







A. 问题
首先,对于dense prediction tasks,完全无卷积的的transformer backbone少有人研究。而VIT作为用在图像分类任务的完全transformer结构,很难直接应用于像素级别的dense prediction,例如目标检测与分割。
原因:(1)只有一个尺度的低分辨率输出 (2)内存与计算复杂度限制。
为了解决完全transformer对于dense prediction的限制,提出PVT,与vit相比,
好处(1)输入输出可以更小(4x4, vit是32x32),从而产生高分辨率的输出。(2)提出渐进收缩金字塔结构(progressive shringkin pyramid)显著减少计算量 (3)提出空间减少注意力层,进一步减少计算量(spatial-reduction attention)。
与CNN相比,PVT在每一步的特征提取过程中都考虑了全局感受野。
此外,有一个小问题,作者在介绍vision transformer相关工作的时候,这句话不知如何理解。

B. 方法
(1) 整体结构,有{F1,F2,F3,F4}四个级别的输出。

(2)金字塔结构
不同stage的结构是share的,控制输出的方法如下。

(3)Encoder


提出Spatial-Reduction Attention(SRA)替代MHA,减少计算量。不同之处在于SRA会降低K和V的大小。
C. 实验
(1)分类
1.28million训练,50k验证,1000类。8个V100,300epochs。没说训练时间。
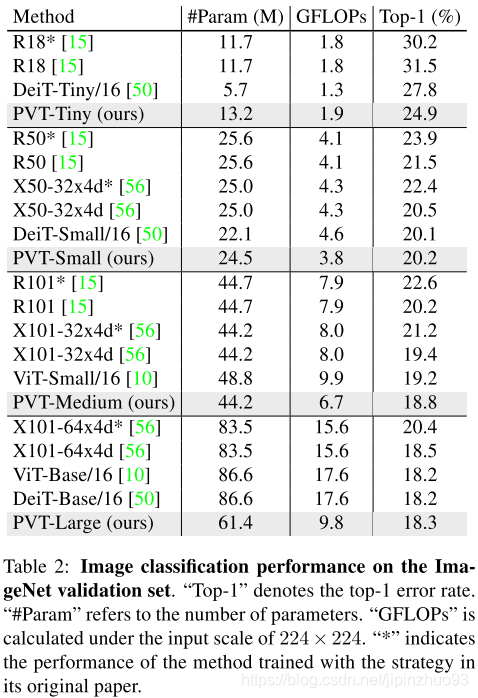
(2)目标检测
COCO train2017数据集 (118kimage),5k验证, 8 v100, batch 16。
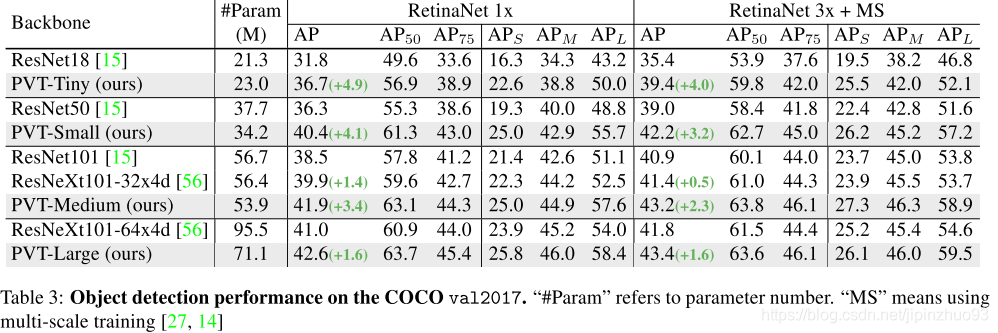
(3)语义分割
ADE20K, 150类,20210张图训练。先在imagenet pre-train。4 v100, batch size 16, 80k循环。
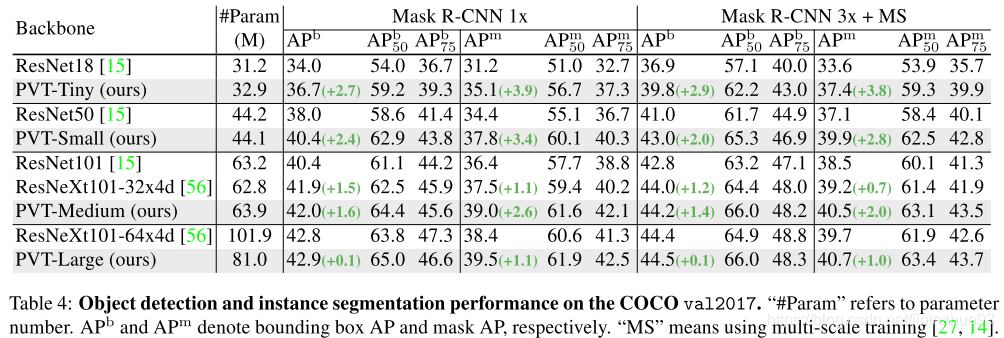
(4)纯transformer(PVT+other transformer完成检测分割)
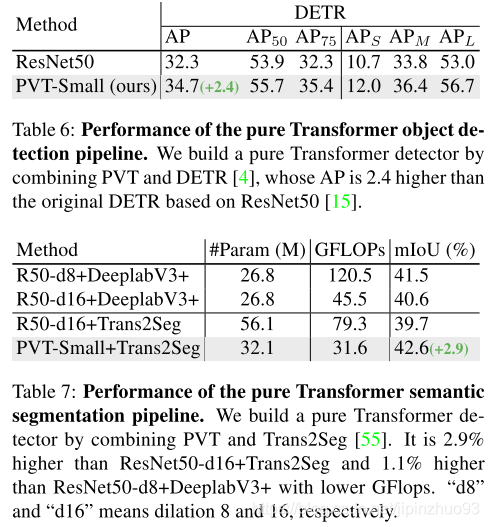
(5)消融实验
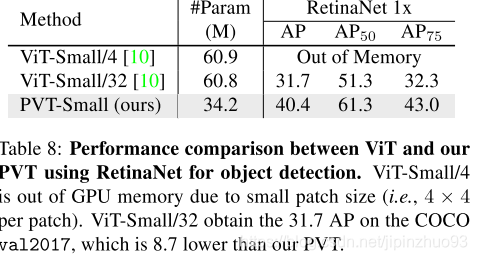
- Pyramid Structure: 4x4 patch效果
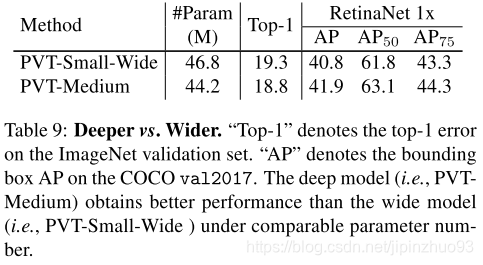
- Deeper vs Wider: deep 更有用
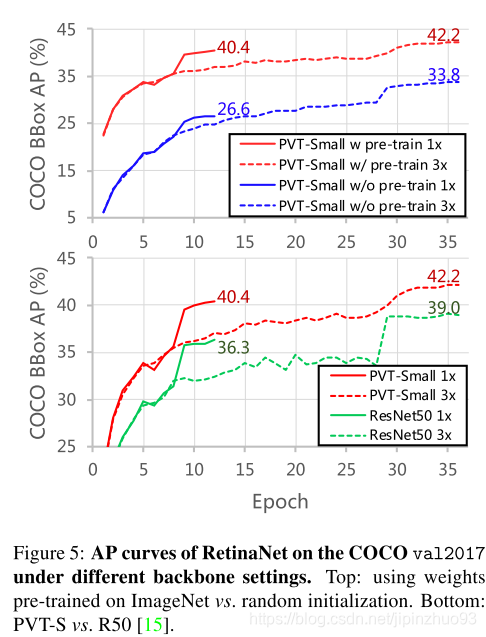
- 预训练
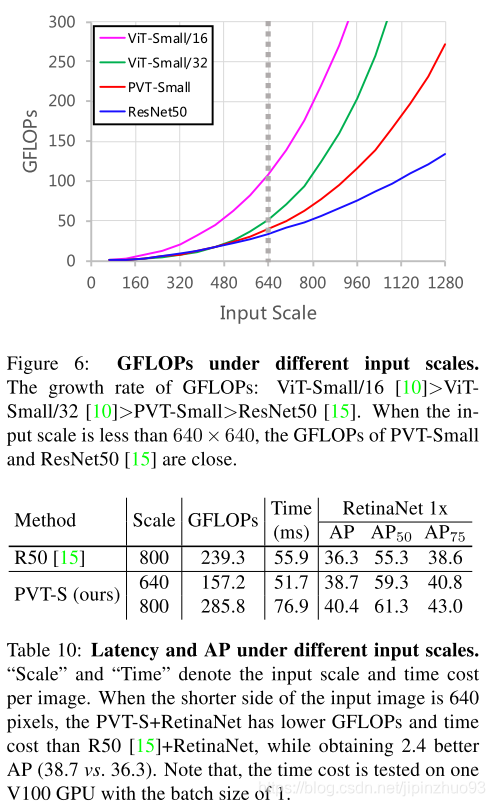
- 计算消耗

















 3723
3723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









