




 本文探讨了GPT4-o的两大技术变革:LLM的全新编码方式和多模态直入直出。LLM编码方式改进了Tokenizer,对非英语语种更友好,速度提升显著。多模态直入直出整合了语音、视频和文本,实现高效处理。同时,文章提到了Whisper模型在语音识别和处理中的应用,并指出GPT4-o在延迟和性能上的突破,预示着未来多模态研究的趋势。
本文探讨了GPT4-o的两大技术变革:LLM的全新编码方式和多模态直入直出。LLM编码方式改进了Tokenizer,对非英语语种更友好,速度提升显著。多模态直入直出整合了语音、视频和文本,实现高效处理。同时,文章提到了Whisper模型在语音识别和处理中的应用,并指出GPT4-o在延迟和性能上的突破,预示着未来多模态研究的趋势。
5月15号发布的,为了狙击Google。
刨去宣传的那些梗有哪些技术上的变革值得我们注意?
我总结主要有2条
-
一是LLM这块全新的编码方式
-
二是完整的多模态直入直出
LLM这块全新的编码方式:
Tokenizer的变化非常重要, 主要是压缩技术,对英语以外的语种非常友好,以中文为例,能提供1.4倍的压缩比,如图中的34到24
又因为是双向(input,output),所以意味着在处理速度这块,啥也不变的情况下提升2.8倍 ,这个还是挺有吸引力的。

速度提升意味着降低了延迟,GPT4-o的响应速度这块,即使是文本对文本有多快,大家或多或少也看过demo了,所以我也不演示了,另外一个优势是阴性的就是在小语种上,价格会更便宜。
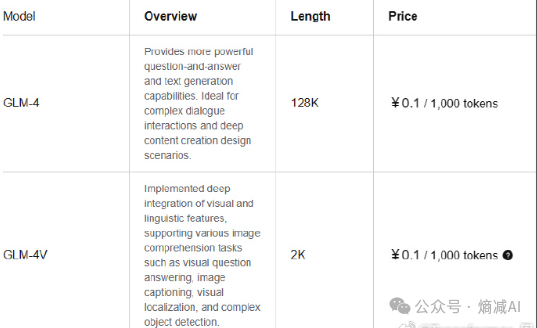
之前智谱说自己的100万tokens 1元是glm3,然后字节豆包就来个100万tokens 8毛,但是其实智谱的所谓GLM4是 每100万tokens 100元,对比GPT4-o的就算全算贵的output tokens,每100万才 15美元。
然后中文是再降百分之25(新tokenizer压缩,参见上图32到24,所以能压缩百分之25的成本),能合到80人民币,每100万tokens。
那么是你,你会买哪个?我这还没算input 的token其实才5美元 每100万tokens。对于国内的LLM,打价格战,目前看肯定不是一个特别好的选择。

但是Tokenizer的改变也不全是正向的。
因为单token表达的意义或者叫concept变大,词表单个词(甚至有些词接近短句)就会变大,它就没被分开。结合中文训练语料清洗不完善,毕竟是老外,对中文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









