




 本文介绍了支持向量机中的软间隔概念,允许部分样本分类错误以提高模型泛化能力。通过调整参数C,控制模型的容忍度。此外,还探讨了正则化在防止过拟合中的作用,以L1和L2正则化为例,解释了如何通过正则化项减少模型复杂度。
本文介绍了支持向量机中的软间隔概念,允许部分样本分类错误以提高模型泛化能力。通过调整参数C,控制模型的容忍度。此外,还探讨了正则化在防止过拟合中的作用,以L1和L2正则化为例,解释了如何通过正则化项减少模型复杂度。
软间隔与正则化
软间隔
之前的博文中提过,支持向量机有一定的容错性,它允许有样本被分错,支持向量机以大局为重。特别是在存在噪音或者异常点的情况下,将这些所有的样本都完全的进行线性可分,这样很容易引起过拟合。所以支持向量机是允许在一些样本上出错的,为此,引入了“软间隔”的概念。
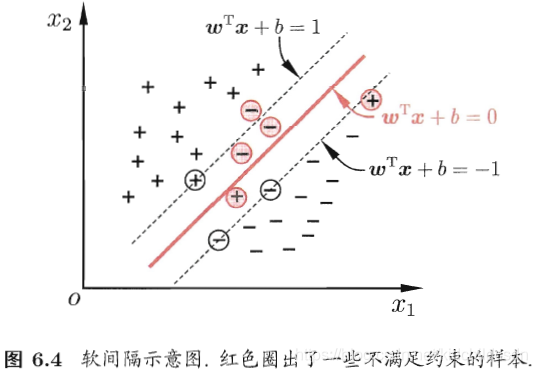
在之前的博文中介绍的支持向量机形式是要求将所有的样本全部分类正确,这称为“硬间隔”。“软间隔”是允许某些样本不满足约束。但是不满足约束的样本也不能太多,否则这个分类器的学习能力不足,很容易欠拟合。所以,在最大化间隔的时候,优化目标写成:
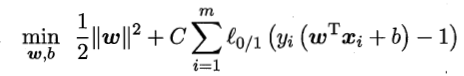
在我们写代码,调用sklearn库的时候,SVM函数中有一个参数为,就是上述等式中的
。我们一步一步慢慢看看这个等式的含义。首先
大于0,是一个常数,其中:
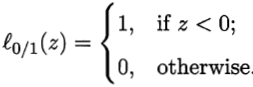
我们解释一下上面这个等式, 之前就说过是我们样本的真实标签,
,
是我们分类器的预测结果,这里也就是支持向量机的预测结果。
第一种情况:如果真实标签和预测结果一致,那么=1,这个应该不难理解,这样一来就是说我们的分类器分类是对的,那么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1759
1759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









