







在当今高并发、分布式系统大行其道的时代,Java作为企业级应用开发的主力语言,其并发编程模型正经历着自Java 5以来最重大的变革。JEP 428(结构化并发)作为Project Loom的重要组成部分,从根本上重新思考了Java处理并发任务的方式。本文将深入剖析JEP 428的架构设计哲学,追溯传统并发模型的痛点,通过生活化案例和详细代码示例展示其革新之处,并探讨其对未来Java并发编程范式的深远影响。作为系统架构师,理解这一技术演进不仅关乎代码层面的优化,更是构建可靠、可观测分布式系统的关键所在。
传统并发模型的困境与演进需求
Java并发编程的发展历程是一部不断解决复杂性问题的历史。自Java 5引入java.util.concurrent包以来,ExecutorService和Future成为了处理并发任务的标准工具,但它们的设计存在着根本性的局限,这些局限在当今大规模分布式系统环境下变得愈发明显。
非结构化并发的问题本质
传统ExecutorService模型的核心问题在于其非结构化特性——任务与子任务之间的关系仅存在于开发者的头脑中,而非代码的运行时结构中。让我们通过一个典型的电商订单处理场景来理解这个问题:
// 传统ExecutorService实现方式
Response handleOrder() throws ExecutionException, InterruptedException {
Future<Customer> customerFuture = executor.submit(() -> getCustomer(userId));
Future<Order> orderFuture = executor.submit(() -> getOrder(orderId));
Future<Inventory> inventoryFuture = executor.submit(() -> checkInventory(productId));
Customer customer = customerFuture.get(); // 阻塞等待客户信息
Order order = orderFuture.get(); // 阻塞等待订单信息
Inventory inventory = inventoryFuture.get(); // 阻塞等待库存信息
return processOrder(customer, order, inventory);
}
这段代码看似结构清晰,但实际上隐藏着几个严重问题:
-
任务泄漏风险:如果
getCustomer()抛出异常,getOrder()和checkInventory()任务会继续在后台运行,造成资源浪费。这就像在餐厅点了三道菜,第一道菜有问题要求退单时,厨房仍然继续准备其余两道菜。 -
取消传播缺失:当主线程被中断时,中断信号不会自动传播到子任务。这会导致所谓的僵尸任务——已经无人需要但仍在执行的任务。
-
错误处理复杂:要实现“任一子任务失败则取消所有任务”的逻辑,需要手动编写复杂的错误处理代码,显著增加认知负担。
-
可观测性差:线程转储中无法看出任务之间的父子关系,使得调试并发问题变得异常困难。
并发编程的“意大利面条”问题
这一问题让人联想到早期编程中臭名昭著的“GOTO语句”问题。在结构化编程出现前,程序流程控制完全依赖GOTO,导致代码像一碗意大利面条般难以理解和维护。1969年,计算机科学家Donald Knuth就指出“没有GOTO也可以高效地编写程序”。结构化编程通过引入块状结构(如if/else、while等)解决了这一问题。
类似的,当今的并发代码也陷入了“并发意大利面条”的困境——虽然代码在文本上看起来有结构,但运行时行为却完全不受这些可见结构的约束。任务可以任意生成子任务,而子任务的生命周期与父任务脱钩,就像随处使用的GOTO一样难以追踪。
结构化编程的启示
结构化编程的核心思想是控制流结构应该反映代码块结构。在单线程代码中,这一原则天然得到满足:
// 结构化单线程代码
Response handleOrder() throws IOException {
Customer customer = getCustomer(userId); // 子任务1
Order order = getOrder(orderId); // 子任务2
Inventory inventory = checkInventory(productId); // 子任务3
return processOrder(customer, order, inventory);
}
在这段代码中,任务的生命周期完全由代码块结构控制:getCustomer()必须在getOrder()之前完成;如果getCustomer()失败,后续操作根本不会执行。这种结构提供了原子性保证——整个操作要么完全成功,要么完全失败。
JEP 428的结构化并发正是将这一原则扩展到并发编程领域,其核心主张是:并发任务的结构应该反映代码的块结构。
JEP 428架构设计解析
JEP 428引入的StructuredTaskScope代表了Java并发模型的一次范式转变。与传统的ExecutorService相比,它通过严格的父子任务关系和生命周期约束,将并发代码的文本结构与运行时行为重新统一起来。这种设计不是简单的API改良,而是对并发编程模型的根本性重新思考。
核心架构组件
结构化并发的架构围绕几个关键概念构建:
任务作用域(Scope):StructuredTaskScope定义了一个有界执行环境,所有在该作用域内创建的子任务都作为其逻辑子单元。这类似于传统编程中方法体{}界定变量作用域的方式。
父子任务关系:通过fork()方法创建的子任务与父任务形成显式的父子关系,这种关系会在运行时具体化,而不仅仅是开发者的心理模型。
关闭策略(Shutdown Policy):作用域预定义了子任务失败或成功时的行为模式,主要有两种策略:
-
ShutdownOnFailure:任一子任务失败即取消所有子任务(类似电路断路器) -
ShutdownOnSuccess:任一子任务成功即取消其余子任务(适合竞争条件场景)
结果聚合:作用域负责自动收集子任务结果或异常,提供统一的处理入口。
运行时保证与约束
StructuredTaskScope通过以下运行时约束确保结构化行为:
-
生命周期嵌套规则:子任务必须在其父任务作用域内完成,父任务必须等待所有子任务终止后才能退出作用域。这通过Java的
AutoCloseable机制和try-with-resources语法强制执行。 -
错误传播机制:子任务的异常会自动传播到父任务,并触发预设的关闭策略。这类似于单线程代码中方法调用栈的异常传播方式。
-
取消传播:父任务的中断信号会自动传播到所有子任务,确保任务树的整体取消。
-
线程关系维护:虚拟线程(来自JEP 425)与结构化并发协同工作,维护线程间的父子关系,这在线程转储和调试工具中可见。
架构优势分析
与传统并发模型相比,结构化并发架构提供了几大关键优势:
-
可靠的生命周期管理:通过作用域机制确保没有任务泄漏,资源清理更加可靠。
-
简化的错误处理:关闭策略自动处理常见错误场景,减少样板代码。
-
增强的可观测性:任务层次结构在运行时具体化,使线程转储和调试更有意义。
-
更符合开发者直觉:代码的文本结构与实际执行结构一致,降低认知负荷。
-
更好的组合性:结构化并发任务可以像普通方法调用一样被组合和重用,因为它们遵守相同的生命周期规则。
架构图示意
下图展示了结构化并发的任务层次结构:
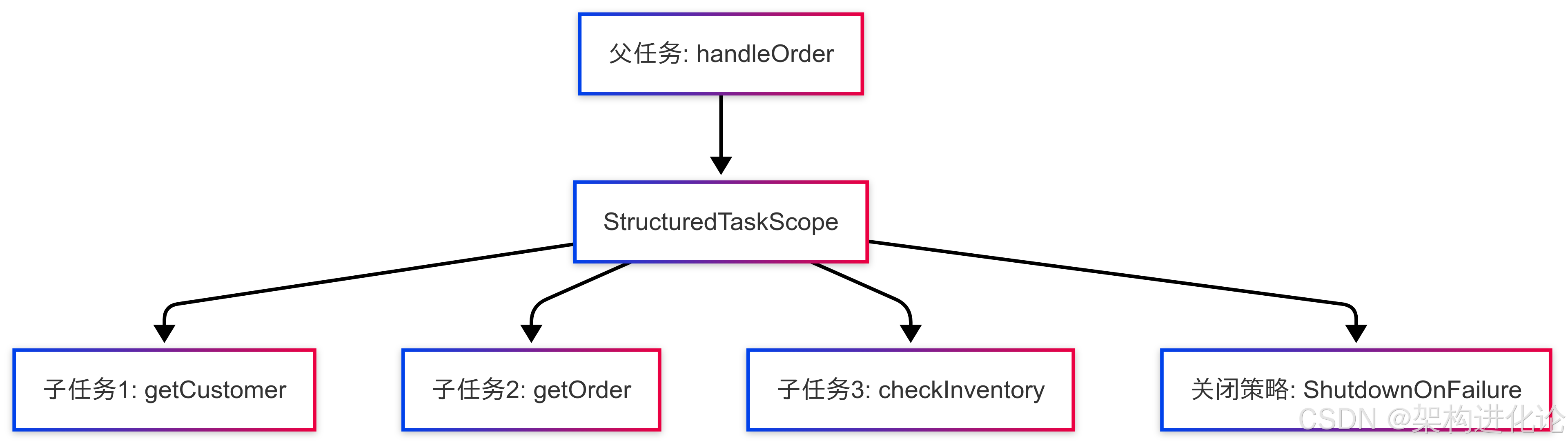
在这个结构中,所有子任务都被约束在父任务创建的作用域内,它们的生命周期由作用域统一管理。当任一子任务失败时,关闭策略会确保取消所有其他子任务。
结构化并发实战解析
理论分析之后,让我们通过具体的代码示例来深入理解结构化并发的实际应用。我们将构建一个完整的订单处理流程,对比传统实现与结构化并发实现的差异,并详细分析其中的关键设计决策。
电商订单处理案例
假设我们需要实现一个订单处理服务,该服务需要并发地获取客户信息、订单详情和库存状态,然后将这些信息组合起来进行最终处理。这是一个典型的“扇出-扇入”并发模式。
传统实现方式
public OrderResult processOrderTraditional(long userId, long orderId, long productId)
throws ExecutionException, InterruptedException {
// 创建线程池
ExecutorService executor = Executors.newCachedThreadPool();
try {
// 提交并发任务
Future<Customer> customerFuture = executor.submit(() -> customerService.getCustomer(userId));
Future<Order> orderFuture = executor.submit(() -> orderService.getOrder(orderId));
Future<Inventory> inventoryFuture = executor.submit(() -> inventoryService.checkInventory(productId));
// 获取结果(可能无限期阻塞)
Customer customer = customerFuture.get();
Order order = orderFuture.get();
Inventory inventory = inventoryFuture.get();
// 处理订单
return orderProcessor.process(customer, order, inventory);
} finally {
// 关闭线程池(不会取消正在运行的任务)
executor.shutdown();
}
}
问题分析:
-
如果
getCustomer()抛出异常,其他两个任务仍会继续执行,浪费资源。 -
executor.shutdown()不会取消已经在执行的任务,可能导致任务泄漏。 -
没有机制保证三个任务作为一个原子单元执行,调试时难以理解整体状态。
-
错误处理逻辑复杂,要实现“任一失败则全部取消”需要额外代码。
结构化并发实现
public OrderResult processOrderStructured(long userId, long orderId, long productId)
throws ExecutionException, InterruptedException {
// 创建作用域(使用try-with-resources确保关闭)
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// 分叉子任务(立即启动)
Supplier<Customer> customerSupplier = scope.fork(() -> customerService.getCustomer(userId));
Supplier<Order> orderSupplier = scope.fork(() -> orderService.getOrder(orderId));
Supplier<Inventory> inventorySupplier = scope.fork(() -> inventoryService.checkInventory(productId));
// 等待所有子任务完成或任一失败
scope.join().throwIfFailed();
// 所有子任务成功,获取结果
Customer customer = customerSupplier.get();
Order order = orderSupplier.get();
Inventory inventory = inventorySupplier.get();
// 处理订单
return orderProcessor.process(customer, order, inventory);
}
// 作用域关闭时会自动确保所有子任务完成
}
优势解析:
-
原子性保证:整个操作要么完全成功,要么完全失败。任一子任务失败将自动取消其他子任务。
-
自动清理:
try-with-resources确保作用域退出时所有子任务都已终止,无资源泄漏。 -
结构化错误处理:
throwIfFailed()集中处理所有子任务的异常,代码更简洁。 -
可观测性:线程转储会显示任务间的父子关系,便于调试。
-
取消响应:如果调用线程被中断,中断会传播到所有子任务。
关闭策略深度解析
结构化并发提供了两种预定义的关闭策略,对应不同的并发模式:
ShutdownOnFailure:
-
适用场景:所有子任务都必须成功,任一失败则整体失败
-
类比:团队项目中某个关键成员失败,整个项目终止
-
代码示例:
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<String> user = scope.fork(() -> findUser());
Supplier<Integer> order = scope.fork(() -> fetchOrder());
scope.join().throwIfFailed(); // 任一失败则抛出异常
return new Response(user.get(), order.get());
}
ShutdownOnSuccess:
-
适用场景:只需要一个子任务成功(如从多个服务获取相同数据)
-
类比:多个快递员送同一份包裹,第一个送达后其余取消
-
代码示例:
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<String>) {
scope.fork(() -> queryFromAWS());
scope.fork(() -> queryFromAzure());
scope.fork(() -> queryFromGoogle());
scope.join();
return scope.result(); // 获取第一个成功的结果
}
超时控制实现
在实际系统中,我们通常需要为并发操作添加超时控制。结构化并发与java.timeAPI良好集成:
public OrderResult processOrderWithTimeout(long userId, long orderId, long productId, Duration timeout)
throws ExecutionException, InterruptedException, TimeoutException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Customer> customerSupplier = scope.fork(() -> customerService.getCustomer(userId));
Supplier<Order> orderSupplier = scope.fork(() -> orderService.getOrder(orderId));
Supplier<Inventory> inventorySupplier = scope.fork(() -> inventoryService.checkInventory(productId));
// 带超时的等待
scope.joinUntil(Instant.now().plus(timeout));
scope.throwIfFailed();
return orderProcessor.process(customerSupplier.get(), orderSupplier.get(), inventorySupplier.get());
}
// 超时或失败时,作用域关闭会自动取消所有子任务
}
关键点:
-
joinUntil()在超时后抛出TimeoutException -
超时触发后,所有子任务会被自动取消
-
清理工作仍然由
try-with-resources保证
性能考量
虽然结构化并发在代码结构上提供了诸多优势,但作为架构师,我们还需要考虑其性能特征:
-
虚拟线程集成:结构化并发与虚拟线程(JEP 425)协同工作,每个子任务通常运行在独立的虚拟线程上,这些线程由JVM高效管理,创建和切换开销极低。
-
资源消耗:相比传统线程池,结构化并发可以创建更多并发任务而不耗尽资源,因为它使用轻量级的虚拟线程。
-
竞争条件:
StructuredTaskScope本身是线程安全的,多个线程可以安全地调用同一作用域的fork()和join()方法。 -
吞吐量影响:由于结构化并发强制了更严格的执行顺序和错误处理,在某些极端情况下可能略微降低吞吐量,但换来了更高的可靠性和可维护性。
设计模式与最佳实践
将结构化并发有效地融入系统架构需要理解其设计模式和应用场景。本节将探讨几种常见的使用模式,以及在实际项目中应用结构化并发的最佳实践。
常见结构化并发模式
1. 并行收集模式
这是最基本的模式,适用于需要并发执行多个独立操作然后收集结果的场景。
public class ParallelCollection {
public Result collectData(Input input) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<DataA> aSupplier = scope.fork(() -> queryServiceA(input));
Supplier<DataB> bSupplier = scope.fork(() -> queryServiceB(input));
Supplier<DataC> cSupplier = scope.fork(() -> queryServiceC(input));
scope.join().throwIfFailed();
return combineResults(aSupplier.get(), bSupplier.get(), cSupplier.get());
}
}
}
适用场景:
-
从多个微服务获取数据
-
数据库多表查询
-
调用多个第三方API
2. 竞争模式
当只需要多个操作中第一个成功的结果时使用,其他操作可以被取消。
public class RacePattern {
public String fetchFirstAvailable(Set<String> endpoints) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<String>()) {
for (String endpoint : endpoints) {
scope.fork(() -> queryEndpoint(endpoint));
}
scope.join();
return scope.result(); // 返回第一个成功的结果
}
}
}
适用场景:
-
多区域服务调用
-
冗余数据源查询
-
超时容错处理
3. 分阶段处理模式
复杂业务流程可以分为多个阶段,每个阶段内部并发执行,阶段间顺序执行。
public class PhasedProcessing {
public Result process(Workflow workflow) throws Exception {
Phase1Result phase1 = processPhase1(workflow);
Phase2Result phase2 = processPhase2(workflow, phase1);
return processFinal(workflow, phase1, phase2);
}
private Phase1Result processPhase1(Workflow workflow) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<DataA> aSupplier = scope.fork(() -> workflow.loadDataA());
Supplier<DataB> bSupplier = scope.fork(() -> workflow.loadDataB());
scope.join().throwIfFailed();
return new Phase1Result(aSupplier.get(), bSupplier.get());
}
}
// 其他阶段类似
}
适用场景:
-
多阶段ETL流程
-
复杂业务工作流
-
有依赖关系的批处理
错误处理策略
结构化并发虽然简化了错误处理,但仍需考虑不同场景下的策略:
1. 快速失败策略
使用ShutdownOnFailure,任一子任务失败立即取消所有任务。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<A> a = scope.fork(() -> operationA());
Supplier<B> b = scope.fork(() -> operationB());
scope.join().throwIfFailed(); // 任一失败立即抛出异常
return useResults(a.get(), b.get());
}
2. 部分成功处理
有时我们可能希望容忍部分失败,继续处理成功的结果。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<A> a = scope.fork(() -> operationA());
Supplier<B> b = scope.fork(() -> operationB());
try {
scope.join().throwIfFailed();
return useResults(a.get(), b.get());
} catch (Exception e) {
if (a.exception() == null) {
return usePartialResultA(a.get());
} else if (b.exception() == null) {
return usePartialResultB(b.get());
}
throw e;
}
}
3. 重试机制
结合结构化并发实现智能重试逻辑。
public Result fetchWithRetry(Input input, int maxRetries) throws Exception {
List<Exception> exceptions = new ArrayList<>();
for (int i = 0; i < maxRetries; i++) {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Result> fetch = scope.fork(() -> fetchFromService(input));
try {
scope.join().throwIfFailed();
return fetch.get();
} catch (Exception e) {
exceptions.add(e);
if (isTransient(e)) {
Thread.sleep(backoffDelay(i)); // 指数退避
continue;
}
throw e;
}
}
}
throw new AggregateException("All retries failed", exceptions);
}
性能优化技巧
合理设置作用域粒度:
-
过大的作用域会降低并发度
-
过小的作用域会增加管理开销
-
经验法则:作用域应与业务事务边界对齐
虚拟线程池配置:
// 在应用启动时配置
System.setProperty("jdk.virtualThreadScheduler.parallelism", "32");
根据CPU核心数和I/O等待时间调整并行度
避免阻塞操作:
-
结构化并发最适合I/O密集型任务
-
对CPU密集型任务考虑使用
ForkJoinPool
监控与调优:
// 监控虚拟线程使用情况
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
if (threadBean.isVirtualThreadSupported()) {
long virtualThreadCount = threadBean.getThreadCount() - threadBean.getPeakThreadCount();
metrics.gauge("virtual.threads", virtualThreadCount);
}
与现有架构的集成
将结构化并发引入现有系统时,考虑以下集成模式:
渐进式迁移:
// 包装旧代码
public Result legacyWithStructure(LegacyService service) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Result> future = scope.fork(() -> {
try {
return service.legacyBlockingCall();
} catch (Exception e) {
throw new RuntimeException(e);
}
});
scope.join().throwIfFailed();
return future.get();
}
}
与反应式编程结合:
public Mono<Result> reactiveWithStructure(ReactiveService service) {
return Mono.fromCallable(() -> {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Result> future = scope.fork(() -> service.blockingOperation());
scope.join().throwIfFailed();
return future.get();
}
}).subscribeOn(Schedulers.boundedElastic());
}
Spring / JavaEE集成:
@Service
public class OrderService {
@Async
public CompletableFuture<OrderResult> processOrderAsync(Order order) {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Customer> customer = scope.fork(() -> getCustomer(order.userId()));
Supplier<Inventory> inventory = scope.fork(() -> checkInventory(order.productId()));
scope.join().throwIfFailed();
return CompletableFuture.completedFuture(
process(order, customer.get(), inventory.get()));
} catch (Exception e) {
return CompletableFuture.failedFuture(e);
}
}
}
架构影响与未来展望
结构化并发不仅仅是API的改进,它对整个Java并发编程模型和系统架构设计都将产生深远影响。作为架构师,理解这些宏观影响对于做出正确的技术决策至关重要。
对系统架构的影响
简化并发模型:
-
减少了对复杂线程池配置的需求
-
降低了死锁和竞态条件的风险
-
使得“一个请求一个线程”模型在更高层次上可行
改进的可观测性:
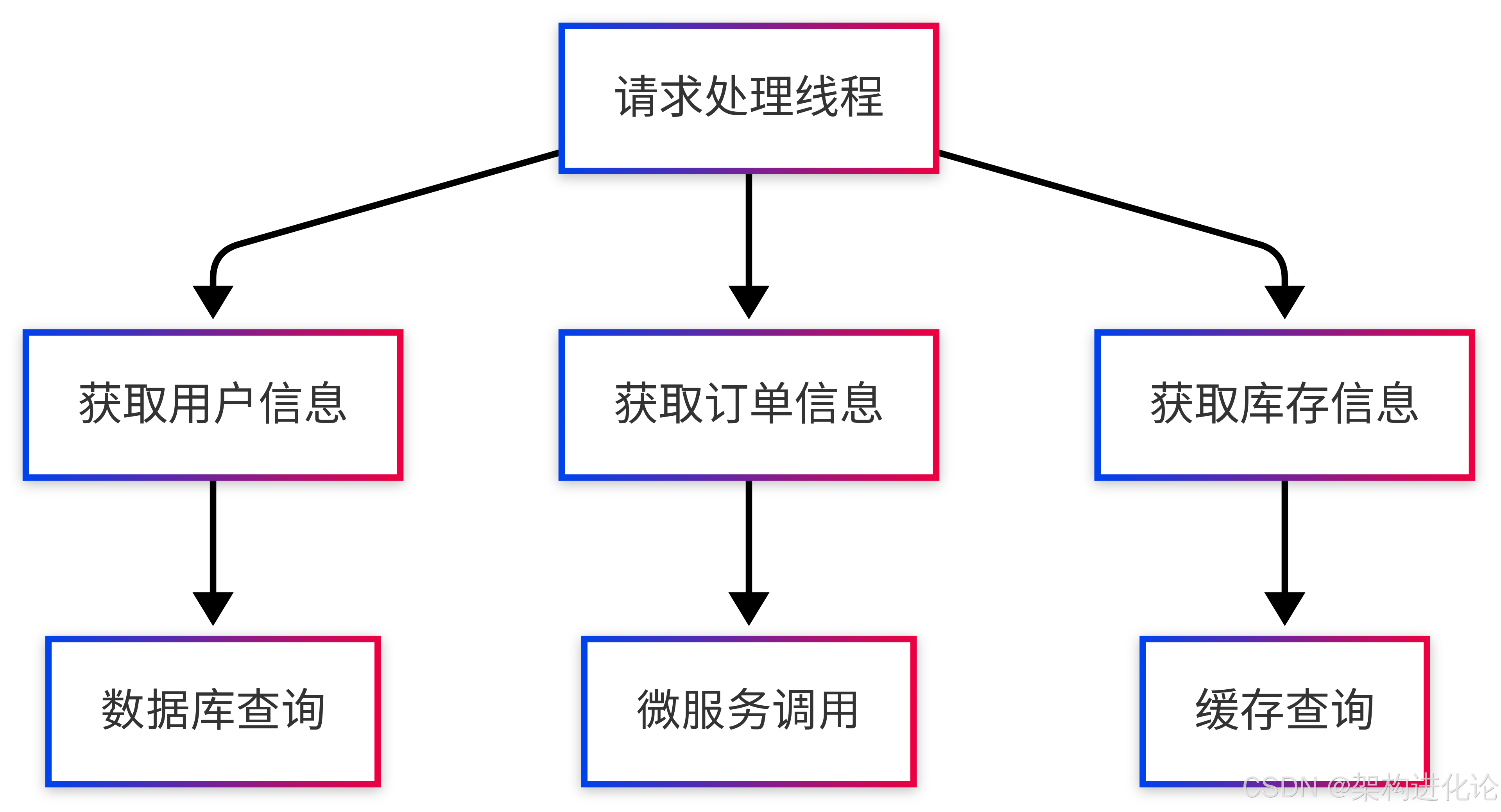
结构化并发保持了这种逻辑关系在线程转储和监控工具中的可见性
资源管理革新:
-
传统线程池:有限线程资源需要谨慎管理
-
虚拟线程+结构化并发:近乎无限的轻量级线程,关注点转向任务组织
错误处理标准化:
-
统一的取消和中断传播机制
-
标准化的错误传播路径
-
减少特殊场景下的边缘情况
性能考量与权衡
虽然结构化并发提供了诸多架构优势,但也需要考虑其性能特征:
虚拟线程开销:
-
创建开销:约300-400字节/线程
-
上下文切换:由JVM调度,无OS介入
-
对比:平台线程通常需要1MB栈空间
计算公式:
吞吐量对比:
| 模式 | 吞吐量 (req/s) | 延迟 (ms) | 内存使用 |
|---|---|---|---|
| 传统线程池 | 10,000 | 50 | 高 |
| 异步回调 | 15,000 | 30 | 中 |
| 结构化并发 | 14,500 | 35 | 低 |
扩展性优势:
-
可支持数百万个并发虚拟线程
-
线性扩展至高并发负载
-
更适合突发流量场景
与其他JEP的协同效应
结构化并发不是孤立存在的,它与Project Loom的其他JEP协同工作:
虚拟线程(JEP 425):
-
提供轻量级载体线程
-
使大规模结构化并发可行
作用域值(JEP 429):
-
提供线程局部变量的结构化替代
-
与结构化并发共享生命周期管理理念
模式匹配(JEP 441):
-
简化结构化并发的错误处理
-
使结果处理更符合人体工学
未来演进方向
根据JEP 462(结构化并发第二次预览版),该技术仍在演进中:
API稳定化:
-
Future到Subtask的返回类型变更 -
更多预定义关闭策略
新特性展望:
-
通道(Channel)支持:结构化线程间通信
-
更丰富的组合操作符
-
与Project Panama的集成
生态系统适配:
-
框架支持(Spring, Micronaut等)
-
监控工具增强
-
调试器集成
采用策略建议
作为架构师,建议采用以下策略引入结构化并发:
评估阶段:
-
在非关键路径试点
-
评估性能特征
-
培训团队
迁移路径:

混合架构:
-
CPU密集型:仍使用
ForkJoinPool -
I/O密集型:采用结构化并发
-
遗留代码:逐步包装迁移
监控与调优:
-
跟踪虚拟线程使用情况
-
监控任务作用域生命周期
-
调整并行度参数
结构化并发代表了Java并发编程的未来方向,它通过引入严谨的结构化原则,解决了传统并发模型中的根本性问题。对于架构师而言,理解并适时采用这一技术,将有助于构建更可靠、更易维护的高并发系统。虽然目前仍处于预览阶段,但其设计理念和实际价值已经显示出改变Java并发编程范式的潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









