







参考文章1:多尺度特征提取模块 Multi-Scale Module及代码-优快云博客
第一版,我仅仅是对上面论文中的代码进行注释理解
(虽然还有一个vgg的inception,也是并行卷积,不过有3x3、7x7、13x13多个尺度的kernel,后来kaiming的做法都改成了3x3,所以inception我暂时没有写,以后可以补一补,说不定inception另有用处)
(一)kaiming的SPPnet:
参考文章(非常棒的博客):空间金字塔池化SPP(Spatial Pyramid Pooling)_spp空间金字塔池化-优快云博客
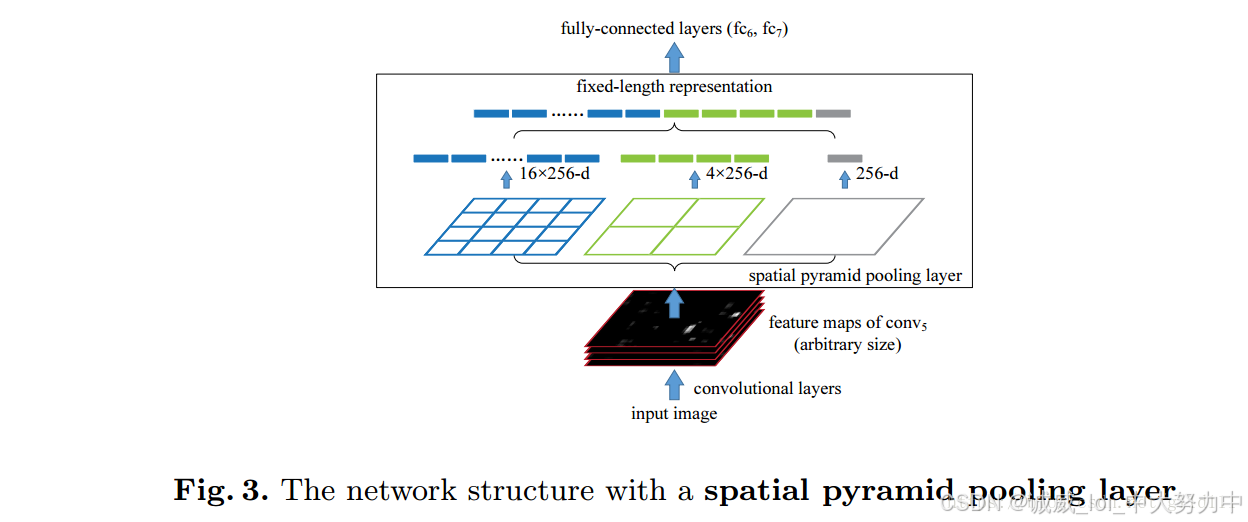

代码及其注释版本:
import torch
import torch.nn as nn
import warnings
# 终于弄明白了,一个max_pool只会得到一个channel哦!,所以k这个list里面的个数就是最终的channel数量
# 不过呢,这里的实现预言了Kaiming的Residual残差连接,所以多加了一个[x]原始feature通道
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5,5,5,5,5, 9,9,9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = nn.Conv2d(c1, c_, 1, 1) # 其实这个中间hidden和我们谈论的SPP是无关的,只是一个中间的东西
self.cv2 = nn.Conv2d(c_ * (len(k) + 1), c2, 1, 1) # 这里定义的cv2是最后把所有的channel全部处理得到输出通道c2
# 下面这一小行代码,竟然就是kaiming大神整篇论文的核心了
# 就是把list k中的每个值作为kernel size,有几个就是输出几个channel,注意,MaxPool的 paddding和stride=1保证了输出和输入的feature的H、W相同
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
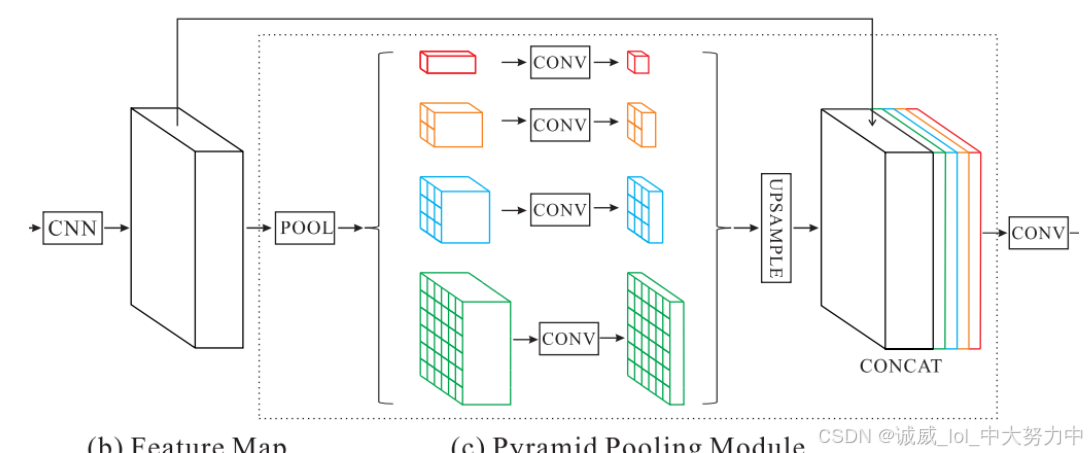
(二)PSPnet——用于复杂场景分割
这个模块叫做 PPM--Pyramid Pooling Module金字塔池化模块
import torch import torch.nn as nn import torch.nn.function as F class PPM(nn.Module): # pspnet def __init__(self, down_dim): super(PPM, self).__init__() # 先对feature进行一个conv2d的变换:将输入channel数2048转换为 down_dim维度的channel数 self.down_conv = nn.Sequential(nn.Conv2d(2048,down_dim , 3,padding=1),nn.BatchNorm2d(down_dim), nn.PReLU()) # 4个自适应的平均池化,输出的H-W自行指定即可 以及 后面都会跟着一个 kernel_size = 1的卷积-这个卷积的输入输出的channel不变 self.conv1 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(1, 1)),nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv2 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(2, 2)), nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv3 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(3, 3)),nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv4 = nn.Sequential(nn.AdaptiveAvgPool2d(output_size=(6, 6)), nn.Conv2d(down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) # 最后还是一个kernel_size = 1的卷积, 前面的4个scale的feature按照channel拼接成4xdown_dim self.fuse = nn.Sequential(nn.Conv2d(4 * down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) def forward(self, x): # 转换为channel == down_dim x = self.down_conv(x) # 分别通过4个池化与卷积(金字塔) conv1 = self.conv1(x) conv2 = self.conv2(x) conv3 = self.conv3(x) conv4 = self.conv4(x) # 上采样-通过双线性差值-原来torch.nn.function里面有设计好的upsample函数 conv1_up = F.upsample(conv1, size=x.size()[2:], mode='bilinear') conv2_up = F.upsample(conv2, size=x.size()[2:], mode='bilinear') conv3_up = F.upsample(conv3, size=x.size()[2:], mode='bilinear') conv4_up = F.upsample(conv4, size=x.size()[2:], mode='bilinear') # 其实这里的实现有一点不对,就是忘了residue残差连接了,不过这个代码写得很清楚 # 返回fuse的结果:原图输入的H-W - down_dim return self.fuse(torch.cat((conv1_up, conv2_up, conv3_up, conv4_up), 1))
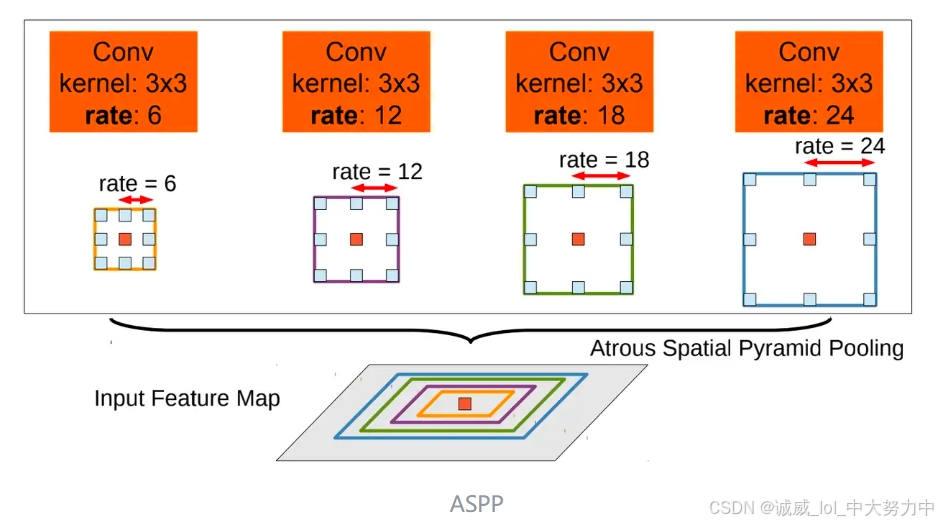
(三)ASPP(是Deeplabv2中的创新设计之一)
参考文章:[论文笔记] DeepLabv2 - 知乎 (zhihu.com)
[论文笔记]DeepLabv1 - 知乎 (zhihu.com)
import torch import torch.nn as nn import torch.nn.function as F # 其实就是 Atrous版本的Spatial Pyramid Pooling class ASPP(nn.Module): def __init__(self, dim,in_dim): super(ASPP, self).__init__() # 转换channel数为in_dim self.down_conv = nn.Sequential(nn.Conv2d(dim,in_dim , 3,padding=1),nn.BatchNorm2d(in_dim), nn.PReLU()) down_dim = in_dim // 2 # 分别用kernel_size = 3但是dilation = 1\2\4\6的空洞卷积,其中输入和输出的feature的H\W相同 self.conv1 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv2 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=2, padding=2), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv3 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU()) self.conv4 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d(down_dim), nn.PReLU()) # conv5是一个kernel_size =1 也是对第一个down_conv的结果使用的,和conv1一样 self.conv5 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1),nn.BatchNorm2d(down_dim), nn.PReLU()) self.fuse = nn.Sequential(nn.Conv2d(5 * down_dim, in_dim, kernel_size=1), nn.BatchNorm2d(in_dim), nn.PReLU()) # 原来这些multi-scale的设计的调用过程都很相似 def forward(self, x): # down_conv变换channel数 x = self.down_conv(x) # 并行-金字塔pooling conv1 = self.conv1(x) conv2 = self.conv2(x) conv3 = self.conv3(x) conv4 = self.conv4(x) # conv5很奇怪,还不如直接用x的残差连接,不过既然这么设计了就这么看,先pool成1x1的h\w然后通过conv5改变channel数,最后线性差值回到原来输入的H-W conv5 = F.upsample(self.conv5(F.adaptive_avg_pool2d(x, 1)), size=x.size()[2:], mode='bilinear') return self.fuse(torch.cat((conv1, conv2, conv3,conv4, conv5), 1))
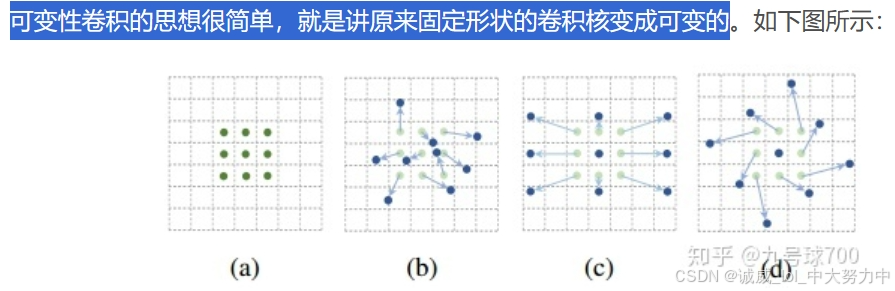
(四)DCN(Deformable Convolution Network)
其实我也总结过可变形卷积,这个结构挺好用
参考文章:CNN卷积神经网络之DCN(Deformable Convolutional Networks、Deformable ConvNets v2)_dcn神经网络-优快云博客
参考文章2:DCN和DCNv2(可变性卷积)学习笔记(原理代码实现方式)_dcnv2代码-优快云博客
首先,我们先看底层实现DCN的v1和v2版本:
v1版本如下:
class DeformConv2D(nn.Module): def __init__(self, inc, outc, kernel_size=3, padding=1, bias=None): super(DeformConv2D, self).__init__() self.kernel_size = kernel_size self.padding = padding self.zero_padding = nn.ZeroPad2d(padding) self.conv_kernel = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias) # 注意,offset的Tensor尺寸是[b, 18, h, w],offset传入的其实就是每个像素点的坐标偏移,也就是一个坐标量,最终每个点的像素还需要这个坐标偏移和原图进行对应求出。 def forward(self, x, offset): dtype = offset.data.type() ks = self.kernel_size # N=9=3x3 N = offset.size(1) // 2 #这里其实没必要,我们反正这个顺序是我们自己定义的,那我们直接按照[x1, x2, .... y1, y2, ...]定义不就好了。 # 将offset的顺序从[x1, y1, x2, y2, ...] 改成[x1, x2, .... y1, y2, ...] offsets_index = Variable(torch.cat([torch.arange(0, 2*N, 2), torch.arange(1, 2*N+1, 2)]), requires_grad=False).type_as(x).long() # torch.unsqueeze()是为了增加维度,使offsets_index维度等于offset offsets_index = offsets_index.unsqueeze(dim=0).unsqueeze(dim=-1).unsqueeze(dim=-1).expand(*offset.size()) # 根据维度dim按照索引列表index将offset重新排序,得到[x1, x2, .... y1, y2, ...]这样顺序的offset offset = torch.gather(offset, dim=1, index=offsets_index) # ------------------------------------------------------------------------ # 对输入x进行padding if self.padding: x = self.zero_padding(x) # 将offset放到网格上,也就是标定出每一个坐标位置 # (b, 2N, h, w) p = self._get_p(offset, dtype) # 维度变换 # (b, h, w, 2N) p = p.contiguous().permute(0, 2, 3, 1) # floor是向下取整 q_lt = Variable(p.data, requires_grad=False).floor() # +1相当于向上取整,这里为什么不用向上取整函数呢?是因为如果正好是整数的话,向上取整跟向下取整就重合了,这是我们不想看到的。 q_rb = q_lt + 1 # 将lt限制在图像范围内,其中[..., :N]代表x坐标,[..., N:]代表y坐标 q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long() # 将rb限制在图像范围内 q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long() # 获得lb q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], -1) # 获得rt q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], -1) # 限制在一定的区域内,其实这部分可以写的很简单。有点花里胡哨的感觉。。在numpy中这样写: #p = np.where(p >= 1, p, 0) #p = np.where(p <x.shape[2]-1, p, x.shape[2]-1) # 插值的时候需要考虑一下padding对原始索引的影响 # (b, h, w, N) # torch.lt() 逐元素比较input和other,即是否input < other # torch.rt() 逐元素比较input和other,即是否input > other mask = torch.cat([p[..., :N].lt(self.padding)+p[..., :N].gt(x.size(2)-1-self.padding), p[..., N:].lt(self.padding)+p[..., N:].gt(x.size(3)-1-self.padding)], dim=-1).type_as(p) #禁止反向传播 mask = mask.detach() #p - (p - torch.floor(p))不就是torch.floor(p)呢。。。 floor_p = p - (p - torch.floor(p)) #总的来说就是把超出图像的偏移量向下取整 p = p*(1-mask) + floor_p*mask p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1) # bilinear kernel (b, h, w, N) # 插值的4个系数 g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:])) g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:])) g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:])) g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:])) # (b, c, h, w, N) x_q_lt = self._get_x_q(x, q_lt, N) x_q_rb = self._get_x_q(x, q_rb, N) x_q_lb = self._get_x_q(x, q_lb, N) x_q_rt = self._get_x_q(x, q_rt, N) # (b, c, h, w, N) # 插值的最终操作在这里 x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \ g_rb.unsqueeze(dim=1) * x_q_rb + \ g_lb.unsqueeze(dim=1) * x_q_lb + \ g_rt.unsqueeze(dim=1) * x_q_rt #偏置点含有九个方向的偏置,_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式, # 于是就可以用 3×3 stride=3 的卷积核进行 Deformable Convolution, # 它等价于使用 1×1 的正常卷积核(包含了这个点9个方向的 context)对原特征直接进行卷积。 x_offset = self._reshape_x_offset(x_offset, ks) out = self.conv_kernel(x_offset) return out #求每个点的偏置方向 def _get_p_n(self, N, dtype): p_n_x, p_n_y = np.meshgrid(range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), indexing='ij') # (2N, 1) p_n = np.concatenate((p_n_x.flatten(), p_n_y.flatten())) p_n = np.reshape(p_n, (1, 2*N, 1, 1)) p_n = Variable(torch.from_numpy(p_n).type(dtype), requires_grad=False) return p_n @staticmethod #求每个点的坐标 def _get_p_0(h, w, N, dtype): p_0_x, p_0_y = np.meshgrid(range(1, h+1), range(1, w+1), indexing='ij') p_0_x = p_0_x.flatten().reshape(1, 1, h, w).repeat(N, axis=1) p_0_y = p_0_y.flatten().reshape(1, 1, h, w).repeat(N, axis=1) p_0 = np.concatenate((p_0_x, p_0_y), axis=1) p_0 = Variable(torch.from_numpy(p_0).type(dtype), requires_grad=False) return p_0 #求最后的偏置后的点=每个点的坐标+偏置方向+偏置 def _get_p(self, offset, dtype): # N = 9, h, w N, h, w = offset.size(1)//2, offset.size(2), offset.size(3) # (1, 2N, 1, 1) p_n = self._get_p_n(N, dtype) # (1, 2N, h, w) p_0 = self._get_p_0(h, w, N, dtype) p = p_0 + p_n + offset return p #求出p点周围四个点的像素 def _get_x_q(self, x, q, N): b, h, w, _ = q.size() padded_w = x.size(3) c = x.size(1) # (b, c, h*w)将图片压缩到1维,方便后面的按照index索引提取 x = x.contiguous().view(b, c, -1) # (b, h, w, N)这个目的就是将index索引均匀扩增到图片一样的h*w大小 index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y # (b, c, h*w*N) index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1) #双线性插值法就是4个点再乘以对应与 p 点的距离。获得偏置点 p 的值,这个 p 点是 9 个方向的偏置所以最后的 x_offset 是 b×c×h×w×9。 x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N) return x_offset #_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式 @staticmethod def _reshape_x_offset(x_offset, ks): b, c, h, w, N = x_offset.size() x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1) x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks) return x_offsetv2版本如下:
import torch from torch import nn class DeformConv2d(nn.Module): def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False): """ Args: modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2). """ super(DeformConv2d, self).__init__() self.kernel_size = kernel_size self.padding = padding self.stride = stride self.zero_padding = nn.ZeroPad2d(padding) self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias) self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride) nn.init.constant_(self.p_conv.weight, 0) self.p_conv.register_backward_hook(self._set_lr) self.modulation = modulation if modulation: self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride) nn.init.constant_(self.m_conv.weight, 0) self.m_conv.register_backward_hook(self._set_lr) @staticmethod def _set_lr(module, grad_input, grad_output): grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input))) grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output))) def forward(self, x): offset = self.p_conv(x) if self.modulation: m = torch.sigmoid(self.m_conv(x)) dtype = offset.data.type() ks = self.kernel_size N = offset.size(1) // 2 if self.padding: x = self.zero_padding(x) # (b, 2N, h, w) p = self._get_p(offset, dtype) # (b, h, w, 2N) p = p.contiguous().permute(0, 2, 3, 1) q_lt = p.detach().floor() q_rb = q_lt + 1 q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long() q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long() q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1) q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1) # clip p p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1) # bilinear kernel (b, h, w, N) g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:])) g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:])) g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:])) g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:])) # (b, c, h, w, N) x_q_lt = self._get_x_q(x, q_lt, N) x_q_rb = self._get_x_q(x, q_rb, N) x_q_lb = self._get_x_q(x, q_lb, N) x_q_rt = self._get_x_q(x, q_rt, N) # (b, c, h, w, N) x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \ g_rb.unsqueeze(dim=1) * x_q_rb + \ g_lb.unsqueeze(dim=1) * x_q_lb + \ g_rt.unsqueeze(dim=1) * x_q_rt # modulation if self.modulation: m = m.contiguous().permute(0, 2, 3, 1) m = m.unsqueeze(dim=1) m = torch.cat([m for _ in range(x_offset.size(1))], dim=1) x_offset *= m x_offset = self._reshape_x_offset(x_offset, ks) out = self.conv(x_offset) return out def _get_p_n(self, N, dtype): p_n_x, p_n_y = torch.meshgrid( torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1)) # (2N, 1) p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0) p_n = p_n.view(1, 2*N, 1, 1).type(dtype) return p_n def _get_p_0(self, h, w, N, dtype): p_0_x, p_0_y = torch.meshgrid( torch.arange(1, h*self.stride+1, self.stride), torch.arange(1, w*self.stride+1, self.stride)) p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1) p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1) p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype) return p_0 def _get_p(self, offset, dtype): N, h, w = offset.size(1)//2, offset.size(2), offset.size(3) # (1, 2N, 1, 1) p_n = self._get_p_n(N, dtype) # (1, 2N, h, w) p_0 = self._get_p_0(h, w, N, dtype) p = p_0 + p_n + offset return p def _get_x_q(self, x, q, N): b, h, w, _ = q.size() padded_w = x.size(3) c = x.size(1) # (b, c, h*w) x = x.contiguous().view(b, c, -1) # (b, h, w, N) index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y # (b, c, h*w*N) index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1) x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N) return x_offset @staticmethod def _reshape_x_offset(x_offset, ks): b, c, h, w, N = x_offset.size() x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1) x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks) return x_offset好吧,其实还有一个v3,但我暂时不分析那个了。呜呜~~
然后,我们来看DCN的torchvision库的调用示例:
import torch import torch.nn as nn import torchvision.ops as ops class DeformableConvNet(nn.Module): def __init__(self): super(DeformableConvNet, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1) self.deformable_conv = ops.DeformConv2d(64, 64, kernel_size=3, padding=1) def forward(self, x): x = self.conv1(x) # 假设 offset 是预先计算好的偏移量 offset = self.get_offset(x) x = self.deformable_conv(x, offset) return x def get_offset(self, x): # 假设我们有一个方法来生成 offset # 这里简单返回一个全 0 的偏移量 return torch.zeros(x.size(0), 18, x.size(2), x.size(3), device=x.device) # 创建模型 model = DeformableConvNet() # 输入示例 input_tensor = torch.randn(1, 3, 256, 256) # Batch size 1, 3 channels, 256x256 image output = model(input_tensor) print("Output shape:", output.shape)示例2:
import torch import torch.nn as nn import torchvision.ops as ops class DeformableConvExample(nn.Module): def __init__(self): super(DeformableConvExample, self).__init__() # 一个卷积,一个偏移量卷积,一个变形卷积 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1) # 普通卷积 self.offset_conv = nn.Conv2d(64, 18, kernel_size=3, padding=1) # 用于生成偏移量 self.deformable_conv = ops.DeformConv2d(64, 64, kernel_size=3, padding=1) # Deformable Conv def forward(self, x): # 原来还要有一个偏移量的计算 x = self.conv1(x) # 通过普通卷积层 offset = self.offset_conv(x) # 生成偏移量 - 之所以是18,就是因为kernel_size =3 ,3x3x2 = 18,其中2是x和y的方向 # 注意:所谓的偏移是针对kernel卷积核来说的,所以是3x3的核的每个位置的x和y方向的偏移 x = self.deformable_conv(x, offset) # 使用可变形卷积 # 其实这个DeformConv2d用起来是和Conv2d没有区别的,只是内部实现被封装了,只要理解其原理就行 return x # 创建模型 model = DeformableConvExample() # 输入示例 input_tensor = torch.randn(1, 3, 256, 256) # Batch size 1, 3 channels, 256x256 image output = model(input_tensor) print("Output shape:", output.shape)
速度解决上面三段代码,我想看第三局了
(五)RFB(18年的论文)
https://arxiv.org/pdf/1711.07767.pdf

又是和显示物理世界对应的想法:

哦哦哦!我懂了,原来这里就是 inception的空洞卷积创新版,其实就是3x3、5x5、7x7的并行,同时呢,3x3就对应后面一个小的空洞,7x7对应大的空洞。——也是有趣的想法
import torch import torch.nn as nn import torch.nn.functional as F # 先看这个基础版的RFB模块 class BasicRFB(nn.Module): def __init__(self, in_planes, out_planes, stride=1, scale = 0.1, visual = 1): super(BasicRFB, self).__init__() # 设置模块变量 self.scale = scale self.out_channels = out_planes inter_planes = in_planes // 8 # 设置3个branche分支(并行金字塔) # 每个分支是 一个卷积 + 一个空洞卷积 self.branch0 = nn.Sequential( BasicConv(in_planes, 2*inter_planes, kernel_size=1, stride=stride), BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual, dilation=visual, relu=False) ) self.branch1 = nn.Sequential( BasicConv(in_planes, inter_planes, kernel_size=1, stride=1), BasicConv(inter_planes, 2*inter_planes, kernel_size=(3,3), stride=stride, padding=(1,1)), BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual+1, dilation=visual+1, relu=False) ) self.branch2 = nn.Sequential( BasicConv(in_planes, inter_planes, kernel_size=1, stride=1), BasicConv(inter_planes, (inter_planes//2)*3, kernel_size=3, stride=1, padding=1), BasicConv((inter_planes//2)*3, 2*inter_planes, kernel_size=3, stride=stride, padding=1), BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=2*visual+1, dilation=2*visual+1, relu=False) ) # 最终的合并concat self.ConvLinear = BasicConv(6*inter_planes, out_planes, kernel_size=1, stride=1, relu=False) self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False) self.relu = nn.ReLU(inplace=False) def forward(self,x): # 分别通过3个分支获取x0、x1、x2 x0 = self.branch0(x) x1 = self.branch1(x) x2 = self.branch2(x) # concat这些x0-x2作为初步输出 out = torch.cat((x0,x1,x2),1) # 转为out_planes个channel是数量 out = self.ConvLinear(out) # 相当于一种残差连接 short = self.shortcut(x) out = out*self.scale + short out = self.relu(out) return out # -----------下面这个先不看 class BasicRFB_a(nn.Module): def __init__(self, in_planes, out_planes, stride=1, scale = 0.1): super(BasicRFB_a, self).__init__() self.scale = scale self.out_channels = out_planes inter_planes = in_planes //4 self.branch0 = nn.Sequential( BasicConv(in_planes, inter_planes, kernel_size=1, stride=1), BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=1,relu=False) ) self.branch1 = nn.Sequential( BasicConv(in_planes, inter_planes, kernel_size=1, stride=1), BasicConv(inter_planes, inter_planes, kernel_size=(3,1), stride=1, padding=(1,0)), BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False) ) self.branch2 = nn.Sequential( BasicConv(in_planes, inter_planes, kernel_size=1, stride=1), BasicConv(inter_planes, inter_planes, kernel_size=(1,3), stride=stride, padding=(0,1)), BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False) ) self.branch3 = nn.Sequential( BasicConv(in_planes, inter_planes//2, kernel_size=1, stride=1), BasicConv(inter_planes//2, (inter_planes//4)*3, kernel_size=(1,3), stride=1, padding=(0,1)), BasicConv((inter_planes//4)*3, inter_planes, kernel_size=(3,1), stride=stride, padding=(1,0)), BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=5, dilation=5, relu=False) ) self.ConvLinear = BasicConv(4*inter_planes, out_planes, kernel_size=1, stride=1, relu=False) self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False) self.relu = nn.ReLU(inplace=False) def forward(self,x): x0 = self.branch0(x) x1 = self.branch1(x) x2 = self.branch2(x) x3 = self.branch3(x) out = torch.cat((x0,x1,x2,x3),1) out = self.ConvLinear(out) short = self.shortcut(x) out = out*self.scale + short out = self.relu(out) return out
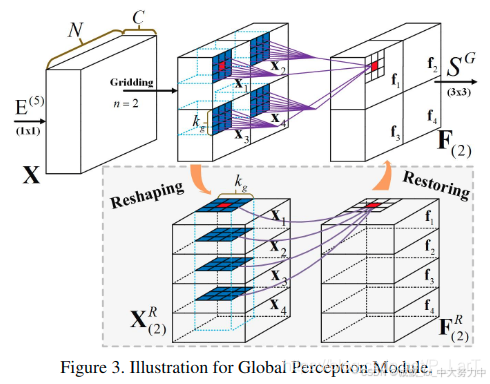
(六)GPM(19年CVPR)
CVPR2019 AFNet: Attentive Feedback Network for Boundary-aware Salient Object Detection
这个结构图我是没看懂,不管了直接看GPM模块的代码应该就明白了
import torch import torch.nn as nn import torch.nn.functional as F # 通过对输入特征图进行多通道的处理,分别处理 2、4 和 6 个通道,最终将其融合。 class GPM(nn.Module): def __init__(self, in_dim): super(GPM, self).__init__() # 设置模块内部变量 down_dim = 512 n1, n2, n3 = 2, 4, 6 # 转换为down_dim self.conv1 = nn.Sequential(nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) # 定义3个分支(n1\n2\n3分别是2、4、6) self.conv2 = nn.Sequential(nn.Conv2d(down_dim * n1 * n1, down_dim * n1 * n1, kernel_size=3, padding=1), nn.BatchNorm2d(down_dim * n1 * n1), nn.PReLU()) self.conv3 = nn.Sequential(nn.Conv2d(down_dim * n2 * n2, down_dim * n2 * n2, kernel_size=3, padding=1), nn.BatchNorm2d(down_dim * n2 * n2), nn.PReLU()) self.conv4 = nn.Sequential(nn.Conv2d(down_dim * n3 * n3, down_dim * n3 * n3, kernel_size=3, padding=1), nn.BatchNorm2d(down_dim * n3 * n3), nn.PReLU()) # 定义fuse块 self.fuse = nn.Sequential(nn.Conv2d(3 * down_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()) def forward(self, x): conv1 = self.conv1(x) ########################################################################### # 3个分支只要看懂一个即可 gm_2_a = torch.chunk(conv1, 2, 2) # 先按照 c = [] for i in range(len(gm_2_a)): b = torch.chunk(gm_2_a[i], 2, 3) c.append(torch.cat((b[0], b[1]), 1)) gm1 = torch.cat((c[0], c[1]), 1) gm1 = self.conv2(gm1) gm1 = torch.chunk(gm1, 2 * 2, 1) d = [] for i in range(2): d.append(torch.cat((gm1[2 * i], gm1[2 * i + 1]), 3)) gm1 = torch.cat((d[0], d[1]), 2) ########################################################################### gm_4_a = torch.chunk(conv1, 4, 2) e = [] for i in range(len(gm_4_a)): f = torch.chunk(gm_4_a[i], 4, 3) e.append(torch.cat((f[0], f[1], f[2], f[3]), 1)) gm2 = torch.cat((e[0], e[1], e[2], e[3]), 1) gm2 = self.conv3(gm2) gm2 = torch.chunk(gm2, 4 * 4, 1) g = [] for i in range(4): g.append(torch.cat((gm2[4 * i], gm2[4 * i + 1], gm2[4 * i + 2], gm2[4 * i + 3]), 3)) gm2 = torch.cat((g[0], g[1], g[2], g[3]), 2) ########################################################################### gm_6_a = torch.chunk(conv1, 6, 2) h = [] for i in range(len(gm_6_a)): k = torch.chunk(gm_6_a[i], 6, 3) h.append(torch.cat((k[0], k[1], k[2], k[3], k[4], k[5]), 1)) gm3 = torch.cat((h[0], h[1], h[2], h[3], h[4], h[5]), 1) gm3 = self.conv4(gm3) gm3 = torch.chunk(gm3, 6 * 6, 1) j = [] for i in range(6): j.append( torch.cat((gm3[6 * i], gm3[6 * i + 1], gm3[6 * i + 2], gm3[6 * i + 3], gm3[6 * i + 4], gm3[6 * i + 5]), 3)) gm3 = torch.cat((j[0], j[1], j[2], j[3], j[4], j[5]), 2) ########################################################################### # 最终的融合feature return self.fuse(torch.cat((gm1, gm2, gm3), 1))我承认,这个我没看明白,不过弄懂了torch.chunk的使用,以及其中的分块合并等操作
未完待续:
-Big-Little Module - 19年
-PAFEM - 20年
-FoldConv_ASPP-20年
..................................................忙完就来补上


















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









