




最近Waymo发的论文EMMA端到端确实在自动驾驶届引发了很大的关注,核心的原因是它采用的端到端模型是基于Gemini Nano的语言模型,目前看现在做端到端方案的,就它和特斯拉是语言模型为底座来实现多模态视觉输入的。
EMMA:End-to-End Multimodal Model for Autonomous Driving
端到端多模态自动驾驶的意思,不是艾玛电动车

论文地址:2410.23262
先看看他是怎么做的
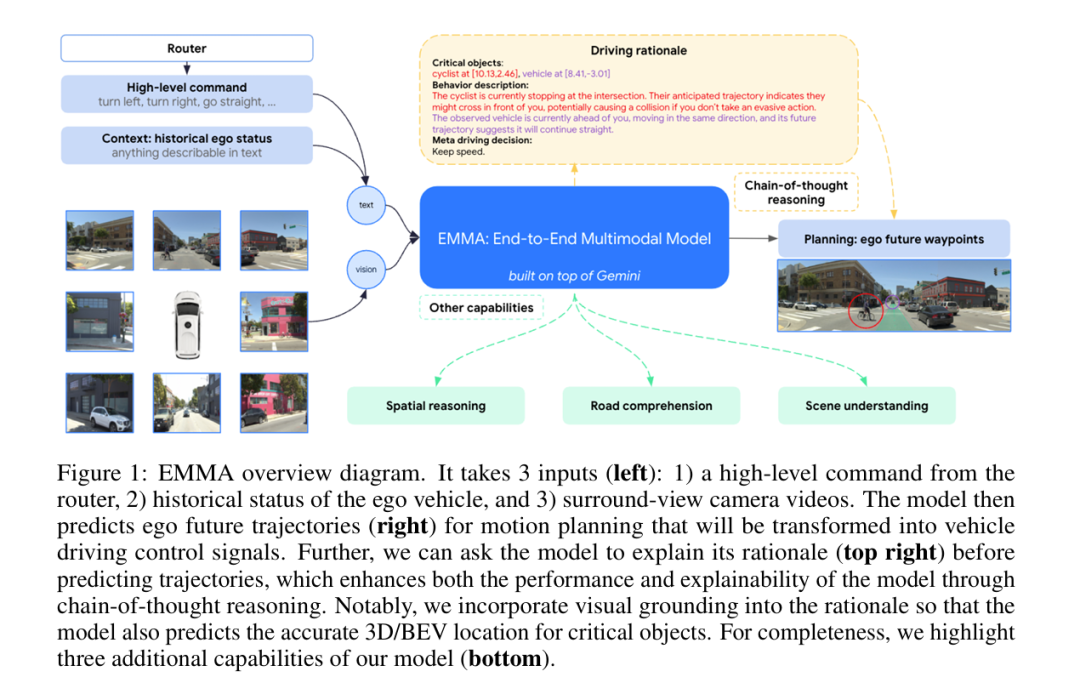
第一:感知层面,它纯视觉,没有雷达之类的输入
第二:输入层面是多维度的信息,包括高维指令,来自于比如google地图的导航指令,例如向左,向右之类的,具象化可以被认为是:“前方请在第二个匝道右转出匝道这种指令”
第三:任何关于此车也就是ego car的既往历史路线和其他的数据
然后就没什么了
把上面这三种东西,我们叫做T和V,T是text信息,V就是vision信息,也就是视频图像一类,最终拆帧也都是以图片形式来embedding的
紧接着,我们要设计一个网络G。这个网络EMMA里用的是Gemini的Nano,选Gemini Nono有它显示的意义,核心原因是这东西不开源,所以堆料比较猛,没有太多的顾及,可以很深度的做蒸馏。试想如果GPT4o出一个Nano是什么概念就可以了。
既然要不是day1就自己训练的,那么底模肯定是要选一个泛化能力高的,推理能力尽可能强的模型
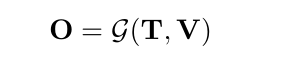
O自然就是把T和V输入给G以后生成的输出了
因为是语言模型,所以O其实是一个序列
![]()
输出的概率分布就可以写成下面这样
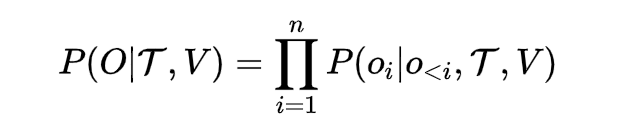
我们进一步细化一下,这几个参数和输出
V就是所有视觉的东西了吧,一般我们回塞给它一个BEV的视角,因为要感知周边的所有环境

T要分几个维度:
第一个就是T_intent,也就是高维指令,什么左转,右转啥的
第二个就是T_ego,历史自车状态
-
-
这些状态表示为BEV空间中的一组路径点坐标 (x_t, y_t),用于 -T_h到 T_h ,这一段时间的时间戳。这些坐标表示为纯文本,无需特殊的标记。
-
这一历史状态也可以扩展其包含更高阶的自车状态,如速度和加速度。
-
![]()
未来轨迹就可以被表达成以上的式子
那么好,现在我把我的公式再拿出来
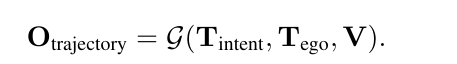
我的摩西那个可以与出来一个O'_trajectory对吧,而基于训练数据,它一定有个真实的未来轨迹O_trajectory,两者求个Lost,这不就损失函数也有了吗?
其实关于基本训练这块,就是这么的简单
牛B的是,这个训练是自监督的,你可以认为和语言模型的pretrain差不多,两者都是没什么人类输入的干扰,比如做语言模型,你的next-token的predicate就是这句话的下一个字对吧?那你玩这个EMMA,next-token就是输入给你目前的信息,你给我预测后面车的位置(x_t, y_t),然后多个位置就有一个trajectory,就完了。
这样的好处是和预训练LLM的道理是一样的,尽量让模型寻找隐空间里不易被人类捕捉到的规则,从这个角度上来讲EMMA的论文有这一个点就很有价值。
当然也不是啥任务都适合拿自监督来训练,例如3D物体检测、道路图估计和场景理解。这些任务需要使用人工标注的数据进行训练,这些就跟一般supervior的tunning也没啥区别了
人们都反映大模型是黑盒,尤其在自动驾驶领域这块,需要强烈的决策可解释性,EMMA用了prompt让LLM输出它的COT决策机制,这点我觉得是另一个创新点(这块学到了,我拿O1来做自驾的规划输出这块,最近也准备加入reasonning输出这部分
COT是啥就不解释了,看我频道的读者都知道,确实可以一定成都上增强推理能力并提高可解释性的强大工具(O1都玩TOT了,而且是原生,更牛B)。在 EMMA 中,作者将链式思维推理引入到端到端规划器轨迹生成中,通过要求模型表述其决策依据 O_rationale ,同时预测最终的未来轨迹路径点 O_trajectory 。
我们按照层次结构组织驾驶依据,从4种类型的粗到细的信息开展:
R1 - 场景描述 (Scene description):
-
广泛描述驾驶场景,包括天气、时间、交通状况和道路条件。
-
例如:天气晴朗,并且是白天。道路是一条没有分隔的四车道街道,中间有一个人行横道。街道两边停有汽车。
R2 - 关键物体 (Critical objects):
-
是那些在道路上并可能影响自车驾驶行为的代理物
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









