




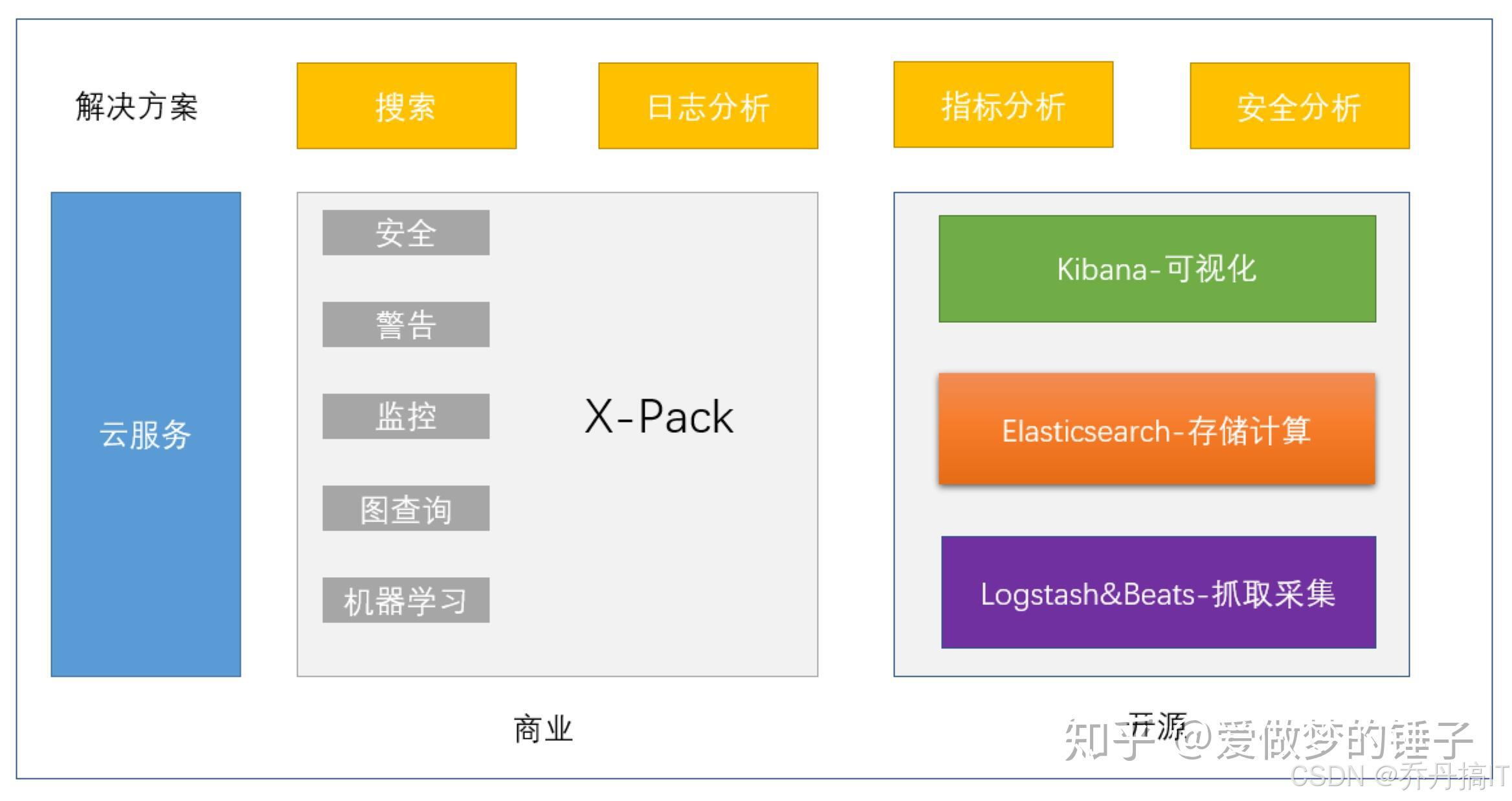
0.2 Elasticsearch 在 Elastic Stack 中的定位
如果把 Elastic Stack 比作一台分布式日志与搜索机器,那么 Elasticsearch 就是这台机器的“发动机 + 硬盘 + 索引器”三合一组件。它既负责把原始数据变成可检索的结构化信息,也负责把计算结果以毫秒级延迟返回给上游,同时还是整个集群状态的唯一持久化载体。换句话说,Elasticsearch 不只是一颗“搜索心脏”,更是 Elastic Stack 的元数据、配置、监控、告警、机器学习模型乃至 UI 状态的唯一真相源(Single Source of Truth)。
1. 数据平面:唯一可写端点
Beats、Logstash、APM Server、Kibana 的 Ingest Manager 最终都把数据推送到 Elasticsearch 的 _bulk API。整个 Stack 没有任何第二个组件能够持久化文档,因此 Elasticsearch 天然成为数据平面的“终点”。这种设计带来两个直接后果:
- 背压统一:Logstash 的背压、Beats 的背压、Kafka 缓存的背压,最终都表现为 Elasticsearch 写入队列的堆积。只要监控
_cat/thread_pool/write?v,就能判断整个采集链路的健康度。 - Schema 仲裁:Elasticsearch 通过 dynamic mapping 决定了字段类型,一旦字段类型固化,上游组件无法“反悔”。因此索引模板、component template、data stream 的配置权必须集中在 Elasticsearch 层,而不是 Logstash 或 Beats。
2. 控制平面:集群状态 = Stack 状态
Kibana 的 Stack Management、Security、Watcher、Transform、SLM、ILM 等子系统,全部把配置写进 .kibana*、.security*、.watches* 等系统索引。这意味着:
- Kibana 自身无状态:重启 Kibana 节点时,只需重新加载 Elasticsearch 中的 Saved Object,无需本地恢复。
- 多 Kibana 实例自动同步:所有 Kibana 实例共享同一份
.kibana索引,因此不会出现配置漂移。 - 备份即“全栈”备份:用 SLM 对 Elasticsearch 做一次 snapshot,等于把 Kibana 的仪表板、告警规则、机器学习作业、安全角色一并备份,恢复时零额外操作。
3. 查询平面:毫秒级网关
无论用户通过 Kibana 的 Discover、Lens、Dashboard,还是通过 APM UI、Uptime、Maps,甚至通过 Machine Learning 的 Anomaly Explorer,最终都被翻译成一组 Elasticsearch 查询:
- 聚合入口:Kibana 的 Visualization 100% 依赖 Elasticsearch 的 Aggregation DSL;Lens 的公式函数只是 DSL 的语法糖。
- 列存加速:
keyword、numeric、ip、geo_point等字段默认启用 doc_values,Kibana 的排序、透视表、地图热力图直接走列存,不打开_source,因此即席查询可压到百毫秒级。 - 跨集群搜索(CCS):Kibana 在 7.8+ 支持“跨集群仪表板”,其底层就是 Elasticsearch 的
cluster:*远程别名机制,Kibana 本身不做二次合并。
4. 安全平面:单点登录与字段级授权
Elastic Stack 的认证链完全内置于 Elasticsearch:
- Realm 链:Native、LDAP、AD、PKI、SAML、OIDC、Kerberos 依次尝试,成功即返回
_security/oauth2/token;Kibana 只是把这个 token 放进 Cookie。 - 字段级安全(FLS)与文档级安全(DLS):在查询阶段由 Elasticsearch 的
SecurityServerInterceptor直接重写 DSL,Kibana 无法绕过;因此哪怕用户通过 Dev Tools 手工发请求,也只能看到被授权的数据。 - API Key 聚合:Beats、Logstash、Agent 使用的 API Key 实体保存在
.security索引,支持在 Kibana 的“安全”界面一键吊销,生效时间 <1s。
5. 可观测性平面:Metrics + Logs + Traces 三栈合一
从 7.14 开始,Elastic Agent 把主机指标、日志、APM Trace 全部写入 data stream:
- 统一 Schema:
metrics-*-*, logs-*-*, traces-*-*都遵循 Elastic Common Schema (ECS),因此可以在 Kibana 的 Observability 一键切换“主机”、“日志”、“链路”、“用户体验”视图,而无需重新建索引。 - 内置 ILM:Elasticsearch 提供 90 天 hot-warm-cold-frozen 策略,Kibana 的 Index Management UI 直接可视化每个 phase 的段大小、merge 次数、查询延迟。
- Profiling 数据:Even-node Java Flight Recorder 数据以
profiling-*写入 Elasticsearch,Kibana 的 Universal Profiling 利用binary字段 +constant_keyword实现 10TB 级火焰图秒级跳转。
6. 机器学习平面:模型与结果同库
机器学习作业(Anomaly Detection、Data Frame Analytics、NLP 推理)把模型分片、状态、结果全部保存在 .ml-* 索引:
- 模型分片:每个 detector 的
model_state以 base64 存入.ml-state-000001,实现节点故障时快速重分配。 - 推理入口:NLP 的
trained_model通过_ml/trained_models/_infer暴露,Kibana 的“机器学习”界面只是调该 API;因此任何第三方系统只要持有角色machine_learning_admin即可直接调用,无需经过 Kibana。 - Security 继承:如果用户对索引
nginx-logs无读权限,则即使他拥有machine_learning_admin角色,也无法在该索引上创建 datafeed,确保“看不到数据就建不了作业”。
7. 版本耦合边界:Elasticsearch 是“最慢变量”
Elastic Stack 的官方矩阵强制要求:
Kibana minor == Elasticsearch minor
Beats/Agent/Logstash minor >= Elasticsearch minor
这意味着:
- 升级火车头:只要 Elasticsearch 版本升级,整个 Stack 必须跟着走;反过来,Kibana 或 Beats 可以热升级,但 Elasticsearch 不能降。
- REST 兼容性:Elasticsearch 在 8.x 提供
?compatible-with=7参数,让 7.x 客户端无需修改即可接入,确保 Stack 组件平滑滚动。
8. 小结:把 Elasticsearch 当作“操作系统”
在 Elastic Stack 里,Elasticsearch 的角色已超越“搜索引擎”:
- 它是分布式文件系统(快照仓库 + searchable snapshot)
- 它是元数据存储(Kibana、Agent、Security、ML 配置)
- 它是计算引擎(聚合、SQL、ES|QL、ML 推理)
- 它是网关(SQL JDBC、ODBC、CCS、Async Search)
因此,规划 Elastic Stack 时,先把 Elasticsearch 当作“操作系统”去设计:
- 用 data stream + ILM 把“索引即文件”理念落地;
- 用角色 + API Key 把“权限即内核能力”落地;
- 用 snapshot + SLM 把“备份即系统镜像”落地;
- 用 dedicated master、dedicated data、dedicated ml 节点把“进程隔离”落地。
只要 Elasticsearch 层足够健壮,Kibana 和其他组件就可以像用户态程序一样随时重启、横向扩展、甚至短暂下线,而整个 Stack 的数据和配置不会出现任何单点失效。
更多技术文章见公众号: 大城市小农民



















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











