




2025年7月22日阿里通义千问团队于推出升级版开源大模型 Qwen3-235B-A22B-Instruct-2507-FP8,该版本在技术架构与性能表现上实现显著突破。

新模型的核心创新在于深度融合 非思考模式(Non-thinking),通过精准指令响应机制优化任务执行效率。在复杂场景中,该模式可大幅降低模型自主决策比例,转而严格遵循用户指令生成简洁输出,尤其适用于高频数据转换、结构化文本生成等对响应速度与稳定性要求较高的工业场景。
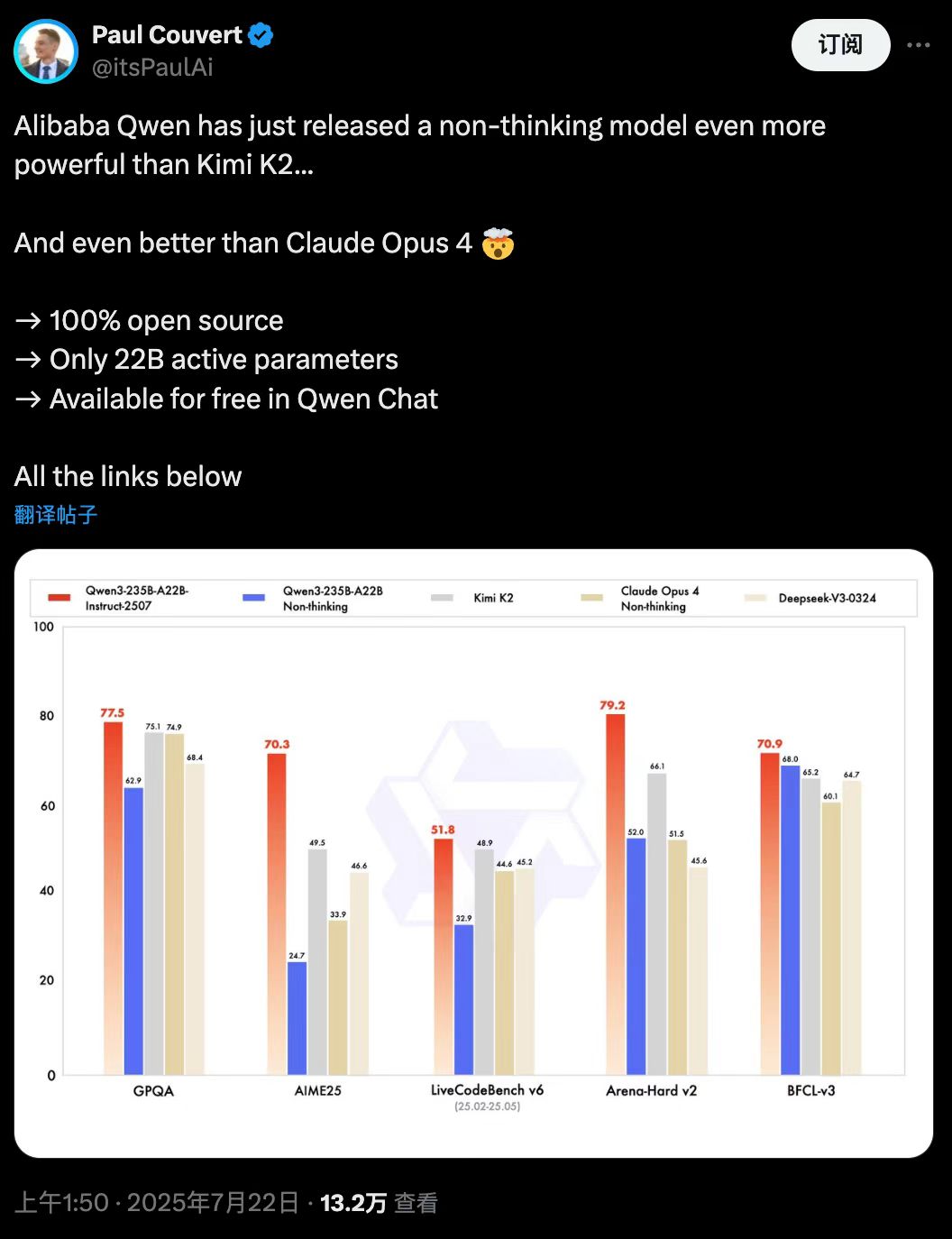
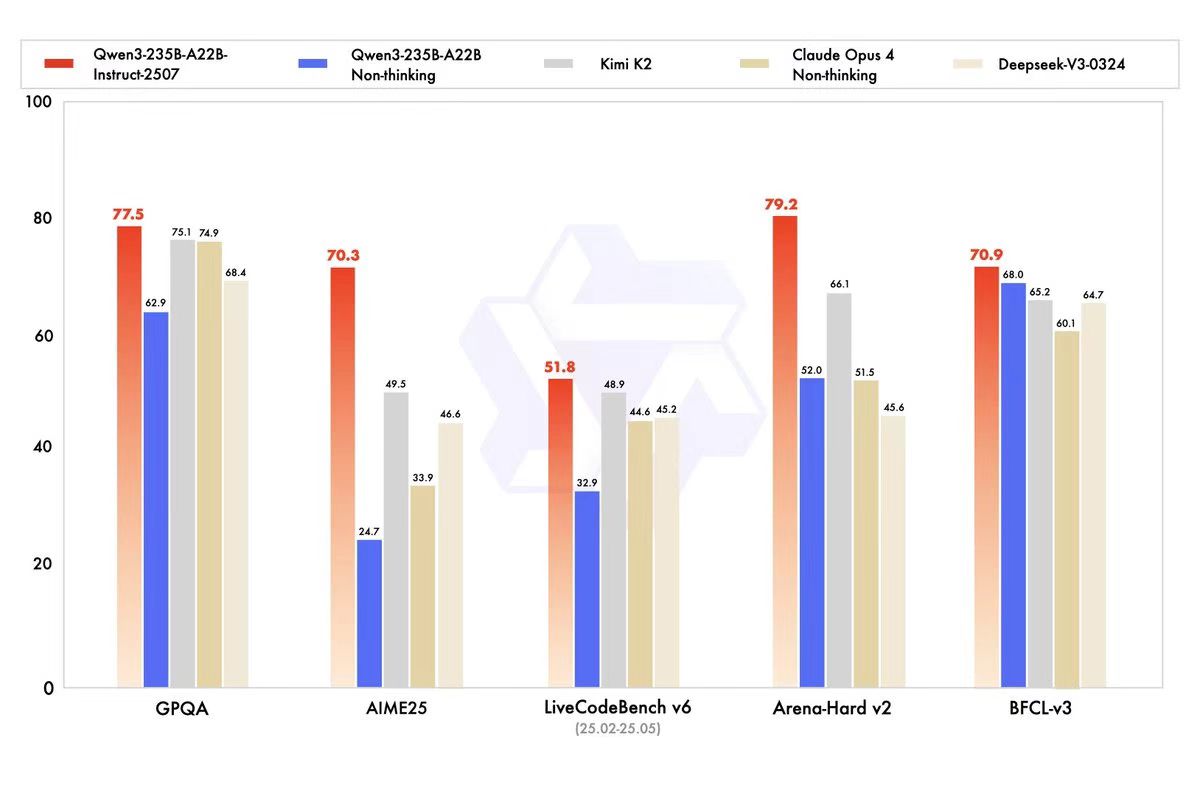
性能方面,该模型在多项权威测评中刷新开源模型纪录。具体表现为:知识评测(GQPA)中超越Kimi-K2,数学推理(AIME25)得分领先DeepSeek-V3,编程能力(LiveCodeBench)与人类偏好对齐(Arena-Hard)均优于Claude-Opus4闭源模型。这些突破源于三方面技术升级:多语言长尾知识库扩展覆盖低资源语言任务,开放式任务生成优化增强用户意图契合度,以及256K长上下文处理能力实现对超长文档的连贯解析。
 技术架构上,模型采用FP8量化压缩技术,在保持2350亿参数规模的同时,显著提升推理效率并降低显存占用。实际部署中,4张H20 GPU即可支持满负荷运行,为企业级应用提供高性价比方案。训练过程中创新性融合四阶段强化学习策略,包括思维链冷启动与动态模式融合,确保思考模式与非思考模式在单一模型中的无缝切换。
技术架构上,模型采用FP8量化压缩技术,在保持2350亿参数规模的同时,显著提升推理效率并降低显存占用。实际部署中,4张H20 GPU即可支持满负荷运行,为企业级应用提供高性价比方案。训练过程中创新性融合四阶段强化学习策略,包括思维链冷启动与动态模式融合,确保思考模式与非思考模式在单一模型中的无缝切换。

开发者现可通过 Hugging Face 与 魔搭社区 获取完整开源模型,支持本地化部署与定制化微调。阿里团队同步公开技术报告详述训练细节,涵盖MoE架构优化策略、119种语言数据处理流程及128专家路由机制,为社区二次开发提供透明技术参照。
此次升级标志着国产大模型在工程化落地领域取得实质性进展,其平衡性能与成本的特性有望推动AI技术在医疗文档分析、法律文本处理等长文本场景的规模化应用。


















 4075
4075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









