




 本文探讨了机器学习的基本概念,包括自动找函数、监督学习、强化学习和非监督学习的区别。重点介绍了分类、回归和生成能力,并深入讲解了如何通过梯度下降法寻找最优函数。此外,文章还涵盖了可解释性AI、对抗攻击、网络压缩等前沿研究和课程学习路线,如迁移学习和终身学习。
本文探讨了机器学习的基本概念,包括自动找函数、监督学习、强化学习和非监督学习的区别。重点介绍了分类、回归和生成能力,并深入讲解了如何通过梯度下降法寻找最优函数。此外,文章还涵盖了可解释性AI、对抗攻击、网络压缩等前沿研究和课程学习路线,如迁移学习和终身学习。
1. 基本概念
⚪李宏毅老师眼中机器学习的定义——自动找函数
无论是监督学习、非监督学习、强化学习 都是某种信息或者情境到一种结果的映射
⚪根据函数映射结果的离散性和连续性,可以分为分类和回归问题
classification and regression
⚪在分类和回归之外,更高的要求是有generation的能力
产生新的图片和文字等等
2. 告诉机器要找什么样的函数
监督学习——直接告诉模型要一部分的映射结果,找到loss最低的函数
强化学习——并不指明每一步的错误或正确性,机器由最后的输赢结果来判断自己那些步骤是错误或者正确的
非监督学习——从没有标签的数据中学习(还不太理解,要通过具体的例子)
神经网络实际上就是框定了函数的一个寻找范围,比如线性变换+激活函数
3. 机器怎样找出正确的函数
梯度下降方法
4. 本课程涉及的一些前沿研究
可解释性AI——这张图是猫的理由
对抗攻击(adversarial attack)——如何解决错误的数据
网络压缩(network compression)——简化网络从而简化计算量
非监督学习——自动编码器
异常检测(anomaly detection)——机器如何知道自己是不知道的
迁移学习——不同的数据集的迁移能力
元学习(meta learning)——从程序中学习产生程序的能力
终身学习——不停止学习,不断寻找新的任务
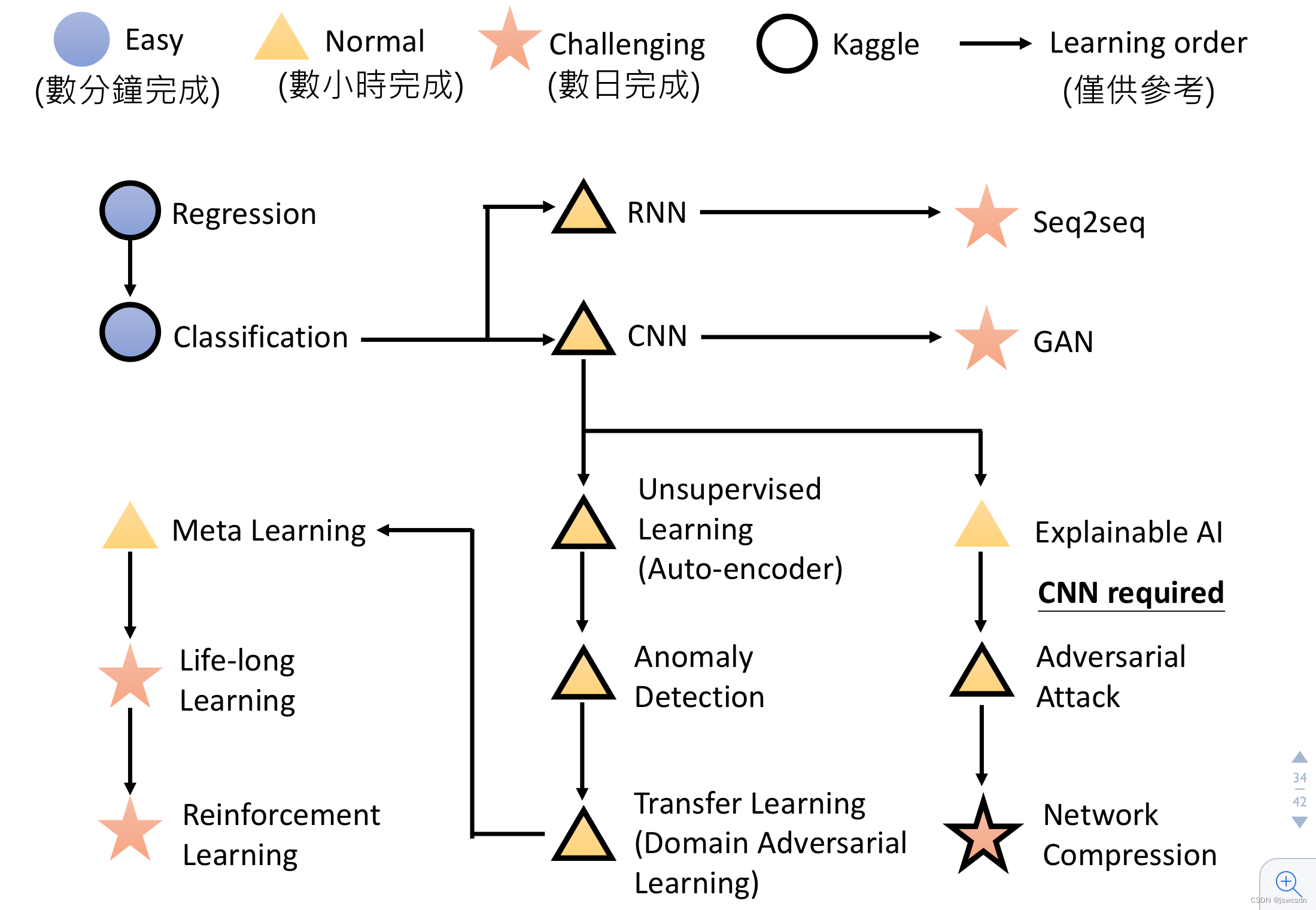
5. 课程安排和学习路线

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









