




 KAN(Kernelized Attention Networks)旨在改革传统的多层感知机(MLP),解决其在深度学习中遇到的梯度消失、参数效率低下等问题。通过将非线性激活函数放在边而非节点上,KAN减少了网络规模,提高了灵活性和可解释性。虽然KAN在某些场景下表现出更好的性能,但目前训练速度慢且缺乏硬件加速。KAN的引入为解决复杂科学方程提供了新的思路,有望在AI4Science领域发挥作用。
KAN(Kernelized Attention Networks)旨在改革传统的多层感知机(MLP),解决其在深度学习中遇到的梯度消失、参数效率低下等问题。通过将非线性激活函数放在边而非节点上,KAN减少了网络规模,提高了灵活性和可解释性。虽然KAN在某些场景下表现出更好的性能,但目前训练速度慢且缺乏硬件加速。KAN的引入为解决复杂科学方程提供了新的思路,有望在AI4Science领域发挥作用。
这个也算小周带你读论文系列吧。
说KAN就不能不说MLP(多层感知机)
其实你们现在玩的Transformer,包括所有的以前的模型,简单说可以理解为现在工作的any模型,深度学习领域的啊,都可以说是由MLP组成的。
KAN其实想对MLP革命。
MLP是咋实现深度学习任务的呢?
比如一个分类任务,网络大概3层吧4个输入1个输出,2个隐层,4-2-1的一个mlp
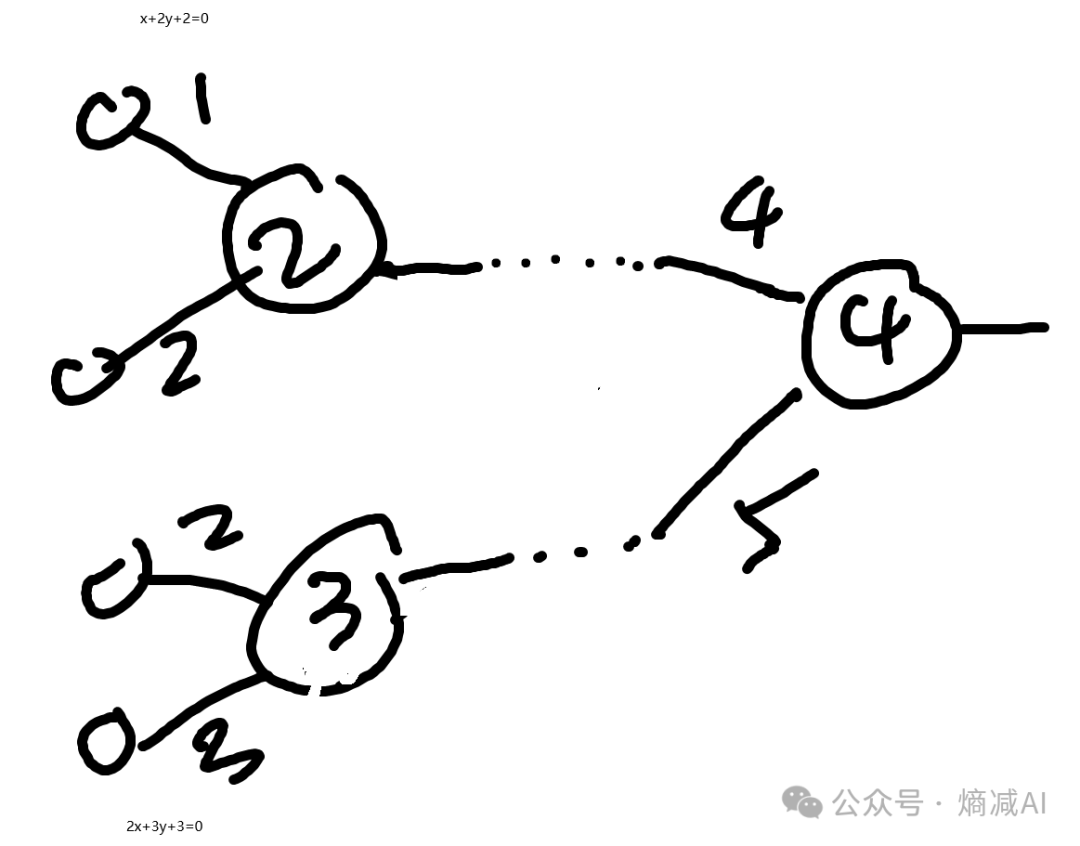
图-1
函数我瞎写的,就是那么个意思,比如左边这两个函数,它可能图像是下图左边这两个这样。 然后由这两个函数进一步结合就会出下图右边这样的,表示图-1的右侧节点。
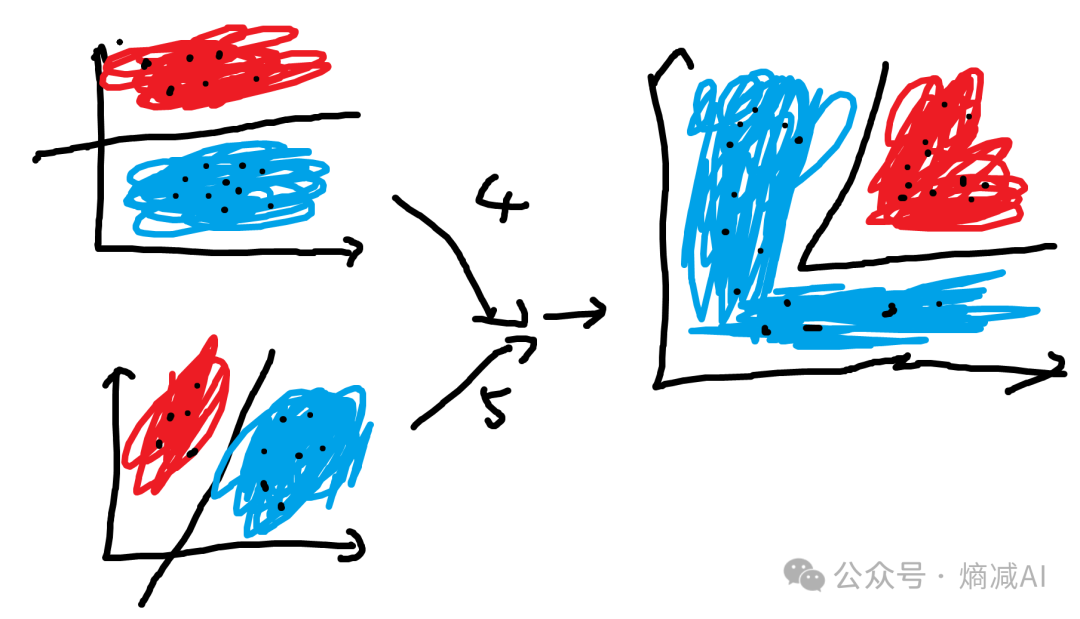
图-2
看起来好像不错,但是实际的项目里面,不可能这么规整的,所以我们要把线性的东西给非线性化,就是加激活函数
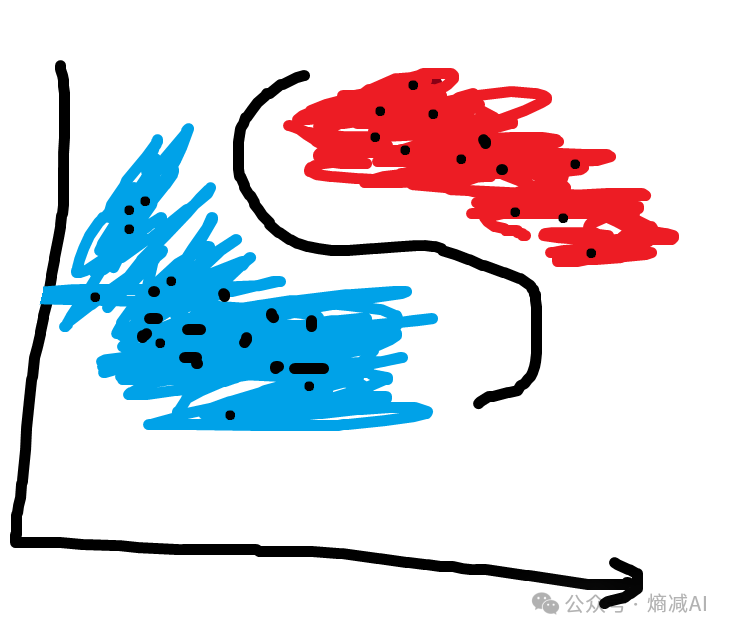
正常深度学习由于维度众多,也就是神经源节点多,所以其实理论上参数越多,越可以拟合成一个曲面。
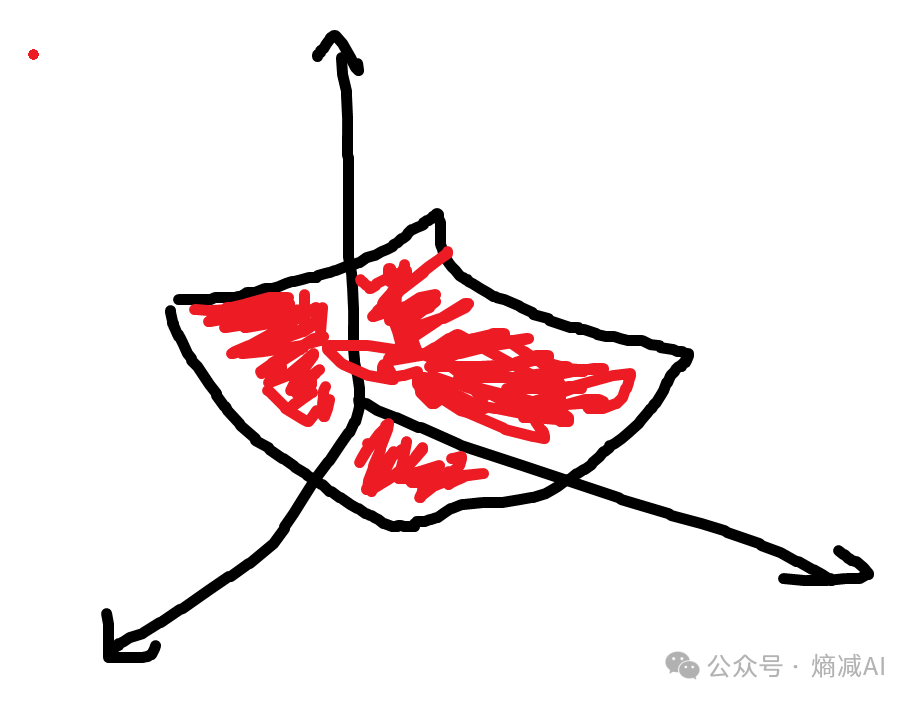
传统MLP一般就是一大堆线性层多层全连接然后跟着一个激活函数来实现这样的功能。
比如Transformer,先是qkv,然后o(这些也都是线性层全连接,本质也可以当mlp变体)最后过两层MLP,第二层MLP带激活函数。relu或者SwiGlu,这是大家平时用到的。
用数学表示就是这样
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









