







前言
提示:这里可以添加本文要记录的大概内容:
大型语言模型在处理专业性领域(如法律、医疗等)时受限,并更适用于通用领域。此外,这些模型的数据保密性也较差。因此,解决这些问题的一个好选择是使用本地化的知识库,而 “langchain-ChatGLM” 开源项目可能是一个合适的选项。
提示:以下是本篇文章正文内容,下面案例可供参考
一、dqnapi 是什么
DQNAPI 是一个综合平台,旨在将程序、接口、数据和模型等资源集成到一个统一的环境中。我们为每个资源编写了一个独特的数字标识符,即 DQNAPI 号,用户可以通过这个号码快速查找并访问所需资源。
通过 DQNAPI,您可以方便地注册和管理您使用过的各种资源。无论是程序代码、API 接口、数据集还是模型,只要您注册了相应的 DQNAPI 号,您就可以轻松地回顾和再次使用这些资源。这种整合和统一的方式极大地简化了资源的查找和获取过程,为所有用户提供了更加便捷和高效的体验。
在 DQNAPI 官网,您可以浏览各类资源的详细介绍,并随时搜索和获取您需要的资源。我们不仅提供了齐全的资源库,还为用户提供了交流和分享的平台,让用户们能够互相学习和共享经验。
无论您是开发者、数据科学家还是研究人员,DQNAPI 都将是您不可或缺的伙伴。加入我们,让 DQNAPI 帮助您更好地整合和管理资源,让创新变得更加简单和高效!。
Dqnapi官网
项目langchain-ChatGLM对应dqnapi号:
100.35395/2023.20_v1
模型ChatGLM-6B 对应dqnapi号:100.35395/2023.19_v1
模型text2vec-large-chinese 对应dqnapi号:100.35395/2023.21_v1
二、使用步骤
1.分析原理
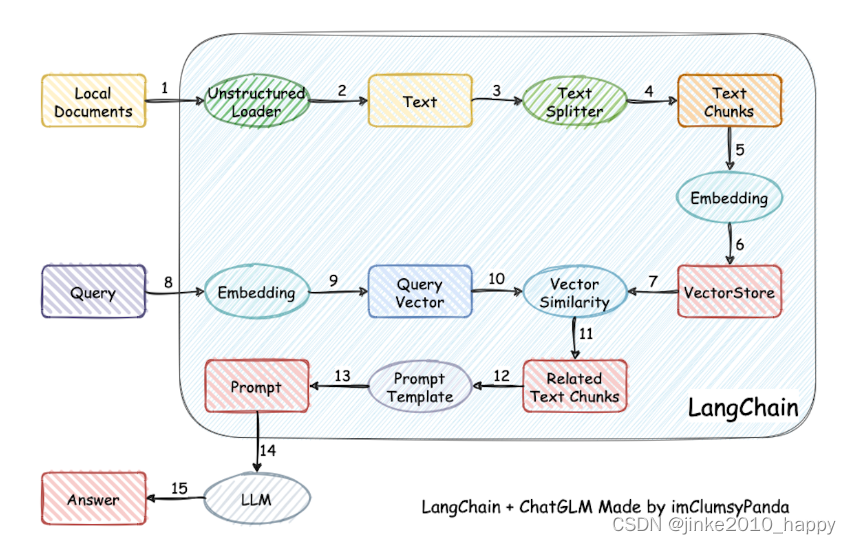
项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
2.下载项目和模型,配置文件
下载项目
详细参考dqnapi号:
[100.35395/2023.20_v1]
下载模型
下载路径可以自定义,后面用的着,我下载的地址分别是
/home/chatglm/text2ve,/home/chatglm/model
详细参考dqnapi号:
[100.35395/2023.19_v1]
详细参考dqnapi号:
[100.35395/2023.21_v1]
安装依赖
cd langchain-ChatGLM
pip install -r requirements.txt
参数调整
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/home/chatglm/text2vec", #本地下载路径
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
"chatglm-6b": {
"name": "chatglm-6b",
"pretrained_model_name": "THUDM/chatglm-6b",
"local_model_path": "/home/chatglm/model",#本地下载路
"provides": "ChatGLMLLMChain"
},
3.下载自己的期刊论文知识库
4.启动项目
pip install gradio
python webui.py
总结

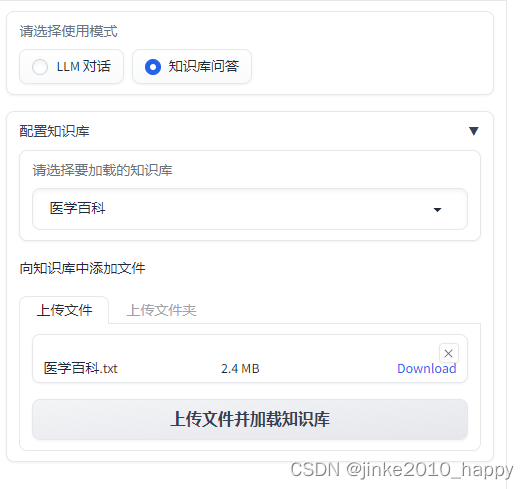
看到配置文件中有很多大语言模型,看来langchain只是一个大语言模型的交互框架,后面感兴趣的小伙伴可以采用尝试其它模型,另觉得模型比较丑的可以搜索相关的前台调用项目,后台可以 用该知识库的api接口

















 2968
2968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









