




内容源自计算机科研圈
深度学习领域,新算法就像那个雨后春笋,追都追不过来。但要说哪块最容易出成果、最适合快速“水”论文,还得是特征提取模块。
深度学习的核心逻辑,说白了就是构建复杂神经网络,自动从数据中挖掘规律、提取特征,然后再应用于分类、预测或生成等任务。这里面特征提取模块就像个筛子,能从原始数据中提炼对后续任务最关键的信息。再加上它本身比较灵活,对新手友好,所以成了很多人深度学习水论文的首选。
下面我就举几个例子,帮助大家掌握用特征提取模块“水”论文的方法。另外也给大家准备了一份配套学习资料包,包含目前主流的特征提取方法的论文代码+150个即插即用的深度学习模块,希望能给大家的论文添砖加瓦!

1. 排列组合:简单粗暴但有效
入门级方法,把现成的经典网络拆拆拼拼就行。比如 ResNet 的残差块、DenseNet 的特征复用、Inception 的多尺度...然后找个数据集跑个实验,说你的方法达到“SOTA”性能。
举个例子:将 ResNet 的残差结构与 DenseNet 的特征复用机制相结合,把模块命名为 “ResDenseNet”。在 CIFAR-10 数据集上跑个实验,发现准确率比原来的ResNet高了0.5%,然后就可以写论文了,名字就叫《基于 XX 与 XX 的多尺度融合网络在图像分类中的应用》。至于这微小提升的价值有没有意义?你把融合的逻辑圆好就行。
参考论文:
LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery
方法:论文提出的LEFormer是一种混合CNN-Transformer架构,用CNN恢复局部细节、提升精细尺度;靠Transformer抓长距依赖获全局特征;经跨编码器融合模块整合二者,精准提取湖泊。
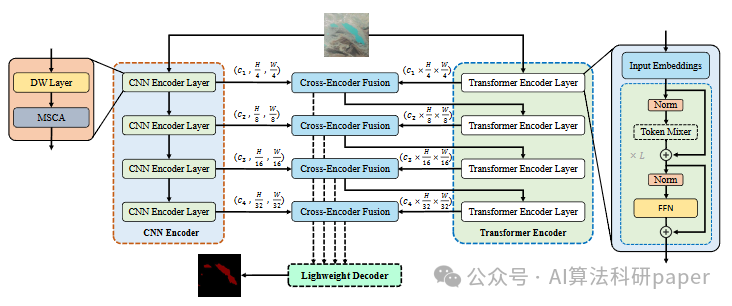
创新点:
-
提出LEFormer,属混合CNN-Transformer架构,融合二者优势攻克湖泊提取难题,改善分割边界与前景建模效果。
-
CNN编码器着力复原局部空间信息,精修细节;Transformer编码器擅捕长距依赖,掌控全局特征及上下文关联。
-
创设跨编码器融合模块,统筹局部和全局特质来优化掩码预判,于双数据集斩获顶尖性能与效能,兼具低参数、高速度优势。
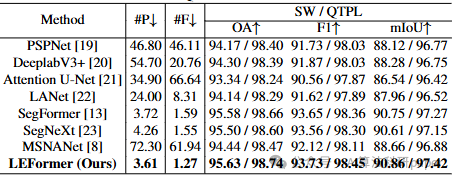
2. 融合注意力机制:热点词直接用
这两年注意力机制不是超级火吗?自注意力、CBAM、SE 模块,挑一个就可以融入特征提取模块。
例如,在 ResNet 的卷积层后嵌入 CBAM 模块,通过通道注意力与空间注意力的双重作用,让网络 “自适应聚焦关键特征”。然后跑 ImageNet 数据集,发现 top-1 准确率提升了 0.3%,就可以写《基于 XX 注意力机制的图像分类性能优化》。这类创新核心在于突出注意力机制对特征筛选的针对性,机制要解释清楚。
参考论文:
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
方法:论文提出了 GCNet 方法,核心在于简化非局部网络,构建全局上下文(GC)块。其以全局注意力池化取特征,经瓶颈变换抓通道依赖,加法融合入各位置特征,强化特征提取。
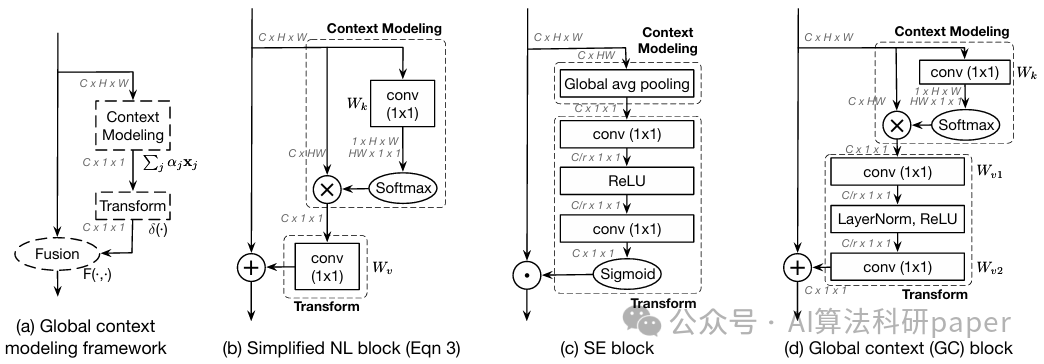
创新点:
-
发现NLNet不同查询位置全局上下文相近,具查询独立性,据此简化 NLNet,在保持精度的同时大幅降低计算成本。
-
统合简化非局部块与SENet为全局上下文建模框架,该框架包含上下文建模、特征变换和融合三个步骤,揭示模块设计关联。
-
GC 块结合简化非局部块的上下文建模与融合方式,及 SENet 的特征变换做法,构建的 GCNet 性能超简化 NLNet 和 SENet。
3. 多任务协同设计:一套模块多用
有时候单做一个任务显得单薄,那就让特征提取模块同时服务于多个相关任务,借助任务间的关联性提升泛化能力。
比如:设计共享特征提取模块,同时处理图像分类与目标检测任务,利用两类任务对图像特征的共性需求实现协同优化。在 COCO 数据集上发现俩任务准确率都微涨了一点,这论文就可以写《多任务联合优化的特征提取网络》,重点吹 “任务协同”、“特征共享带来的效率提升”。
参考论文:
Multi-Task Learning using Uncertainty to Weigh Losses for Scene Geometry and Semantics
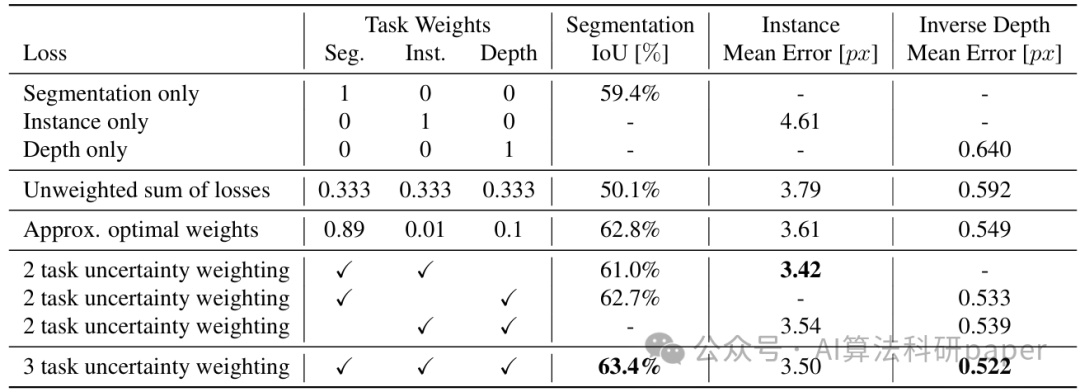
方法:论文采用共享卷积编码器 - 解码器架构,编码器用 ResNet101 和 ASPP 模块提取共享特征,再经任务特定解码器处理,通过 homoscedastic 不确定性自动权衡各任务损失,实现语义分割、实例分割和深度回归的多任务特征提取与融合。
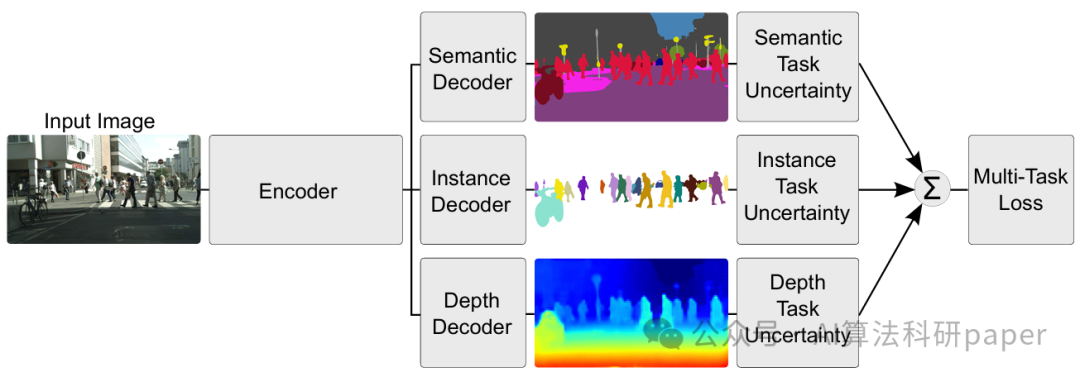
创新点:
-
基于homoscedastic不确定性设计多任务损失函数,自动学习任务权重,无需手动调整。
-
采用ResNet101+ASPP作共享编码器,结合任务解码器,联合学习语义分割、实例分割和深度回归。
-
多任务学习通过共享特征提升各任务性能,在CityScapes上表现优于单任务模型和传统多任务模型。
4. 轻量化设计:面向实用场景
现在都讲究模型小、速度快,尤其移动端场景。这就很适合设计轻量化特征提取模块,然后说你的方法在保持性能的同时“显著降低了模型复杂度”。
最简单的就是把普通卷积换成深度可分离卷积,在 MobileNet 基础上进行优化,发现模型参数量减少了 20%,推理速度提升了 15%,而准确率仅下降 0.2%,就可以写《基于深度可分离卷积的轻量化特征提取网络及其移动端应用》。至于在实际场景中到底好不好用?看需求。
参考论文:
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
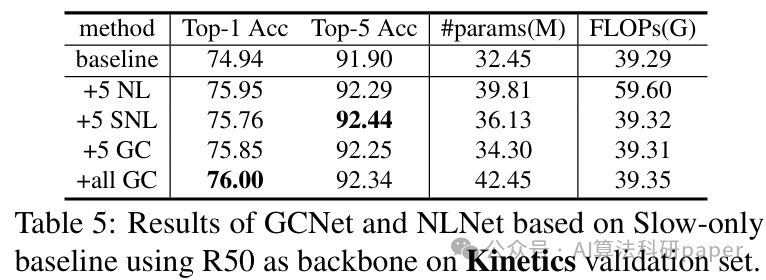
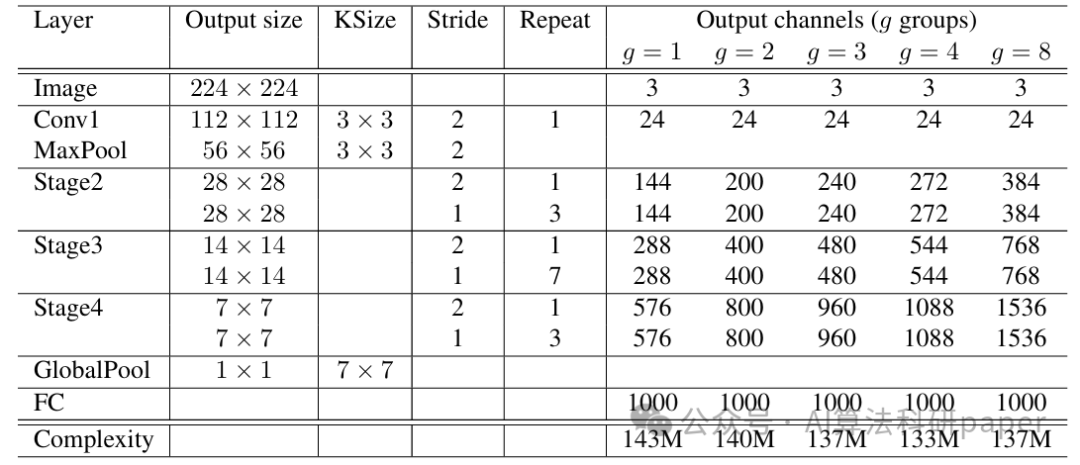
方法:论文提出的 ShuffleNet 架构,在特征提取方面,用逐点分组卷积减少1×1卷积计算量,借通道洗牌加强跨组信息交互,以低成本实现多通道利用,高效适配移动设备等算力受限场景。
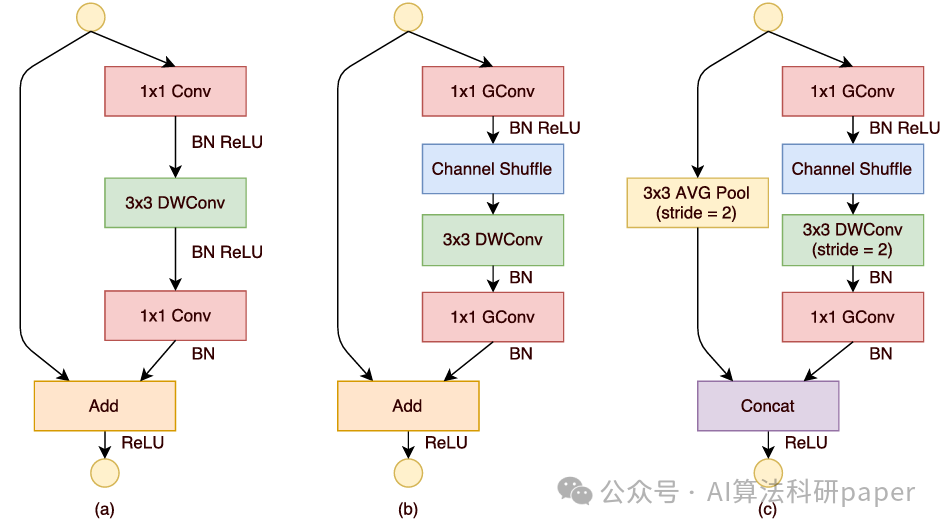
创新点:
-
提出逐点分组卷积,降低1×1卷积的计算复杂度,在有限计算预算下支持更多特征图通道,增强特征提取能力。
-
设计通道洗牌操作,解决分组卷积堆叠导致的通道组间信息流动受阻问题,促进跨组信息交互。
-
基于上述两种操作构建ShuffleNet架构,其高效的网络单元设计使模型在极低计算资源下仍能保持较高精度,特别适用于移动设备。
总的来说,特征提取模块就像块橡皮泥,怎么捏都行。不用追求颠覆性创新,通过以上经典结构融合、热点机制引入、任务协同设计或轻量化优化等方法,论文就差不多有了。当然,扎实完成实验验证,以及对创新点的合理阐述还是重中之重。

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









