




 本文探讨了支持向量机(SVM)从理想化的硬间隔转向更为实用的软间隔的概念转变。在现实世界的数据集中,找到能够完全线性分离各类别的核函数通常是不可能的,甚至如果找到了这样的核函数,也可能是因为过拟合。为了解决这个问题,SVM引入了软间隔的概念,允许某些样本点违反分类边界,通过引入松弛变量和惩罚系数,以最小化错误分类的样本数量同时保持最大间隔。
本文探讨了支持向量机(SVM)从理想化的硬间隔转向更为实用的软间隔的概念转变。在现实世界的数据集中,找到能够完全线性分离各类别的核函数通常是不可能的,甚至如果找到了这样的核函数,也可能是因为过拟合。为了解决这个问题,SVM引入了软间隔的概念,允许某些样本点违反分类边界,通过引入松弛变量和惩罚系数,以最小化错误分类的样本数量同时保持最大间隔。
由硬间隔转为软间隔
理想化的支持向量机存在一个超平面将不同类的样本完全划分开。然而在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中完全线性可分。退一步说,即便恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合造成的。
因此缓解该问题的办法是允许支持向量机在某些样本上出错,为此要引入“软间隔”的概念。如下图所示:
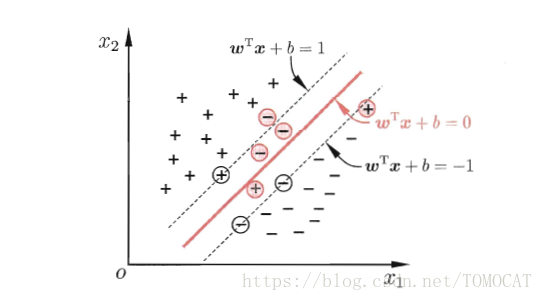
即允许某些样本不满足约束
优化目标函数
在最大化间隔的同时,我们需要不满足约束的样本点尽可能少,于是优化目标可以写成:
其中是一个常数,
是一个损失函数
但是由于非凸,非连续,数学性质不太好,使得参数不容易直接求解。于是人们通常用其他一些函数来代替
,称为“替代损失”。常见的替代损失函数有:
| 损失函数 | 公式 |
| hinge损失函数 | |
| 指数损失函数 | |
| 对率损失函数 |


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









