



 本文基于Julian等人2020年的研究,详细解析Muzero算法,该算法无需预先了解游戏规则,仅需知道合法动作即可推演致胜策略。报告涵盖Muzero模型的构成、MCTS搜索策略及学习过程。Muzero学习包括自我对弈生成数据和训练神经网络,采用Monte Carlo Tree Search进行决策,并通过特定损失函数优化。
本文基于Julian等人2020年的研究,详细解析Muzero算法,该算法无需预先了解游戏规则,仅需知道合法动作即可推演致胜策略。报告涵盖Muzero模型的构成、MCTS搜索策略及学习过程。Muzero学习包括自我对弈生成数据和训练神经网络,采用Monte Carlo Tree Search进行决策,并通过特定损失函数优化。
面试的时候被要求了解muzero相关算法,本文根据Julian 等人在2020年发表的”Mastering Atari, Go, Chess and Shogi by Planning with a Learned Mode” 一文,研读并汇报了文中的Muzero算法。相对于Alpha zero, Muzero无需预先了解游戏的游戏规则,比如在棋盘游戏中,只需要去告知哪一步的移动是被允许的,就可以自主去推演出致胜的策略。报告主要分为三个部分,分别介绍了Muzero 的模型组成,Muzero搜索策略以及学习训练过程。
Muzero模型组成
Muzero model包含planning, acting, training三个部分,分别对应prediction function,dynamics function和representation function, 各个function的输入输出关系如下表。
| Function name | Input | Output |
| prediction | current hidden state
| current policy, current value function
|
| dynamics | Previous hidden state, current candidate action
| current immediate reward, current hidden state |
| representation | all observations | initial hidden state s0
|
首先representation function根据初始情况的观察,产生初始的隐藏状态S0,S0作为prediction function的输入,生成当前的策略p和价值v。同时S0也作为dynamics function的输入,加上当前的行动,通过dynamics function生成下一步隐藏状态S1及奖励。然后继续使用prediction函数去对S1进行预测。
如下图所示,其中f表示prediction function,h表示representation function,g表示dynamics function,左边的initial_inference表示了初始状态,在初始状态中,通过h函数得到初始隐藏状态,然后用f函数计算出policy和value。在之后的行动中便可以使用g函数去计算下一个隐藏状态,见图右recurrent_inference。
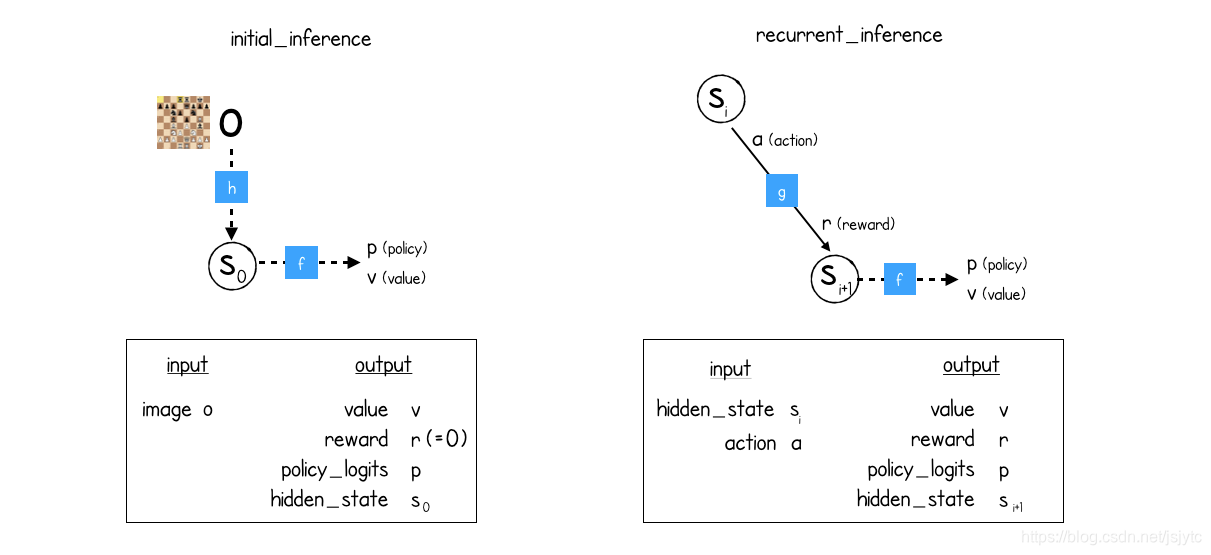
下一部分主要介绍这三个function是如何协作来产生策略的。
Muzero search - Monte Carlo Tree Search (MCTS)
首先,每一个游戏都会有一个初始的界面,然后通过MCTS来去生成下一步的移动直到游戏结束或到达最大步数。树中的每一个节点都会存储一些相关参数,包括被访问的次数,轮次,上一步动作的概率,子节点以及是否有所对应的隐藏状态和奖励。
游戏开始时,首先从根节点出发,算法会使用上一个章节提到的representation function对根节点进行合法的expand,如开头所说,虽然Muzero不知道游戏规则,但是它知道哪一步是可以走的。为了决定下一个action,MCTS会一直从根节点去进行搜索和遍历直到到达未被探索的叶子结点,之后进行反向传播。在遍历的过程中,MCTS会通过UCB公式去评分,选择得分最高的action。UCB公式如下,对于每一个源自状态s的行动a,都会有一个对应的边(s,a),其中N表示被访问的次数,Q表示平均价值,P表示策略,R表示奖励,S表示状态。
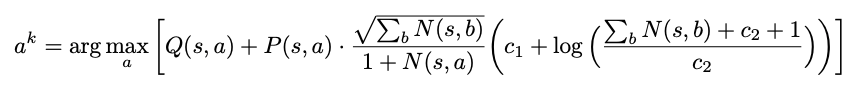
公式 1 UCB公式
为了决定一个动作,算法会运行N次模拟,通过MCTS来去生成下一步的移动直到游戏结束或到达最大步数,当MCTS模拟结束时,将预测的值反向传播到根节点上。
最后基于节点被访问的次数去选择action。对于从根节点选择action的概率,使用温度参数T去计算。对于前固定值(比如50)个动作,T设置为1,从第50步开始,T会逐渐衰减,从而确保访问最多边的action被选中。
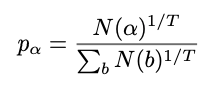
公式 2 从根节点计算选择动作alpha的概率
3.Muzero learning
Muzero learning包含self-play和training,self-play用于生成游戏数据,training用来生成最新版本的神经网络。
3.1生成训练数据
代码中包含了sharedstorge和replaybuffer两个对象。sharedstorge用来保存最新版本的神经网络,replaybuffer用来存储游戏数据。replaybuffer中包含了生成训练数据的功能,举一个例子,在象棋游戏中,batch size是2048,每一个batch包含了三个部分,分别是所选位置的observation,actions,价值奖励以及策略的target。
3.2更新神经网络权重
对于初始状态,使用前文说过的initial_inference得到初始隐藏状态,然后用f函数计算出policy和value,并与目标进行比较。在之后的行动中便可以使用g函数去计算下一个隐藏状态,然后用f函数计算出policy和value,并与目标进行比较。在预测过程中将使用到三个函数对应的三个神经网络并更新相对应神经网络的权重。
3.3损失函数
损失函数包含三个目标。分别是实际的奖励和预测的奖励之间的差异、实际的价值和预测的价值之间的差异以及实际的策略和预测的策略之间的差异。公式如下图,其中K是整数,表示num_unroll_steps,即每次训练中observation选择的action个数。T表示回合数。
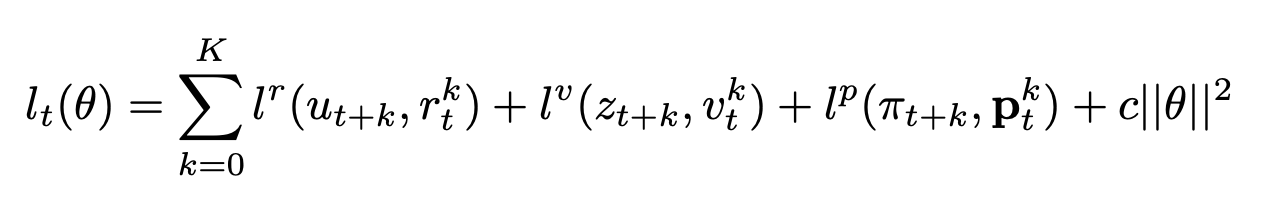
muzero伪代码 https://arxiv.org/src/1911.08265v1/anc/pseudocode.py
muzero伪代码讲解博客https://medium.com/applied-data-science/how-to-build-your-own-muzero-in-python-f77d5718061a

















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









