




我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。
大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。目前而言,Agent 是我们走向通用人工智能(AGI)的重要过渡。训练 Agent 则需要带有行动标签的真实交互数据,而获取这类数据的成本远比从网页上获取文本与图像的成本高昂得多。
因此,研究者一直在尝试寻找一种替代方案,来实现鱼和熊掌兼得的效果:既能够降低数据获取成本,又能够保证大模型训练成果,保持基础模型训练中常见的大规模数据带来的优势。
加州大学伯克利分校副教授,Physical Intelligence 的联合创始人,强化学习领域大牛 Sergey Levine 为此撰写了一篇文章,分析了训练大模型的数据组合,但他却认为,鱼和熊掌不可兼得,叉子和勺子组合成的「叉勺」确实很难在通用场景称得上好用。
在人工智能的演进历程中,一个根本性矛盾日益凸显:基础模型对海量数据的渴求,与机器人领域获取真实交互数据的超高成本之间,形成了一道难以逾越的鸿沟。当大型语言模型(LLM)轻松消化万亿级网页文本时,训练一个能抓取咖啡杯的机器人可能需要耗费数千小时的真实操作记录——这种不对称性,正将研究者推向“替代数据”的探索之路,而这条捷径的尽头,可能只是一座空中楼阁。
一、替代数据的三重幻象
当前机器人学习领域的主流替代方案,试图用低成本数据模拟真实物理世界的复杂性,却陷入了三重结构性陷阱:
-
仿真系统的规则囚笼
通过Unity或Isaac Gym构建的虚拟环境,本质上是用人类预设的物理参数(摩擦系数、材质刚度)定义机器人行为边界。当模型在仿真中学会穿越“随机石板路”时,它掌握的并非通用移动能力,而是开发者设定的特定解决方案。更关键的是,仿真越追求真实感,开发成本反而逼近真实实验——2023年斯坦福研究显示,高保真机械臂仿真环境单次训练成本超$8,000。 -
人类视频的认知错位
基于YouTube烹饪视频训练机器人切菜,需建立人手-机械臂运动映射模型。但人类腕关节的7自由度旋转与Delta机器人的平行结构存在根本性动力学差异。加州理工实验表明,此类模型迁移到实体机器人时失败率高达67%,因算法始终在模仿“人类动作”而非探索“机器最优解”。 -
手持设备的路径依赖
让人类操纵仿生夹爪采集数据看似巧妙,实则隐含危险假设:设备默认机器人应在6自由度空间操作。当面对需全身协作的任务(如推开障碍物取物),系统因运动学约束彻底失效。MIT团队2024年发现,此类训练使机器人在新场景中尝试错误动作的概率增加83%。
二、领域鸿沟:替代数据无法跨越的物理法则
Sergey Levine教授提出的“领域鸿沟模型”揭示了问题本质:替代数据域(红色)与真实任务域(绿色)的交集大小,决定了模型有效行为的上限。随着模型能力提升(黄色圆圈收缩),识别领域差异的能力增强,行为交集反而缩小。
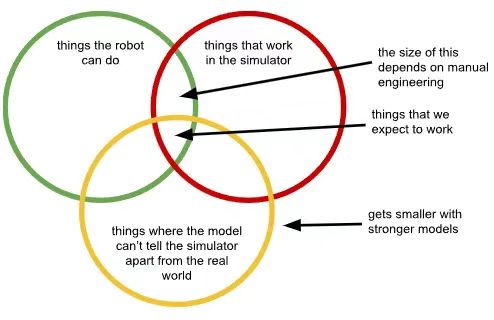
为维持迁移效果,研究者被迫引入“信息屏蔽”策略:限制视觉输入分辨率、简化动力学模型、固定环境光照参数。这些操作实质是主动削弱模型感知能力——如同要求F1车手佩戴老花镜驾驶,只为让他忽略赛道与训练场的区别。更严峻的是,替代数据的有效性高度依赖预设场景。在Open-X Embodiment计划中,用仿真数据训练的开门模型迁移到真实门锁时成功率92%,但遇到新型电子锁(训练集未覆盖)时直接降为0%。
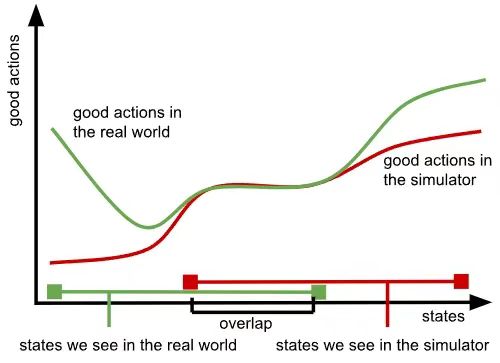
三、真实数据的不可替代性:来自神经科学的启示
人脑运动皮层的研究为机器人学习提供了关键参照。
人类通过本体感觉反馈校准动作精度而非单纯视觉模仿,依赖小脑纠错机制动态调整运动模式,并在海马体构建真实空间坐标的运动记忆拓扑网。
这些机制解释了为何替代数据难以奏效:缺乏本体传感器反馈的仿真视频无法提供动力学误差信号,手持设备采集的运动轨迹缺失环境空间编码。
2025年ETH Zurich的实验证实,在真实环境中训练50小时的机械臂泛化能力超过仿真训练500小时的对照组,物理世界中的摩擦力突变、材质形变等“噪声”恰恰是泛化能力的催化剂。
四、破局路径:面向AGI的数据三角验证框架
抛弃替代思维建立多层次数据融合策略才是破解困局的正解。
采用主动学习策略优先采集决策边界样本,DeepMind的RT-X计划证明仅需200小时针对性真实操作可使模型在新工具使用任务中成功率提升55%。构建基于真实物理参数的随机仿真环境而非追求视觉保真度。
UC Berkeley的DynoSim框架通过随机摩擦系数策略将迁移效率提升至78%。将人类视频作为“世界知识”输入而非动作模板,MIT的PhysiCLIP模型通过对比学习对齐视频语义与机器人动作空间使零样本任务理解正确率提高41%。
在机器人手术领域,约翰霍普金斯团队已实践该框架:
- 核心层:20小时真实手术台操作视频;
- 增强层:Unity仿真软组织变形参数±25%的随机样本;
- 知识层:500小时外科教学录像+医学图谱。
最终模型在未训练的微创手术中,器械碰撞风险降低63%。
替代数据的探索如同在沙漠中寻找海市蜃楼,看似捷径实则歧途。机器人学习的本质是在物理约束下建立因果推理能力——这要求模型必须“亲手触碰”世界的粗糙表面。当我们停止寻找“更便宜的假数据”,转而设计“更高效的真数据采集范式”,或许才能跨越当前的技术高原。
正如Levine所言:“让机器人在现实世界中留下足迹,比在虚拟空间复制百万个完美轨迹更有价值。”

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









