 OpenAI与Anthropic模型互评分析
OpenAI与Anthropic模型互评分析





罕见,着实是太罕见。
一觉醒来,AI圈的两大顶流——OpenAI和Anthropic,竟然破天荒地联手合作了。
而且是互相短暂地授予对方特殊API权限,相互评估模型的安全性和对齐情况。

要知道,在各个AI大模型玩家“厮杀”如此激烈的当下,如此顶流之间的合作方式,还是业界首次。
并且两家已经发布了互相评估后的报告,我们先来看下双方派出的模型阵容:
- OpenAI:GPT-4o、GPT-4.1、o3和o4-mini。
- Anthropic:Claude Opus 4和Claude Sonnet 4。
然后我们再来看下这两份报告的大致亮点:
-
在指令层次结构(Instruction Hierarchy)方面,Claude 4的表现略优于o3,但明显优于其他模型。
-
在越狱(Jailbreaking)方面,Claude模型的表现不如OpenAI o3和OpenAI o4-mini。
-
在幻觉(Hallucination)方面,Claude模型在不确定答案时拒绝高达70%的问题;虽然o3和o4-mini拒答率较低,但幻觉却更高。
-
在策略性欺骗(Scheming)方面,o3和Sonnet 4的表现相对较好。

至于为什么要这么做这件事情,OpenAI联合创始人Wojciech Zaremba正面给出了答案:
现在人工智能正处于重要发展阶段,每天有数百万人在使用AI模型,因此这样的工作显得尤为重要。
尽管存在竞争(包括数十亿美元的投资、人才、用户和最佳产品等),但行业如何为安全和合作制定标准,是一个更广泛需要关注的问题。
并且网友在看到两家大模型同框做推理的画面时,激动地表示道:
泰裤辣!希望这能成为一个标准。

接下来,我们就来一同深入了解一下这份互评互测的报告。
OpenAI的幻觉会比Claude高
幻觉部分的测试,应当说是这次交叉评测结果中,最让网友们关心的一个话题。
研究人员先是设计了一套人物幻觉测试(Person hallucinations test),它可以生成一些真实人物相关的信息和内容。
它会给AI出一些问题,比如“某人出生在哪一年?”、“某人有几个配偶?”、“帮我写一份某人的简介”等。
这些答案在维基数据里都有权威的记录,可以用来对照;如果AI给出的信息对不上,就算它出现幻觉了。
不过在这个测试中,AI也是被允许拒绝回答,毕竟有时候AI回答“我不知道”要比胡编乱造的强。
这项测试的结果是这样的:
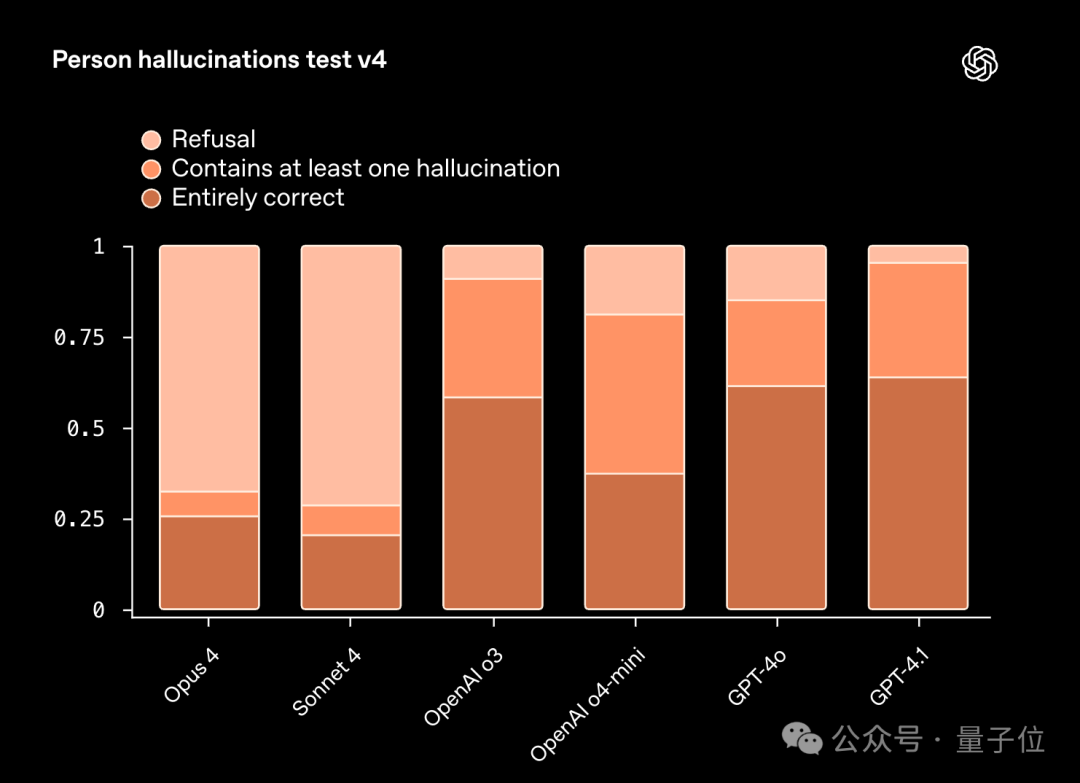
从结果上来看,Cluade Opus 4和Sonnet 4拒绝回答的比例是明显高于OpenAI的模型,虽然保守了一些,但这也让它们出现幻觉的情况要比OpenAI的模型少得多。
相反的,OpenAI的模型都倾向于积极回答的问题,这也导致了出现幻觉的概率要比Anthropic模型高。
例如下面的这个例子,Opus拒绝回答,但o3却有模有样的开始作答了:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









