




在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。

据介绍,在 Backwell 上,FlashAttention-4 的速度比英伟达 cuDNN 库中的注意力核实现快可达 22%!
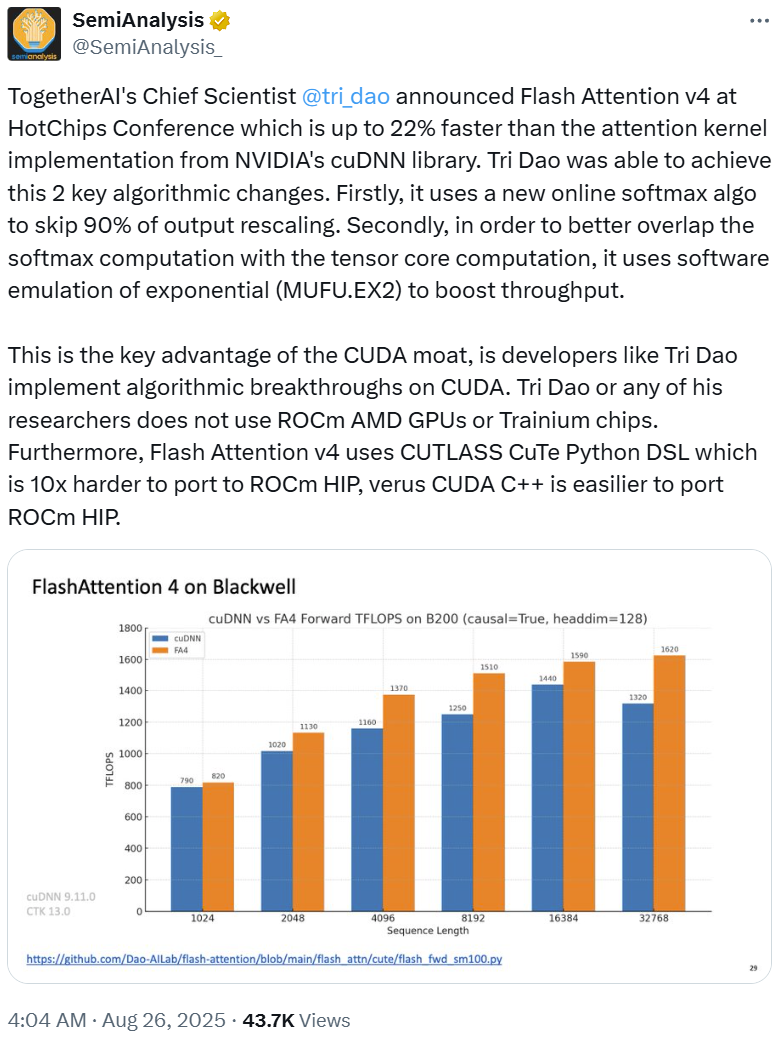
在这个新版本的 FlashAttention 中,Tri Dao 团队实现了两项关键的算法改进。
一、它使用了一种新的在线 softmax 算法,可跳过了 90% 的输出 rescaling。
二、为了更好地将 softmax 计算与张量核计算重叠,它使用了指数 (MUFU.EX2) 的软件模拟来提高吞吐量。
此外,FlashAttention-4 使用的是 CUTLASS CuTe Python DSL,其移植到 ROCm HIP 的难度要高出 10 倍,而 CUDA C++ 移植到 ROCm HIP 则更容易。
有意思的是,Tri Dao 还宣布,在执行 A@B+C 计算时,对于 Blackwell 上在归约维度 K 较小的计算场景中,他使用 CUTLASS CuTe-DSL 编写的核(kernel)比英伟达最新的 cuBLAS 13.0 库快不少。而在标准矩阵算法 A@B 时,两者速度总体是相当的。

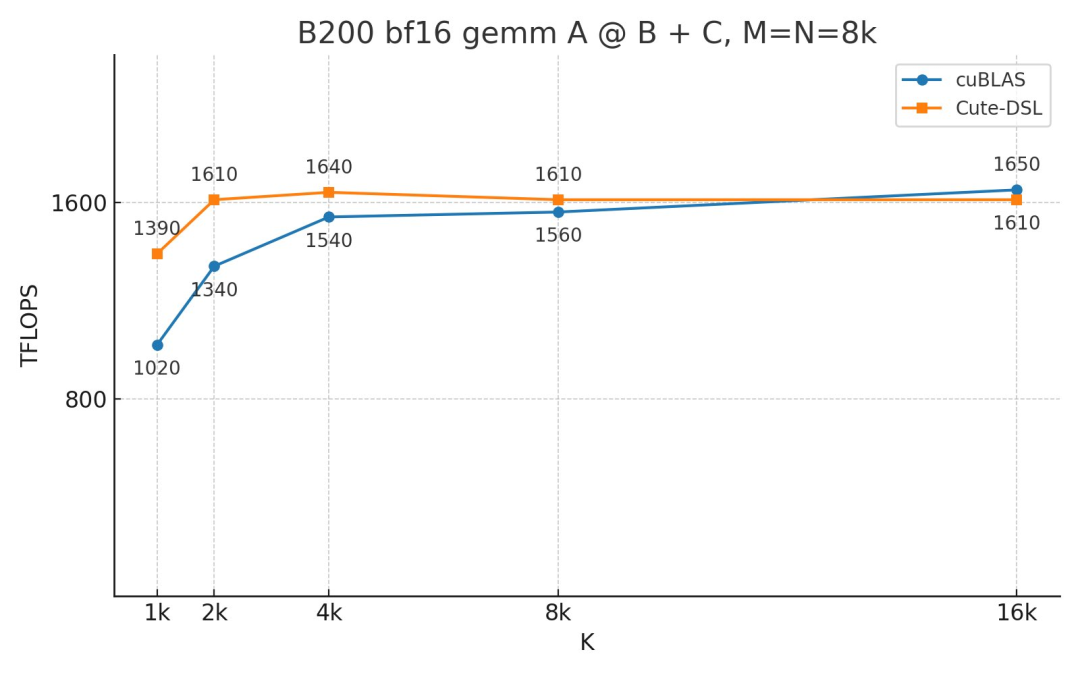
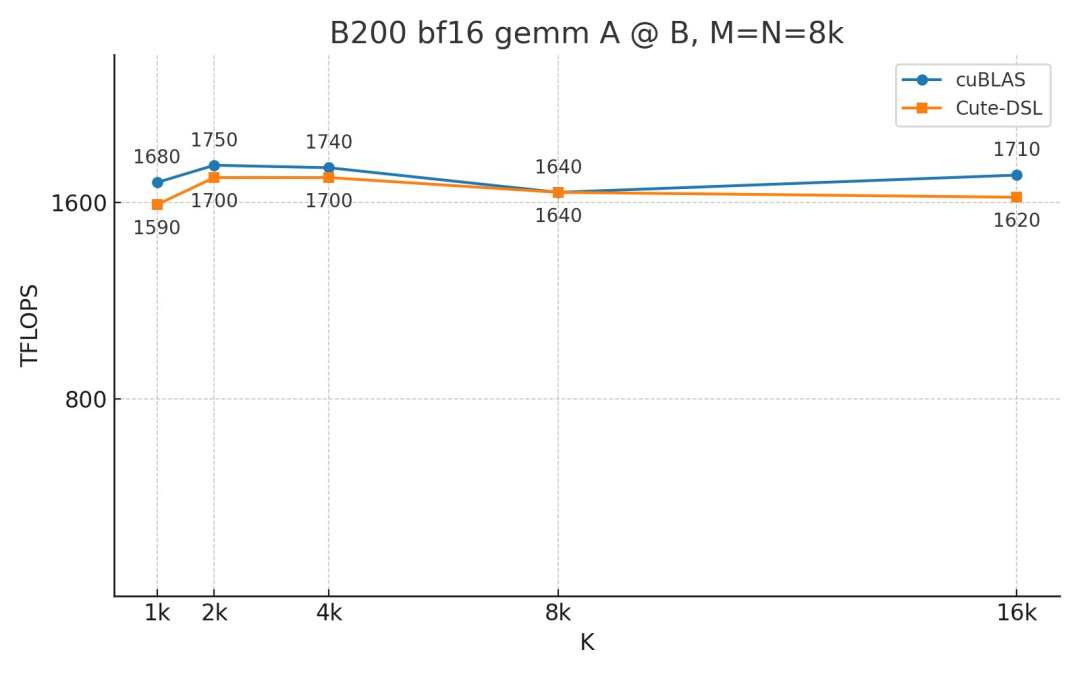
据介绍,他的核通过使用两个累积缓冲区来重叠 epilogue,从而击败了 cuBLAS。
Semi Analysis 表示,像 Tri Dao 这样的开发者是 CUDA 护城河的核心优势之一,因为 Tri Dao 只使用英伟达 GPU,并将其大部分核开源给其他英伟达开发者群体。Tri Dao 等研究者均不使用 ROCm AMD GPU 或 Trainium 芯片。
这对于 AMD 等来说可不是好消息,假如 AMD 希望 Tri Dao 和他的团队在 ROCm 上实现算法突破。那么,它就应该为 TogetherAI GPU 云服务上的 AMD GPU 提供优惠支持。Semi Analysis 分析说:「谷歌为 Noam Shazeer 支付了 27 亿美元,Zucc 为 OpenAI 工程师支付了 1 亿美元,AMD 拥有足够的现金,可以为 TogetherAI/Tri Dao 支付 5000 万美元来启动 ROCm 生态系统。」
FlashAttention 最早由 Tri Dao 等人在 2022 年提出,论文标题为《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》。

论文地址:https://arxiv.org/pdf/2205.14135
其背景是传统的注意力机制因需生成 N×N 的注意力矩阵,在序列长度 N 增长时引发二次的(quadratic)时间和内存开销。
而 FlashAttention 强调「IO-awareness」,不再将注意力矩阵完整载入,而是通过「tiling+softmax rescaling」策略,将数据块临时存入高速缓存(SRAM),在内部积累,再写回高带宽内存(HBM),避免了大量读写开销,内存复杂度得到显著降低 —— 从 O (N²) 降至 O (N)。
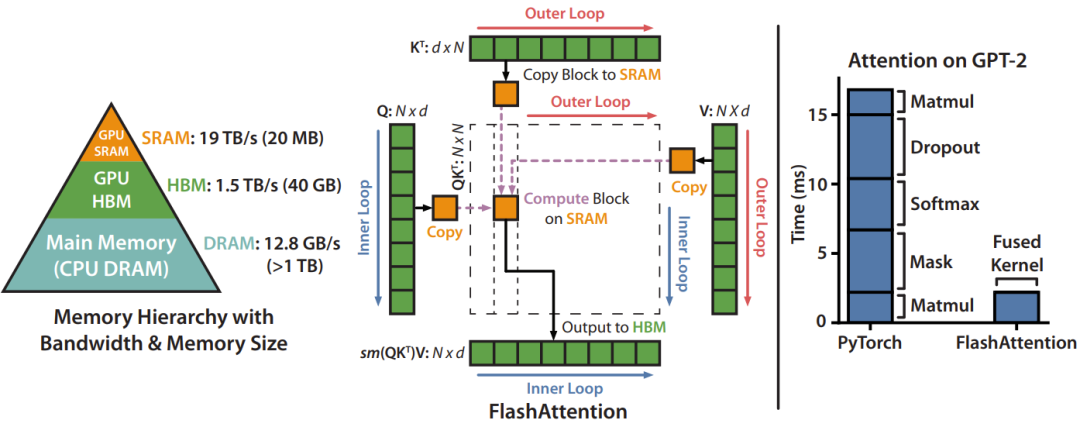
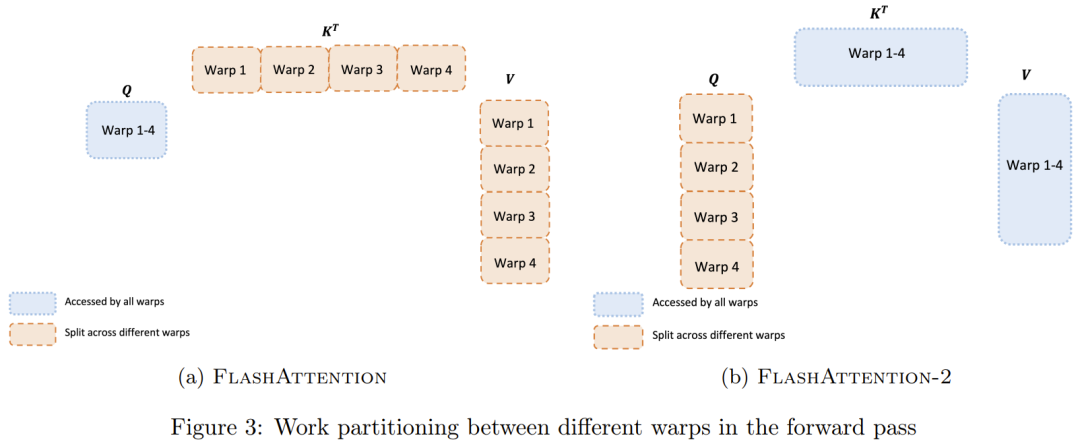
如图所示,在左图中,FlashAttention 使用了 tiling 技术来防止在(相对较慢的)GPU HBM 上执行很大的 𝑁 × 𝑁 注意力矩阵(虚线框)。在外层循环(红色箭头)中,FlashAttention 循环遍历 K 和 V 矩阵的块,并将其加载到快速片上 SRAM 中。在每个块中,FlashAttention 循环遍历 Q 矩阵的块(蓝色箭头),将其加载到 SRAM 中,并将注意力计算的输出写回 HBM。
在右图中,可以看到相比 GPT-2 上 PyTorch 注意力实现,FlashAttention 速度更快 ——FlashAttention 无需将大型 𝑁 × 𝑁 注意力矩阵读写到 HBM,从而将注意力计算速度提升了 7.6 倍。
整体上,初代 FlashAttention 带来的增益也很显著:在 BERT-large(序列长度 512)中相比 MLPerf 基线提升训练速度约 15%;GPT-2(序列长度 1K)提升约 3 倍;在 Long-Range Arena(序列长度 1K–4K)提升约 2.4 倍。
一年后,FlashAttention-2 问世,这一次,作者仅 Tri Dao 一人。顺带一提,他还在这一年的晚些时候与 Albert Gu 共同提出了 Mamba。

论文地址:https://arxiv.org/pdf/2307.08691
其改进的焦点是:FlashAttention 已显著提升性能,但在 GPU 上仍存在低吞吐率的问题,仅能达到理论峰值很低的比例(约 25–40%)。
为此,Tri Dao 提出的解决策略包括:
-
工作划分优化:重新设计分块策略与线程分配,提升并行效率,增加硬件利用率;
-
减少非矩阵运算,加快整体执行;
-
支持更大 head size(至 256) 及多查询注意力(MQA) 和分组查询注意力(GQA),适配更多模型架构需求。
结果,相比初代 FlashAttention,FlashAttention-2 速度提高约 2–4×;在 A100 GPU 上 FP16/BF16 可达到高至 230 TFLOPs/s,达 PyTorch 标准实现 9 倍速度提升。参阅机器之心报道《比标准 Attention 提速 5-9 倍,大模型都在用的 FlashAttention v2 来了》。
又一年,FlashAttention-3 诞生,这一次改进的重点是适配 Hopper 架构,异步与低精度。可以看到,Tri Dao 这一次的名字挂在最后。此时他虽然还继续在普林斯顿大学任教,但也同时已经是 Together AI 的首席科学家。

论文地址:https://arxiv.org/pdf/2407.08608
为了能加速在 Hopper GPU 上的注意力,FlashAttention-3 主要采用了三种技术:
-
通过 warp-specialization 重叠整体计算和数据移动;
-
交错分块 matmul 和 softmax 运算;
-
利用硬件支持 FP8 低精度的不连贯处理。
FlashAttention-3 的速度是 FlashAttention-2 的 1.5-2.0 倍,高达 740 TFLOPS,即 H100 理论最大 FLOPS 利用率为 75%。使用 FP8,FlashAttention-3 的速度更是接近 1.2 PFLOPS。参阅机器之心报道《英伟达又赚到了!FlashAttention3 来了:H100 利用率飙升至 75%》。
现在,到了 2025 年,FlashAttention-4 准时到来,增加了对 Blackwell GPU 的原生支持——之前,想要在 Blackwell 上跑 FlashAttention,如果直接用开源仓库,常常会遇到编译错误、kernel 缺失或性能未优化的情况,可用的 Blackwell 加速主要是借助英伟达 Triton/cuDNN 的间接支持。
图源:https://www.reddit.com/r/LocalLLaMA/comments/1mt9htu/flashattention_4_leak/
此时,FlashAttention 的 GitHub 软件库已经积累了超过 1.91 万星。
项目地址:https://github.com/Dao-AILab/flash-attention
目前,Tri Dao 团队尚未发布 FlashAttention-4 的技术报告,更多细节还有待进一步揭晓。
参考链接
https://x.com/tri_dao/status/1960217005446791448
https://x.com/SemiAnalysis_/status/1960070677379133949
https://www.reddit.com/r/LocalLLaMA/comments/1mt9htu/flashattention_4_leak/


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









