Qwen3-235B-A22B-Instruct-2507:开源大语言模型新标杆,2350亿参数驱动多场景突破
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Instruct-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Instruct-2507 Qwen3-235B-A22B-Instruct-2507 作为一款领先的开源大语言模型,凭借 2350 亿总参数及 220 亿激活参数的架构设计,在多个关键能力维度实现了显著跃升。其在指令理解与执行、复杂逻辑推理、深度文本解析、数学科学问题求解、代码生成以及外部工具调用等核心任务上展现出卓越性能,尤其在长尾知识的广度覆盖和多语言处理能力方面取得了突破性进展。该模型原生支持 256K 超长上下文窗口,能够精准捕捉用户意图,生成符合个性化偏好的内容,在主观创作与开放式任务中表现突出。通过多项权威基准测试验证,其在知识掌握、推理深度、编码效率、人机对齐及智能代理任务等方面均超越同级别模型,展现出强大的综合竞争力。部署方式灵活多样,全面兼容 Hugging Face transformers、vLLM、SGLang 等主流框架,可无缝适配本地部署与云端服务场景。借助 Qwen-Agent 工具生态,模型的智能代理能力得到充分释放,大幅简化了复杂任务的自动化处理流程。为获取最佳输出效果,官方推荐采用 Temperature=0.7、TopP=0.8 等参数组合进行配置。
核心能力升级亮点
Qwen3-235B-A22B-Instruct-2507 作为 Qwen3-235B-A22B 非思考模式的升级版,带来了一系列关键增强特性:
- 通用能力全面强化,涵盖指令遵循精度、逻辑推理复杂度、文本理解深度、数学科学问题解决效率、代码生成质量及工具调用准确性等维度。
- 多语言长尾知识覆盖广度显著拓展,能够处理更多低频、专业领域的跨语言信息。
- 在主观任务与开放式场景中,内容生成与用户偏好的对齐度大幅提升,回复更具实用性,文本创作质量达到新高度。
- 256K 超长上下文理解能力进一步优化,信息处理的完整性与连贯性得到增强。
模型架构与技术规格
Qwen3-235B-A22B-Instruct-2507 具备以下技术特性:
- 模型类型:因果语言模型
- 训练阶段:预训练与指令微调
- 参数规模:总参数 2350 亿,激活参数 220 亿
- 非嵌入层参数:2340 亿
- 网络层数:94 层
- 注意力机制:采用 GQA 架构,查询头(Q)64 个,键值头(KV)4 个
- 专家系统:包含 128 个专家,每次推理激活 8 个专家
- 上下文长度:原生支持 262,144 tokens,可扩展至 1,010,000 tokens
注意:该模型仅支持非思考模式输出,不会生成思考过程块,且无需额外设置 enable_thinking=False 参数。
快速上手指南
Qwen3-MoE 的核心代码已集成至最新版 Hugging Face transformers 库,建议用户使用 transformers 最新版本以确保功能完整性。
若使用 transformers<4.51.0 版本,可能会出现如下错误: KeyError: 'qwen3_moe'
以下代码片段展示了如何基于给定输入使用模型生成内容: from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" )
准备模型输入
prompt = "请简要介绍大语言模型的基本概念。" messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
执行文本生成
generated_ids = model.generate( **model_inputs, max_new_tokens=16384 ) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
智能代理应用框架
Qwen3 在工具调用领域展现出强大潜力,推荐结合 Qwen-Agent 工具包以充分发挥其智能代理能力。Qwen-Agent 内置工具调用模板与解析器,有效降低了开发复杂度。
用户可通过 MCP 配置文件定义可用工具,或直接使用 Qwen-Agent 集成工具,亦支持自定义工具扩展: from qwen_agent.agents import Assistant
定义大语言模型配置
llm_cfg = { 'model': 'Qwen3-235B-A22B-Instruct-2507',
# 使用兼容 OpenAI API 的自定义端点:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
定义工具集
tools = [ {'mcpServers': { # 可指定 MCP 配置文件 'time': { 'command': 'uvx', 'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai'] }, "fetch": { "command": "uvx", "args": ["mcp-server-fetch"] } } }, 'code_interpreter', # 内置代码解释器工具 ]
初始化智能代理
bot = Assistant(llm=llm_cfg, function_list=tools)
流式生成示例
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ 请介绍 Qwen 的最新进展'}] for responses in bot.run(messages=messages): pass print(responses)
超长文本处理方案
为支持超长上下文处理(最高可达 100 万 tokens),该模型集成了两项核心技术:
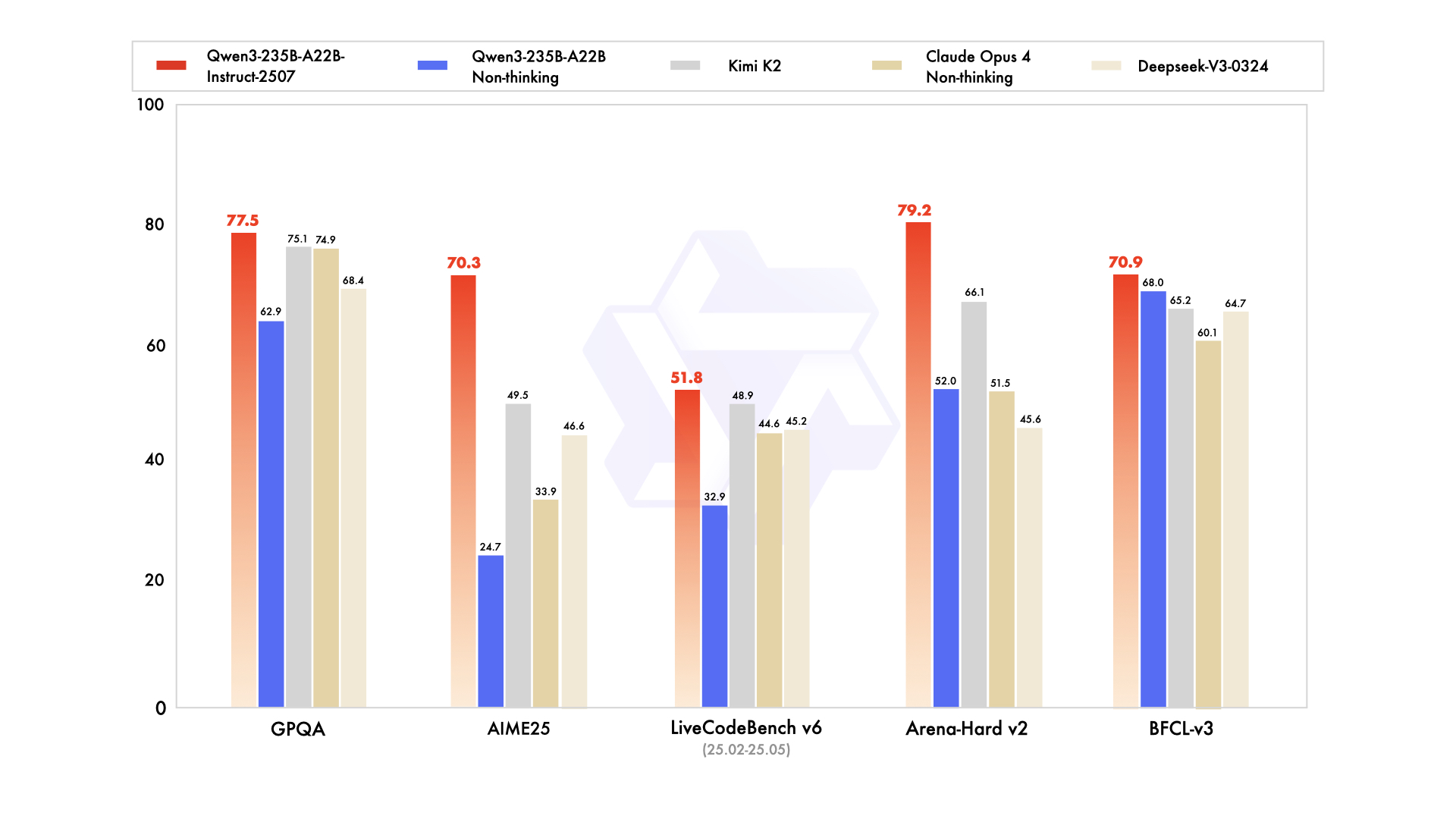 如上图所示,可能展示了Qwen3-235B-A22B-Instruct-2507模型在超长文本处理方面的技术架构或性能对比。这一技术创新充分体现了模型在处理海量信息时的突破性进展,为需要处理长篇文档、书籍或大型数据集的研究人员和开发者提供了高效解决方案。
如上图所示,可能展示了Qwen3-235B-A22B-Instruct-2507模型在超长文本处理方面的技术架构或性能对比。这一技术创新充分体现了模型在处理海量信息时的突破性进展,为需要处理长篇文档、书籍或大型数据集的研究人员和开发者提供了高效解决方案。
- 双块注意力机制(DCA):一种长度外推方法,将长序列分割为可管理的块,同时保持全局连贯性。
- MInference:稀疏注意力机制,通过聚焦关键 token 交互减少计算开销。
这些创新技术共同提升了超过 256K tokens 序列的生成质量与推理效率。在接近 100 万 tokens 的序列处理中,系统相比标准注意力实现提速最高可达 3 倍。
最佳实践配置建议
为实现模型最佳性能,推荐采用以下配置策略:
-
采样参数设置:
- 建议使用 Temperature=0.7、TopP=0.8、TopK=20、MinP=0 的组合。
- 在支持的框架中,可将 presence_penalty 参数调整在 0-2 之间以减少重复生成,但较高数值可能偶尔导致语言混杂现象,并略微降低模型性能。
-
输出长度配置:对于大多数指令任务,推荐设置 16,384 tokens 的输出长度,足以满足 instruct 类模型的常规需求。
-
输出格式标准化:在基准测试场景下,建议通过提示词标准化模型输出格式:
- 数学问题:在提示中加入“请逐步推理,并将最终答案置于 \boxed{} 中。”
- 选择题:在提示中添加 JSON 结构要求以规范响应:“请在
answer字段中仅填写选项字母,例如:"answer": "C"。”
Qwen3-235B-A22B-Instruct-2507 凭借其强大的参数规模、优化的架构设计及丰富的工具生态,正成为开源大语言模型领域的新标杆。无论是学术研究、企业级应用开发还是个人创新项目,该模型都展现出巨大潜力,为 AI 技术的普及与应用拓展提供了强有力的支持。未来,随着技术的不断迭代,其在更复杂场景下的表现值得期待。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







