




点击上方蓝色字体,关注我们
 作者简介
作者简介
浩彬老撕,R语言中文社区特邀作者,好玩的IBM数据工程师,立志做数据科学界的段子手。
个人公众号:探数寻理
往期回顾:

在上期,浩彬老撕给大家介绍了非线性回归模型,解决了在现实环境中,非线性形式的问题。但是进一步地,我们的因变量也并不总是数值型变量,有可能也是分类型变量,那么对于这种问题,我们能不能也利用回归分析进行适当的扩展,使其也能够解决分类问题?
答案显然也是肯定的。
1.Logit回归
本期将会大家介绍逻辑回归,虽然逻辑回归并不复杂,但正是由于其简单,高效,可解释性强的特点,在实际用途中十分的广泛,从购物预测到用户营销响应,从流失分析到信用评价,都能看到其活跃的身影,可以说,逻辑回归占据了分类算法中非常重要的地位。
回想在上一期中,我们谈到当因变量与自变量的关系式不再是线性时,通过引入衍生变量y’,使其转换为线性表达形式。那么很自然地,对于我们现在面临的任务,我们就需要一个转换,使得分类变量0和1转化为可用的形式。
先考虑一个二分类的预测变量,正如前面所说的,显然由于分类数据的特点,已经不适合运用传统的线性函数进行分析。但是二分类事件的y的期望值E(y)来说,它等价于事件发生概率,从y到E(y),我们就把事件发生与否与值域在[0,1]区间的事件发生概率相联系,这提示我们可以用事件发生的概率进行代替。
既然使用发生概率代替的话,一个自然而然的选择是把回归函数的值域限制在[0,1]区间内,这样当f(xi)接近负无穷时,将有E( yi)趋近于0,而在f(xi)接近正无穷时,将有E(yi )趋近于1,这样看来,显然相比于研究二元变量y与x的关系,研究y发生的条件概率与x更具适应性。

在没有任何先验条件的情况下,这里的阈值一般选择0.5。但当我们有进一步明确需求的时候,阈值也是可以调整的,例如我们希望对正例样本有更高的准确率要求,则可以把阈值适当地调高,例如调高到0.6;相反,假如我们希望对正例样本的召回率要求更高,则可以把阈值适当地降低,例如降低到0.4;
一般地,我们选择Logit函数作为转换函数,Logit函数的形式:
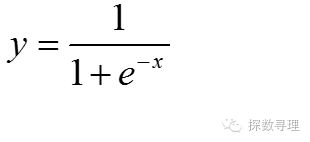
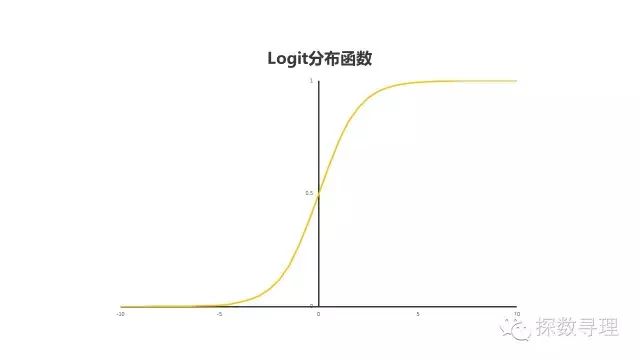
Logit函数图像是一个典型的S型的曲线,并且它的值域是在[0,1]之间
进一步地,我们利用logit函数,可以把事件发生的条件概率与x表示为
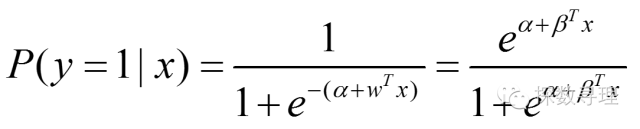
同样,我们也可以定义一个事件不发生的概率为:
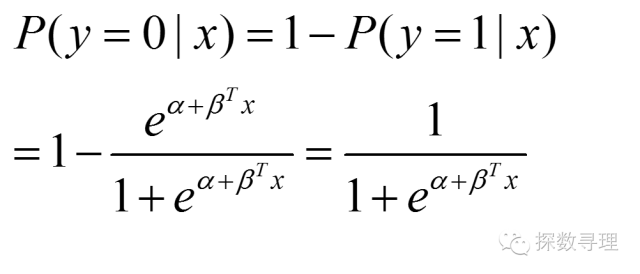
为了更显简洁,不妨作如下转换:
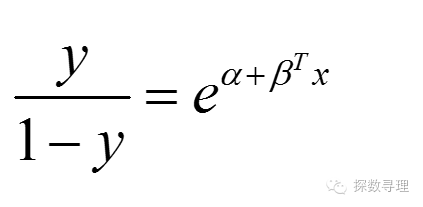
上式左边实际上就是表示“事件发生的概率”与“事件不发生的概率”之比,称之为事件的发生比,简称odds。

实际上,转化为线性函数形式后,我们可以看到逻辑回归实际上就是以线性回归的形式去逼近时间发生优势比的对数,因此也有一些文献称之为“对数几率回归”。
2.参数估计
考虑到在Logit回归的推导中,咱们已经把事件发生的概率公式给出,那么我们就可以借助极大似然估计进行参数估计的工作,设

求得对数似然函数并整理:

3.实战案例:
样例数据:个人收入水平调查分析.xlsx
链接: http://pan.baidu.com/s/1cmmP1W
密码: raxx
该数据集是某地区的个人收入调查分析,包含32561条记录,其中目标变量是收入水平(分别是<=50k以及>50k),其他自变量包括年龄,受教育时间,性别,资产净增,资产损失,一周工作时间。
模型流如下所示:
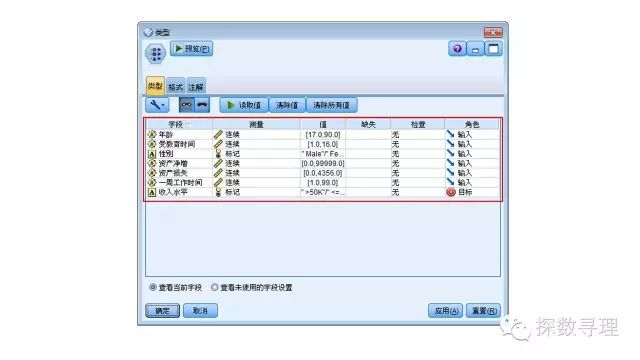
利用Excel源节点读取数据后,接入类型节点,在类型节点中:
(1)把收入水平的测量设为‘标记’,把角色设为‘目标’;
(2)把年龄,受教育时间,性别,资产净增,资产损失,一周工作时间设为‘输入’;
上述介绍的内容在Modeler中是在Logistic节点中实现,因此我们在下方建模选项板中,选中Logistic节点,并将其添加到流。
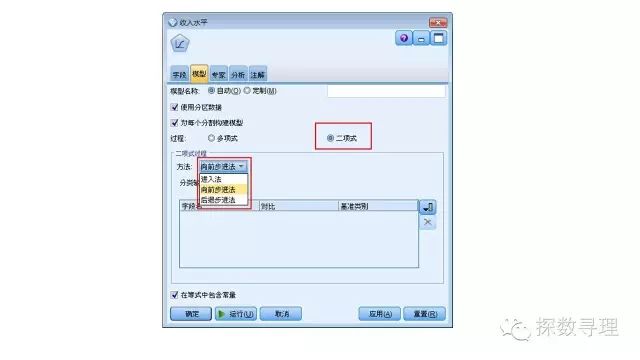
在回Logistic节点中,模型选项卡下,因为我们的目标变量‘收入水平’属于二分类变量,因此我们选择‘二项式’;
在二项式过程中中,我们选择‘向前步进法’建立Logistic回归模型
选择好后,点击运行。
运行模型后,点开模型块查看模型结果。
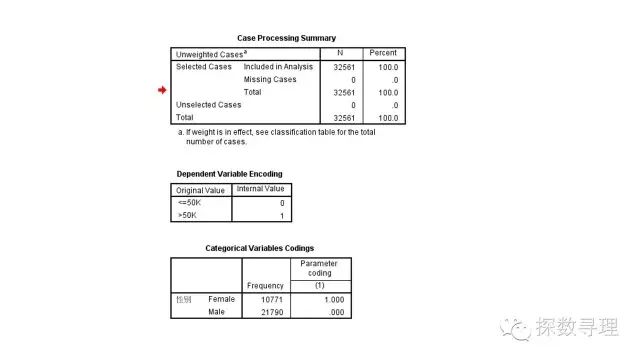
首先看到的是CaseProcessing Summary,我们知道我们一共使用了32561条记录构建模型,其中所有记录无缺失;由于自变量与因变量都含有分类变量,因此需要进行编码。其中因变量,我们把收入水平>50k设为1,收入水平<=50k设为0;另外在自变量部分,只有性别属于分类变量,我们看到其中女性有10771个记录,男性则有21790个记录,其中我们把女性设为‘1’,男性设为‘0’。
之后直接看到模型结果,可以看到一共经历6补构建了最终模型,纳入了6个自变量,即我们所有的自变量都被纳入了方程,并且检查系数显著性检验结果,发觉所有显著性检验结果都小于0.05。额外地,看到性别(1)自变量,这是因为性别属于分类变量,我们将其设置为哑变量。即性别为女性的样本进入方程,将减去1.175*1,而性别为男性的样本进入方程则是默认该项取0;
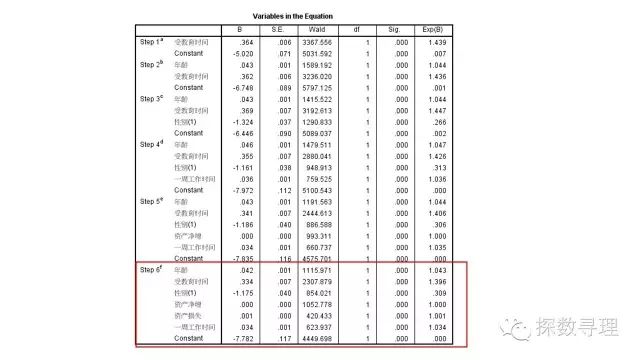
根据结果,我们可以写出最终的回归方程有:

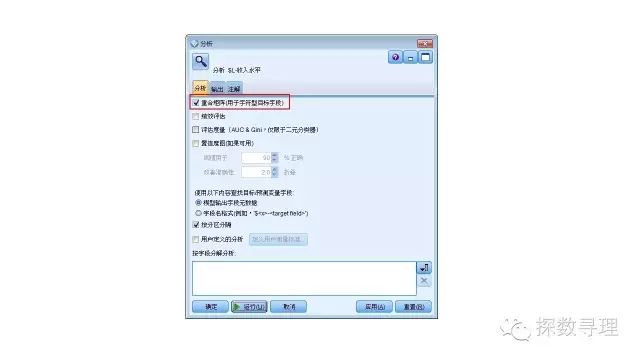
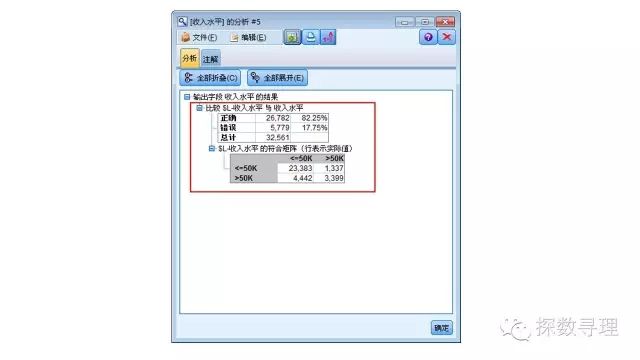
更重要地,对于分类问题,我们同样十分关心模型的预测准确率,为了进行比较,我们在模型节点后添加‘分析’节点(在输出选型卡下),其中勾选‘重合矩阵(用于字符型目标字段)’,点击运行。
通过分析结果,我们可以看到逻辑回归分析的结果还是比较准确地,准确率有82.55%。


公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享

















 5033
5033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









