



更第四篇,上周有点私事,恢复更新
上次的文章 英伟达的GPU(3) (qq.com)
书接前文,我们上章说要更新GPU的内存机制,本次就讲点这个
先做个定义,我们说内存(显存),也分物理内存(SRAM,DRAM.HBM)和逻辑内存(逻辑可访问地址,这个倒和物理不一定1:1对应),这个和处理CPU的项目的时候没啥区别。
我们之前讲过CUDA编程体系块和线程等逻辑概念。这块不熟悉的可以看第二章 英伟达的GPU(2) (qq.com)。
block,thread啥的各自有各自的工作范围,这些范围其实就是分配GPU逻辑内存和管理线程,block之类资源的一个标尺
-
Local Memory:每个线程都有本地内存,存储临时变量。范围最小因为就服务于每个单独的线程。
-
Shared Memory:同一个Block内的线程可以用共享内存共享数据。与访问全局内存相比,这允许同一块内的线程更快地通信和访问数据,因为近一阶。
-
Global Memory:这是GPU中最大的内存,可以被所有块上的所有线程访问。但是慢吗,离得远。
-
Texture and Constant Memory:GPU 中的特殊内存,针对访问特定数据类型(例如纹理或常量值)进行了优化。所有块中的所有线程都可以访问这些内存类型。
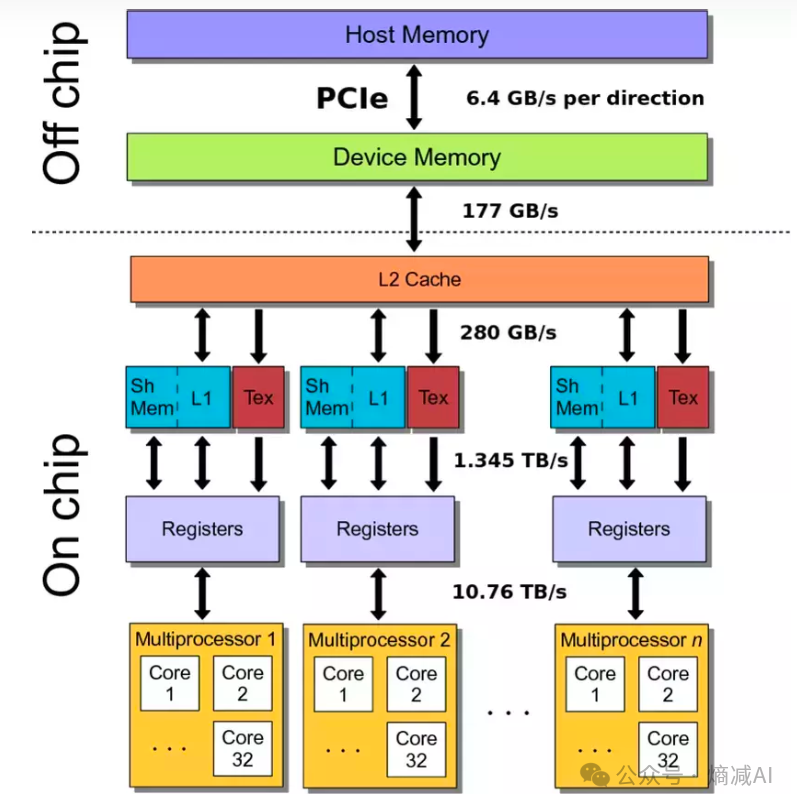
然后我们看实际的物理内存上半部分是CPU的维度,下半部分的On-chip才是GPU的维度,然而这里有一个小误区,HBM虽然是GPU上面的,然后被换分在了Off chip的领域。就是上面的绿色部分的Device memory。
绿色的HBM(Device memory),由于操作系统也不在CPU那边,所以比如你要是训练,或者推理时候读取数据,模型,还得从能掌管IO的CPU的内存那边拿数,CPU的内存和HBM显存之间想通信,一般是经过PCIE,这个图有点老,PCIE还显示6.4Gbps, 实际上现在的PCIE Gen5都15.6G了,下一代Gen6能到256。
另外我比较推崇的GH200,或者GB200架构
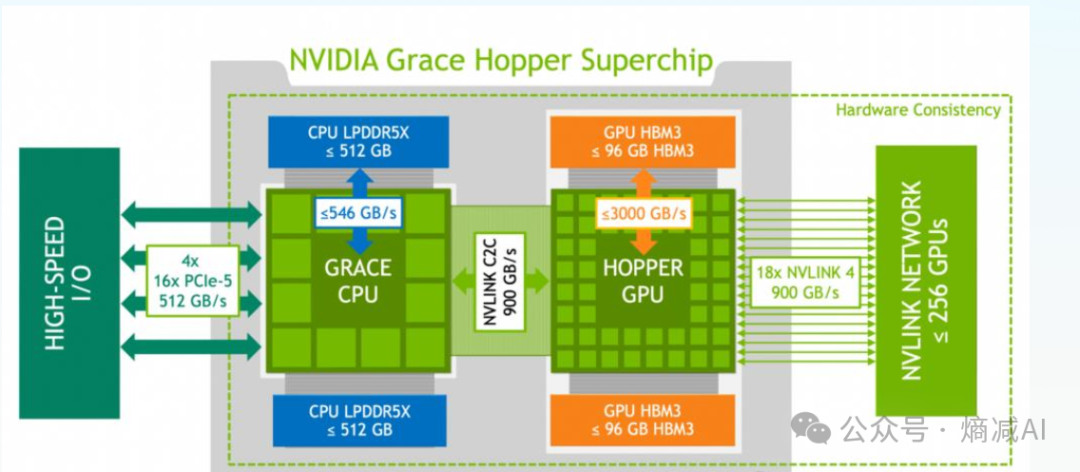
如图所示,Hopper也就是H100GPU,不光是用Nvlink链接到NVswitch上面,而且可以和Grace CPU之间有900GB/s的双向通信的C/2链接。
这个怎么理解?
NV虽然一直耍心眼总标双向带宽,比如900GB其实是单向450GB,但是毕竟是大B啊,所以合3.6T/s的单向传输速度。
贵肯定是贵,但是你要比PCIE的呢?H100标准的Gen5 PCIE 的CPU和GPU之间应该是2根PCIE GEN5, 编码是128b/130b的,传输速度能跑到128Gbps已经是极限。
差28倍!
当然有"懂"的兄弟这时候会实时的抛来一个challenge ,例如“你到底懂不懂啊?Nvlink也就链接GPU的时候有用,负责做本机箱内的GPU联合通讯源语的时候有用,跟CPU有啥关系",其实如果能喷出来到这个级别的哥们还是挺专业的,但是我的补充一下,在现在NVlink5一根都1.8TB/s的情况下,其实压力不特别在机箱这侧,因为满打满算8个。至于为什么在CPU这,懂的兄弟就不解释了,也没什么可解释的,做个train的都懂。不懂的我卖个关子,后面讲(其实看我原来的一些文章都有解释...)。
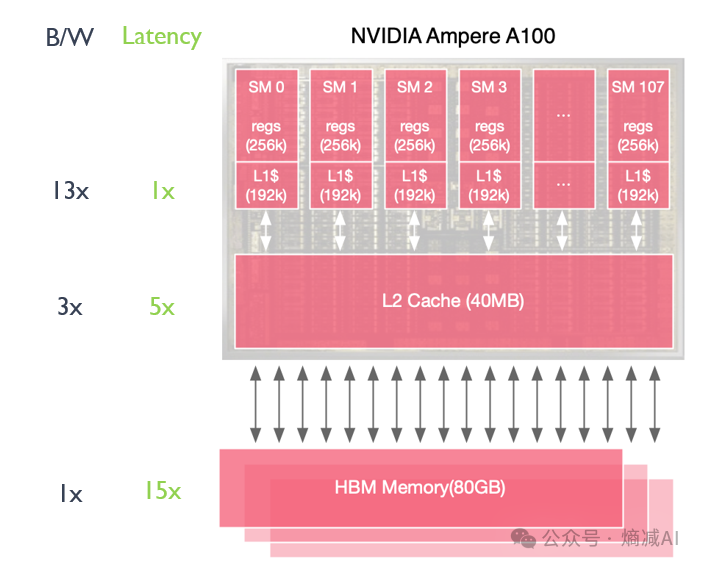
然后比如拿H100举例,从HBM把模型和tokens读上来之后,就进入到缓存体系了,GPU目前主流设计还是以2级缓存为主。你们经常玩的flash-attention也主要工作在这个部分。
NVIDIA A100 GPU 的缓存架构包括两级缓存:
-
一级缓存(L1 Cache):每个流式多处理器(SM)都有自己的一级缓存。A100 的一级缓存为每个 SM 提供 192KB 的缓存。一级缓存在 A100 中被实现为共享内存/缓存组合,提供低延迟访问每个 SM 中经常使用的数据和指令。
-
二级缓存(L2 Cache):A100 GPU 具有一个全球二级缓存,所有 SM 共享这个缓存。二级缓存的大小为 40MB,显著大于一级缓存。二级缓存有助于减少跨 SM 数据访问的延迟,并减少对高带宽内存(HBM)的需求。
一级缓存(L1 Cache)位于每个 SM 内部,由于其需要低延迟操作,通常使用 SRAM(静态随机存取存储器)实现。二级缓存(L2 Cache)也通常使用 SRAM 实现,以满足高速度访问的需求。
一级在SM内部,纯粹的片上片,所以虽然两个缓存都是SRAM,但是大小区别很大,因为就近的和tensor core或者cuda core通信,所以L1那边也是速度起飞
这两级缓存协同工作,提高了 A100 GPU 的整体效率和性能,减少了对 HBM 内存的延迟和带宽需求
从下到上,速度的和延迟也是成线性的递增状态,延迟呈现线性递减(图上左边有标准)
再往上就是寄存器了,那也不能和这些标准存储来相比,也没啥可谈的。
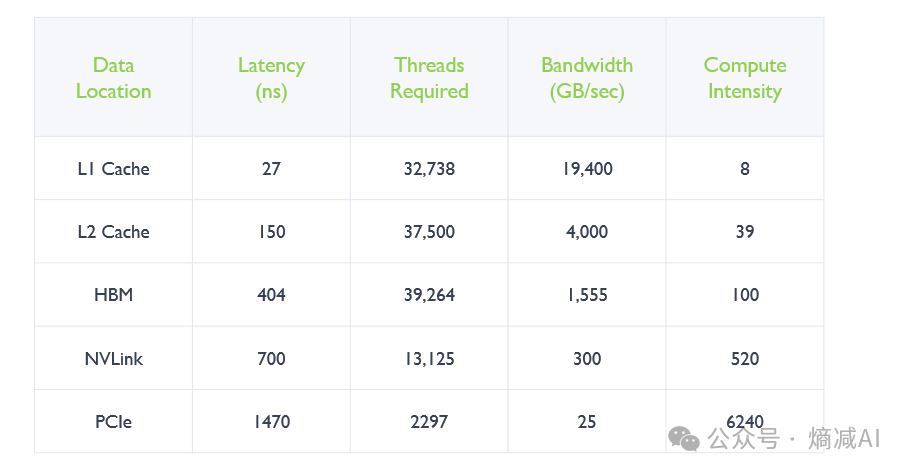
下面这个表是在不同传输存储介质里面A100的延迟,带宽,计算密度,线程的一些对比
今天内存,缓存就讲到这里,后面deepdive一下,tensor core和显存,cache的合作机制,workflow,然后讲Nvlink,再后面讲讲A,H,B和R的架构,然后基本这个系列就结束了。


















 5630
5630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









