




代码示例:
0.1 Elasticsearch-为什么要用搜索引擎而不是数据库
把搜索需求直接丢给 MySQL,在数据量刚过百万行时就“全线飘红”——CPU 飙高、IO 打满、响应从毫秒级跌到秒级。这不是 DBA 调优不到位,而是关系型数据库的基因决定了它只能“逐行过滤”,无法像搜索引擎那样“倒排定位”。Elasticsearch(ES)之所以成为现代系统的“第二条存储主干道”,本质是把“查”这件事从磁盘回表+BT 扫描的泥潭里拉出来,放到内存倒排+分布式并行的新赛道。下面从四个维度拆解“为什么用 ES 而不是数据库做搜索”。
1. 数据模型:表格 vs 文档
- 数据库的范式表把对象拆成多表,再做 JOIN;搜索场景却需要“一次拿回整棵对象树”。ES 的 JSON 文档天然自包含,字段可以任意增减,无需 DDL,也不会产生稀疏列。
- 字段类型同时保留“文本”与“关键字”双视图:text 分词后入倒排,用于全文;keyword 原值入 BKD,用于排序聚合。一份数据两份索引,数据库必须手动建两个列+两个索引,变更成本极高。
2. 索引结构:B+Tree vs Inverted Index
- B+Tree 只能回答“=、>、<”这类确定性问题,遇到“包含”“相似”“前缀”就只能全表扫描;而倒排表直接给出“词→文档列表”的映射,复杂度 O(1) 级别。
- ES 在倒排之上再加一层“跳表+Bitset 缓存”,对 and/or/not 布尔查询做交集、并集、差集时走的是内存位运算,轻松扛住十万 QPS;同复杂度在 MySQL 里等于几十万行的 filesort,CPU 瞬间爆表。
3. 查询语义:SQL 全文“伪功能” vs 搜索引擎“原生能力”
LIKE '%手机%'无法利用索引,且大小写、简繁、同义词、拼音、错字一律认不出;ES 内置 ik、jieba、whitespace 等多语言分词器,同时支持- Fuzzy:允许 Levenshtein 编辑距离≤2 的拼写容错;
- Phrase + Slop:保持词序,允许中间插入 N 个词;
- Synonym:行业同义词一键展开;
- Highlight:直接返回高亮片段,无需业务层再做正则替换。
- 聚合方面,一条 DSL 就能完成“先按品牌分组,再算价格百分位,再按地域子聚合”这样的多维分析;在数据库要写多层嵌套子查询+临时表,执行计划极易走偏。
4. 规模与实时性:单节点 vs 分布式
- 数据量突破单机内存后,数据库只能“垂直升级”,CPU 核数与磁盘 IOPS 线性比价钱包不住;ES 把索引拆成 shard,shard 再按 replica 横向复制,加机器即可线性扩容。线上 200 节点、PB 级日志集群并不少见。
- 写入链路采用“内存 buffer → refresh → segment → merge”三级缓冲,默认 1 秒级可见,既保证近实时,又避免 Lucene 的小文件灾难;数据库若用事务表+全文索引,每次 commit 都要刷盘重建倒排,写放大惊人,实时性也只能到分钟级。
5. 成本与生态:License & Stack
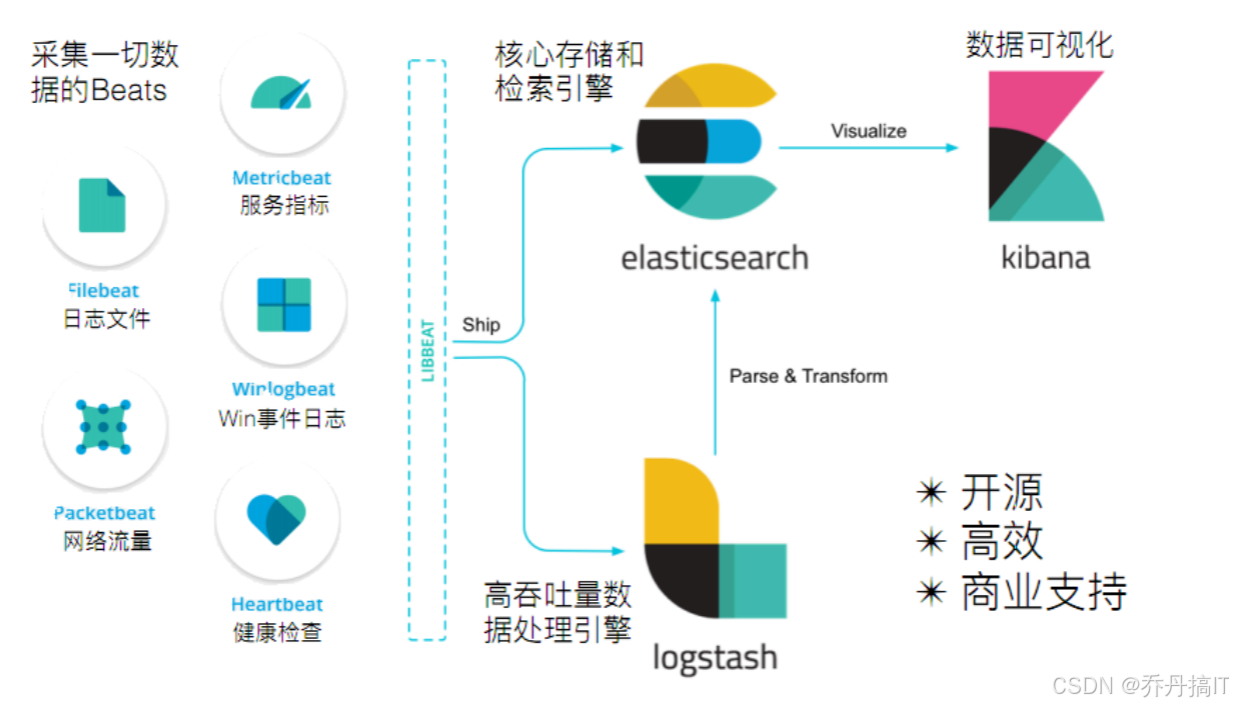
- ES 开源版免费,配合 Beats/Logstash/Kibana 形成采集→存储→可视化闭环;商业数据库的全文组件往往要额外授权,且可视化工具再收一次费。
- 云厂商提供的托管 ES 支持 Serverless 弹性,高峰自动扩容,低峰缩到 0,对比自建 MySQL+代理+读写分离,运维人力与机器成本至少节省 40%。
6. 边界与误区
搜索引擎不是银弹:
- 不支持跨行事务,写后读只能保证“最终一致”;
- 复杂多表关联要靠宽表预拼或 application-side join;
- 深分页(>1 万)仍要走 scroll/search_after,内存压力不可忽略;
- 字段过多会爆炸式增加倒排和 docvalue,需开启
index: false与doc_values: false做裁剪。
因此业界常规做法是“主数据存关系型/NoSQL,搜索需求实时同步到 ES”,让两者各施所长:前者保证事务与一致性,后者负责海量检索与实时分析。
结论
当业务场景出现“关键字+多字段+高并发+实时聚合”任意组合时,数据库的 B+Tree 模型就已经触及天花板;把搜索逻辑迁到 Elasticsearch,用倒排索引、分布式 shard、内存位运算与丰富的 DSL,一条 20 ms 的查询就能返回十万条结果并附带高亮和统计。与其在数据库上反复“拆表、加索引、升配机器”,不如直接让专业引擎做专业事——这正是在大数据时代给架构做减法的核心思路。
更多技术文章见公众号: 大城市小农民



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











