找到相关信息”的对数似然值被用作“惩罚分数”
- 惩罚分数是针对整个检索链计算的,而非每一步。
- 惩罚分数越高,检索链的质量越低;惩罚分数越低,检索链的质量越高
- 解码策略中的应用
-
在最佳N抽样(Best-of-N Sampling)中,模型会采样多条检索链,并选择惩罚分数最低的那一条链。
-
在树状搜索(Tree Search)中,模型会探索不同的检索链,并保留平均惩罚分数最低的状态。
-
这两种方法都依赖于整个检索链的惩罚分数来选择最佳的检索路径。
-
因此,CoRAG 推理时不是分别评估检索链每一步骤找到答案的可能性,而是通过整个链条的“没有找到相关信息”的对数似然值(或惩罚分数)来评估整个链条的质量。
那折腾半天训练的时候还要1和2两个关注于步骤的损失函数干嘛呢?
训练阶段:多任务学习
-
CoRAG 的训练过程是一个多任务学习框架,同时优化以下三个损失函数 :
- 子查询预测损失 (Lsub_query)
训练模型生成合适的子查询 。
- 子答案预测损失 (Lsub_answer)
训练模型从检索到的文档中提取正确的子答案 。
- 最终答案预测损失 (Lfinal_answer)
训练模型生成最终的正确答案。
- 子查询预测损失 (Lsub_query)
-
这三个损失函数共同作用,使得模型在训练过程中不仅学习如何进行逐步检索和推理,也学习如何最终生成正确的答案 。
- 中间步骤的损失函数
(Lsub_query 和 Lsub_answer)至关重要,因为它们提供了中间过程的监督信号,帮助模型学习链式思维和逐步解决复杂问题的能力 。
- 没有中间步骤的训练,模型将无法有效地进行多跳推理
- 训练阶段的目标是学习能力
:训练阶段的目标是让模型学会如何进行逐步检索、推理和整合信息以解决复杂问题 。中间步骤的损失函数提供了必要的监督信号,帮助模型掌握这些能力。
- 推理阶段的目标是解决问题
:推理阶段的目标是使用训练好的模型来解决实际问题。我们最终关心的是模型能否给出正确的答案,而不是模型中间推理的步骤。
- 中间步骤的质量是最终答案质量的保证
:虽然推理阶段不直接评估中间步骤的质量,但是模型学习的中间步骤的质量会直接影响最终答案的质量 。
OK,现在理解了为什么推理只评估整个COT链的最终质量,我们再谈谈BON和Tree的算法异同。
而BON和Tree的总体思路其实很像
区别就是:
BON:通过独立采样多条检索链进行并行探索。占用算力少
Tree(比如MCTS):通过广东优先搜索(BFS)+rollout来拓展更多路径,路径多算力占用就大
(说句也没那么恰当的话,你可以把BON当作Tree的BFS和rollout等于1来看待)
最终BON也好,tree也好,哪个链惩罚分数最低,那它出现“No relevant infromation found”的可能性就越低,就越容易被选中最优,保证了回答的质量和准确度,惩罚分数这块也得训
好,做个总结,如果要玩deep research,如果要产品化,要用Co-rag来实现time test scaling或者类似的方式实现,同时回答更精确,占用的context越合理,递归查询的轮次也能更多,但是,LLM要训练(原生不太容易做到),Bye

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









