








 该专栏为热销专栏榜 第64名
该专栏为热销专栏榜 第64名 超级会员免费看
超级会员免费看


 本文深入探讨逆强化学习的基本原理,包括从智能体行为中推断奖励函数的方法,以及在实际应用如机器人、自动驾驶和游戏AI中的应用。通过数学模型和代码实例,阐述了逆强化学习在解决强化学习奖励函数设计挑战中的重要作用,并讨论了未来发展趋势和面临的挑战。
本文深入探讨逆强化学习的基本原理,包括从智能体行为中推断奖励函数的方法,以及在实际应用如机器人、自动驾驶和游戏AI中的应用。通过数学模型和代码实例,阐述了逆强化学习在解决强化学习奖励函数设计挑战中的重要作用,并讨论了未来发展趋势和面临的挑战。
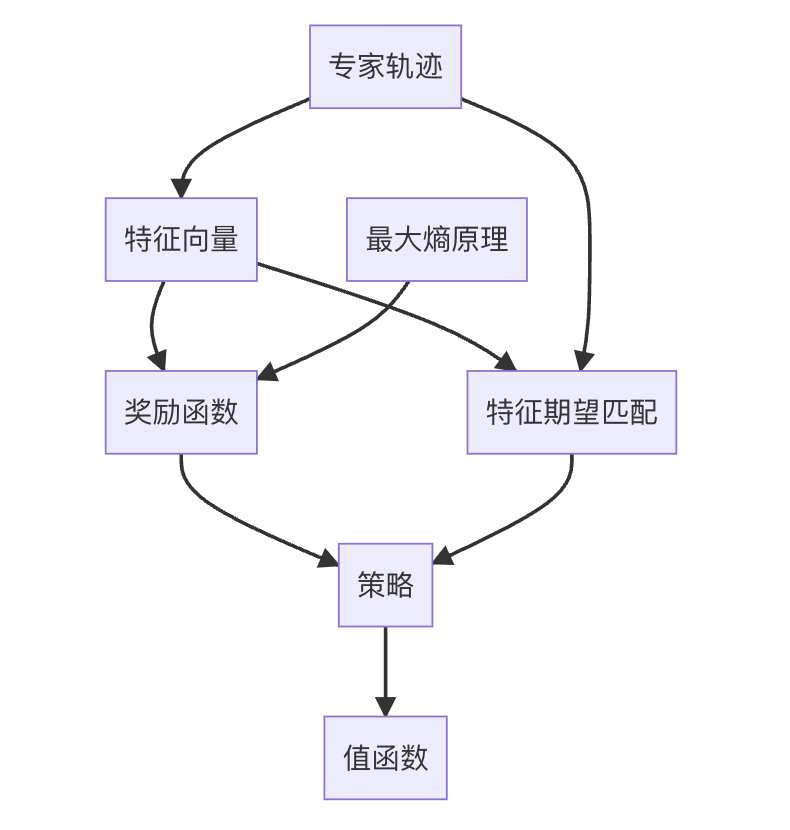
逆强化学习 (Inverse Reinforcement Learning) 原理与代码实例讲解
关键词:逆强化学习、奖励函数、最大熵原理、特征期望匹配、策略优化、机器学习、人工智能
1. 背景介绍
逆强化学习(Inverse Reinforcement Learning,简称IRL)是机器学习和人工智能领域中一个重要的研究方向。它的出现源于这样一个问题:
在许多实际应用场景中,我们往往能够观察到专家或人类的行为,但却难以直接定义或量化这些行为背后的奖励函数。传统的强化学习假设奖励函数是已知的,而逆强化学习则试图从观察到的行为中推断出潜在的奖励函数。
逆强化学习的概念最早由Stuart Russell在1998年提出,但直到2000年代中期才开始受到广泛关注。Andrew Ng和Stuart Russell在2000年发表的论文《Algorithms for Inverse Reinforcement Learning》正式奠定了IRL的理论基础。随后,Pieter Abbeel和Andrew Ng在2004年提出的"学徒学习"(Apprenticeship Learning)进一步推动了这一领域的发展。
逆强化学

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











